For modern cloud database services, compute-compute separation provides a powerful approach to optimizing database performance and resource management by isolating compute resources for specific workloads, users, or business functions. Unlike traditional resource-sharing models, this method allocates dedicated compute instances to different types of database operations—such as reads and writes—reducing the risk of interference between them. This setup is particularly beneficial in high-demand environments, where fluctuating workloads might otherwise affect query speed and reliability.
In this post, we announce the introduction of compute-compute separation in ClickHouse Cloud, explain its significance, and, most importantly, highlight what it means for our users.
What is compute-compute separation? #
Compute-compute separation in a database refers to the ability to allocate dedicated compute resources for different users, workloads, or operation types, ensuring they do not interfere with one another. By isolating compute resources, we can guarantee that the performance and stability of a query will not be impacted by another workload. While similar outcomes can be partially achieved with quotas and limits, this approach has limitations and lacks the flexibility and guarantees provided by compute-compute separation.
Effectively this means users can have different pools of isolated compute, reading and writing the same data but dedicated to different tasks.
Why is this useful? #
Such separation is extremely useful in the following scenarios:
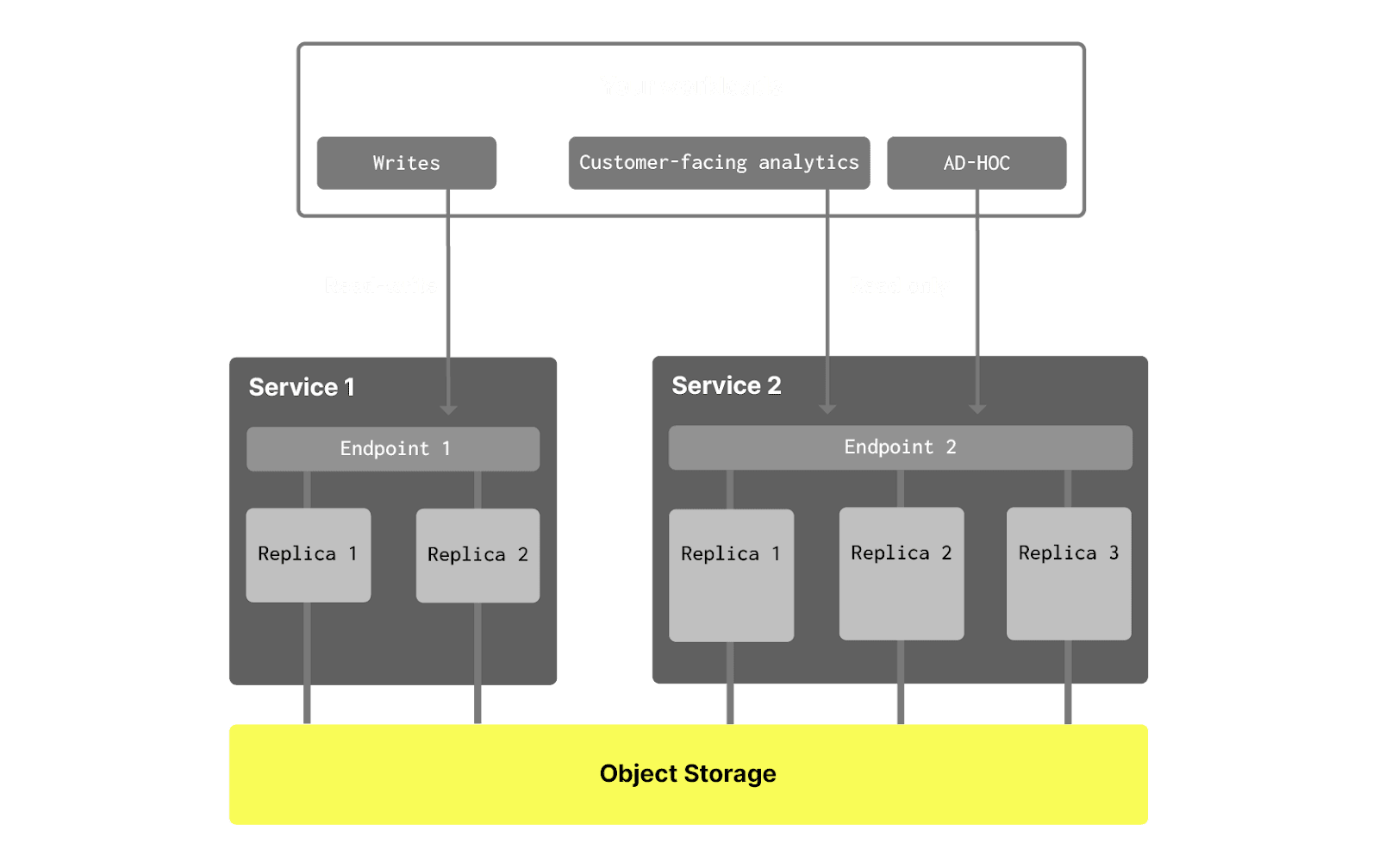
1. Separating writes and reads #
In some use cases write operations can be extremely sensitive to query execution time. In these scenarios, other queries in the database should not affect the execution time of INSERTS and UPDATES. This is especially hard to achieve if there are ad-hoc queries in the database submitted by users directly or via BI tools. Such queries can be inefficient, contain mistakes that lead to huge resource consumption, and affect other queries in the database.
With compute-compute separation, we can allocate dedicated compute resources to the most critical workload - such as INSERT operations - ensuring their performance remains unaffected by other queries. In some cases, specific read operations may be more critical than writes. In such scenarios, these operations are also assigned to separate compute resources, following the same underlying logic.
2. Providing dedicated compute resources to different teams and functions #
Large companies can have tens or hundreds of teams and departments accessing the same data in a database or a data warehouse. Some teams may require different performance levels when accessing the same data and prefer not to share compute resources with others, as shared resources can lead to inconsistent query performance.
Additionally, these teams often wish to separate their database usage costs for accountability and budgeting purposes.
In this scenario, compute-compute separation provides multiple benefits:
- Isolating the workloads of different teams, so their queries do not impact each other’s performance.
- Providing different compute size and idling settings to each team, allowing them to choose the optimal compute size and cost that suits their specific needs.
- Providing separate billing for each team enabling clear visibility into the cost of their queries, especially if they have idling enabled.
3. Providing different HA level for different workloads #
Some workloads are extremely critical while others can tolerate lower uptime to reduce costs. For example:
- End-user product charts and visuals should have the highest availability, so they should use three availability zones. Such queries can be quite simple, however, and do not demand significant CPU and RAM
- ETL/ELT queries are important and resource intensive, but they can be retried automatically if failed. Therefore, it is acceptable to allocate only two nodes across two availability zones for these workloads.
- Finally, there may be heavy ad-hoc queries, such as complex star schema joins, that require significant memory and are executed manually by an analyst. Since this person only works during the working hours (5x8), their compute resources can be idled when they are inactive. Furthermore, they can tolerate occasional query failures if a node goes down briefly. In such cases, a single node in one availability zone should suffice.
In this scenario, compute-compute separation ensures that each workload receives isolated compute resources and achieves its desired level of high availability. Additionally, it enables cost separation for different teams using the same database.
Introducing Warehouses #
In ClickHouse Cloud each database instance includes:
- A group of ClickHouse nodes (or replicas) - depending on availability settings an instance can consist of 1 or more nodes.
- An endpoint (or multiple endpoints created via ClickHouse Cloud UI console) with a service URL that you use to connect (for example,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443). - An object storage folder where the service stores all the data and partially metadata.
- A keeper instance, usually containing three nodes:
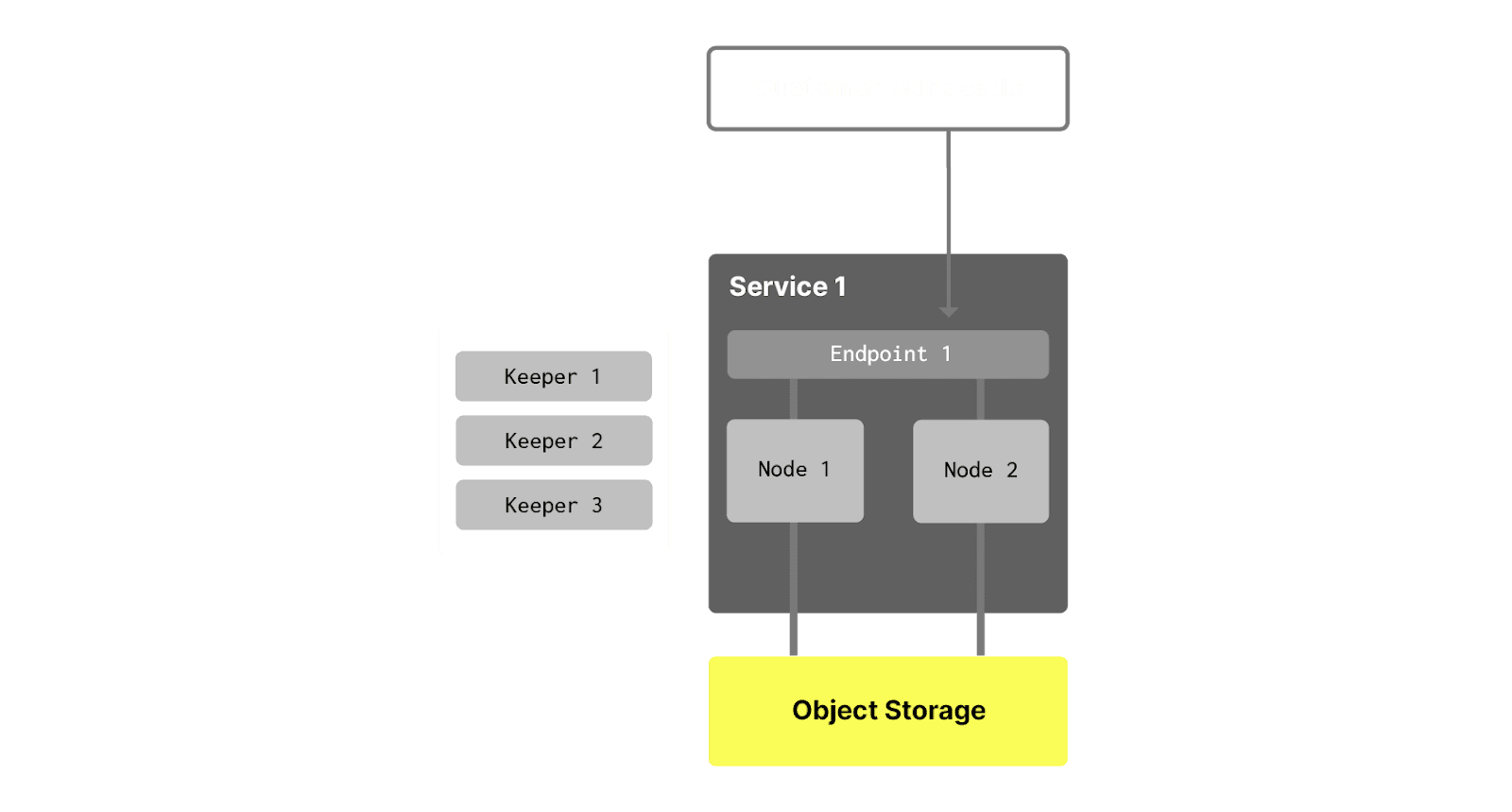
Now, we are introducing Warehouses. A warehouse is a set of services that share the same data - tables, views, functions, etc. Each warehouse has a primary service (this service was created first) and secondary service(s). For example, here is a warehouse containing two services:
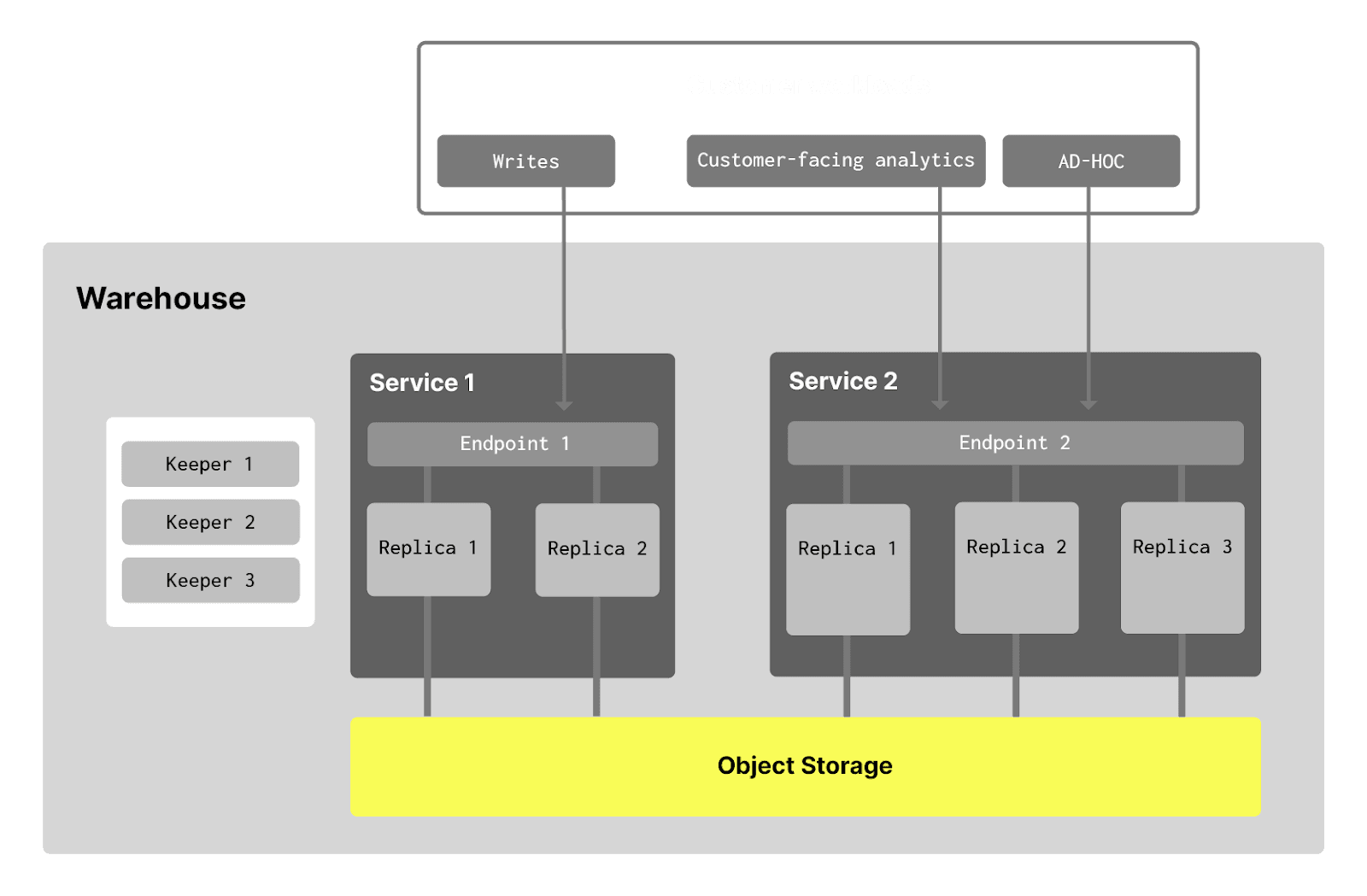
Each service in such a warehouse has its own:
-
Endpoint - so you can adjust which of your workloads, BI tools and ETL/ELT systems use which set of nodes.
-
Compute nodes - so your workload will not interfere with each other. That also means that you can scale your services separately. For example, you can independently:
- Adjust the number of nodes per service
- Adjust the size of the nodes in GiB of RAM, with larger instances also having a higher number of vCPUs.
- Set up idling for services
- Our Enterprise tier customers can even select different CPU/RAM ratios per service! Some workloads require more CPU for compression/decompression, while others need more memory for more complex queries. Now, these two workloads can be separated.
-
Network access settings - so you can restrict your apps and users from accessing specific services
The following are common for all services in a warehouse:
- Data - all services work with the same data. That means, a regular SELECT query will return the same data if you run it on different services in a warehouse
- Keeper instances - as keepers help to coordinate and replicate the data across nodes, all services that use the same data have a shared keeper cluster.
- Backups - obviously, we do not want to back up the same data from multiple services. We, therefore, backup the data on the primary service only (the service in a warehouse that was created first).
- For now, all services in a warehouse should have the same:
- Cloud Service Provider (AWS, GCP or Azure)
- Region
- ClickHouse Database version
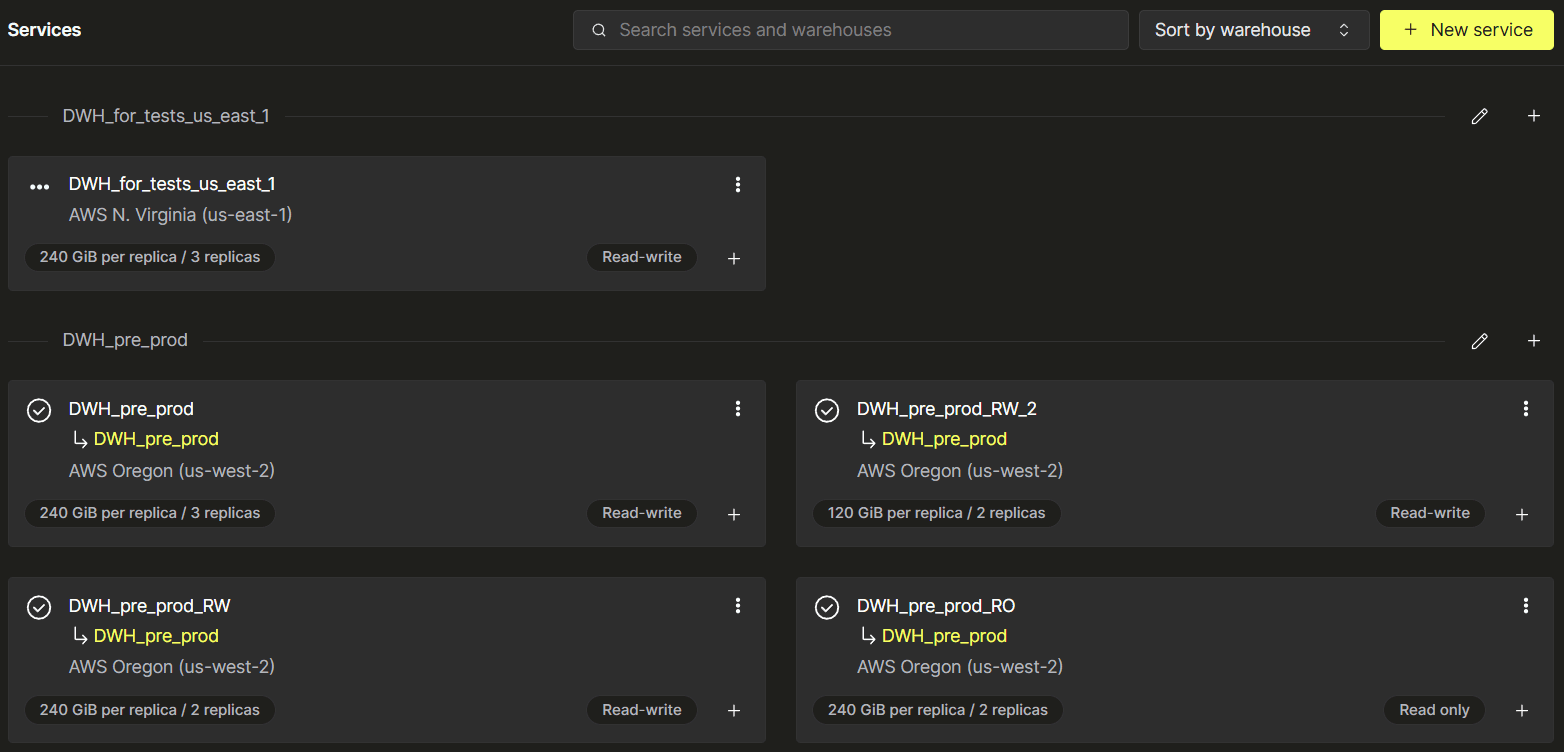
From the UI perspective, when the first warehouse with more than two services is created, all services belonging to a single WH are grouped together. In the example below, we have two warehouses:
DWH_pre_prodhas four servicesDWH_for_tests_us_east_1has only one service:
Under the hood #
In order to achieve compute-compute separation, we needed to tackle mainly two problems. The first being the data synchronization between different compute groups. The second is to ensure the query workload respects the service boundaries, and doesn’t use resources belonging to another service within the same warehouse.
Two important architectural decisions in ClickHouse Cloud help us achieve data synchronization efficiently. Firstly, we use separation of storage and compute architecture. This established an important foundation for compute-compute separation by sharing the same data in cloud provider storage, such as S3, allowing quick data synchronization between different services. Also, for table schema and metadata synchronization, the SharedMergeTree table engine is leveraged to achieve a lightweight metadata synchronization in the shared keeper fleet.
To implement compute separation, we utilize the replica-group concept in the Replicated database. This approach ensures that for distributed queries or parallel replicas, the load is contained within each replica group, limiting resource sharing to only the services within that group. This prevents the consumption of additional resources from other services within the same warehouse, maintaining isolation and efficiency.
With these technical foundations in place, we are well prepared to support compute-compute separation. In order to fully support compute-compute separation, we also made the following changes:
- We monitor different services within a warehouse separately. This allows us to idle and auto scale services independently.
- We enforce warehouse level networking isolation and storage isolation for security.
- We enforce database synchronization among different services within the same warehouse.
- We disable merges and inserts queries in read-only services to ensure background jobs (e.g. for mutations) don't impact the performance of read-only services (see section "Background operations" for details).
Database credentials #
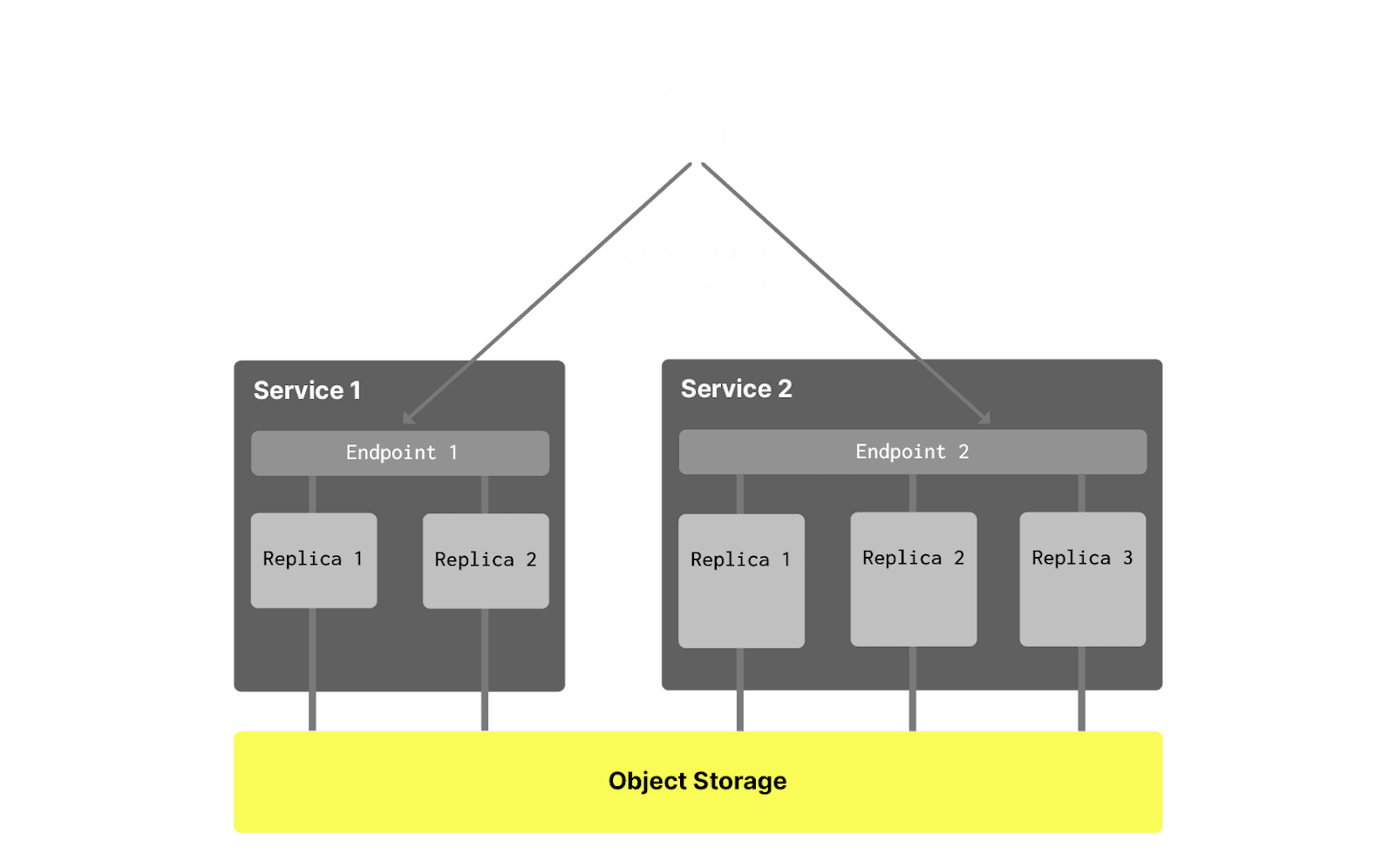
Because all services in a warehouse share the same set of tables, they also share access controls (grants) and users/roles. This means that all database users that are created in "Service 1" will also be able to use "Service 2" with the same permissions (grants for tables, views, etc), and vice versa. Users can use another endpoint for each service but will use the same username and password. In other words, users are shared across services in a single warehouse:
Network access control #
However, it is often useful to restrict specific services from being accessed by other applications or ad-hoc users. This can be achieved through network restrictions, configured similarly to how they are currently set up for regular services. To apply these restrictions, navigate to Settings in the Service tab of the specific service within the ClickHouse Cloud console.
You can apply IP filtering settings to each service separately, allowing you to control which application and users can access which service:
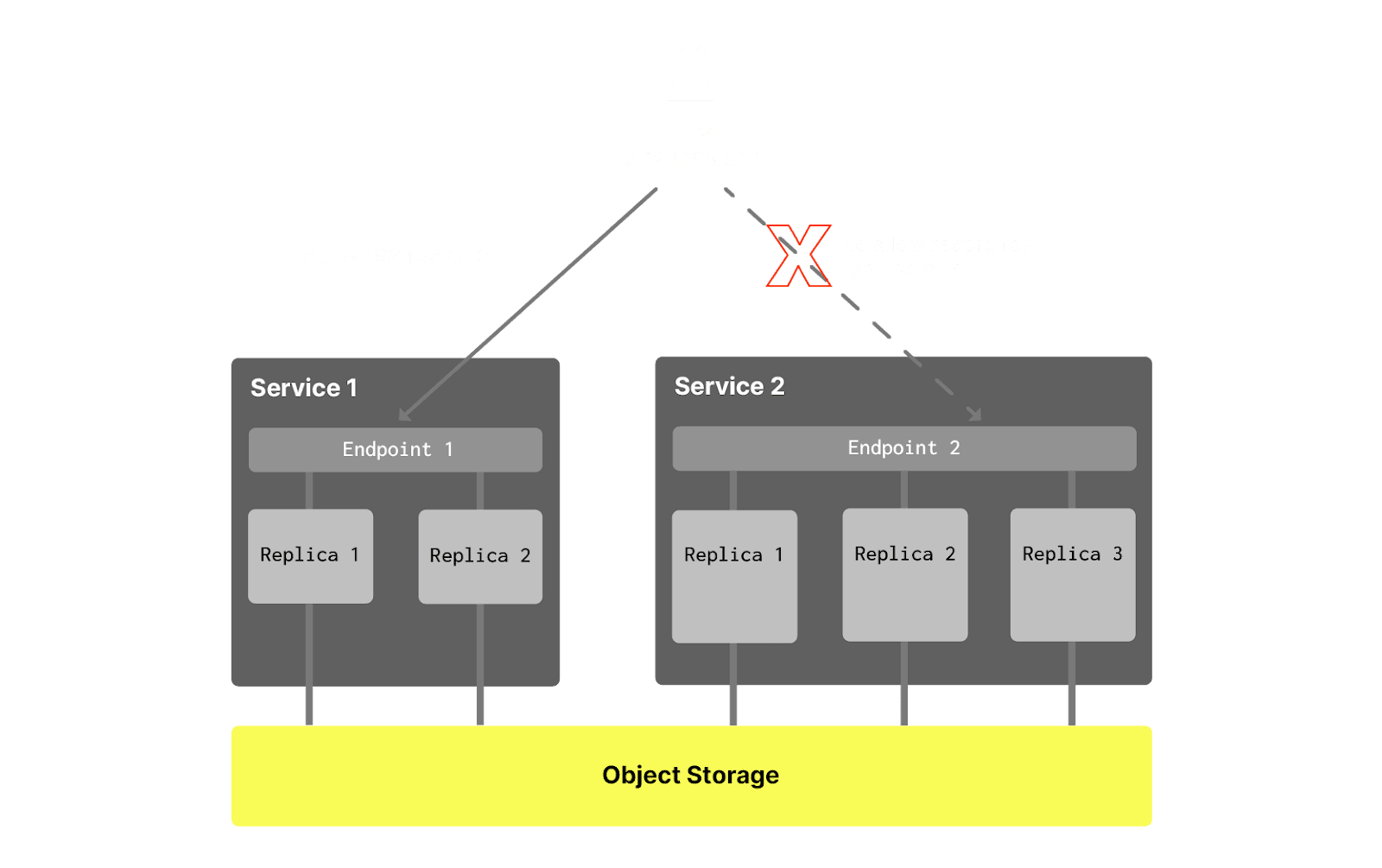
Read vs read-write #
Sometimes it is useful to restrict write access to a specific service and allow writes only by a subset of services in a warehouse. This can be done by creating any service except the first service as read-only (the first service should always be read-write):
Background operations #
ClickHouse performs several resource-intensive operations in the background, such as merging parts after data inserts. The database then merges these parts in the background, a process that can consume significant memory and CPU resources.
To achieve full compute-compute isolation, we allowed only read-write services to perform background operations. This means that when you dedicate a read-only service for a critical read workload, you can be sure that reads will not be affected by merges.
However, with multiple read-write (RW) services, any of them can perform background merges for INSERT queries initiated on any of the services. This is because merges are not directly tied to the queries that triggered them. As a result, in rare cases, heavy write operations may impact each other, even when executed on different services. In the future, we plan to introduce a specialized setting that will enable users to control which RW services handle background operations and distribute these operations among RW services based on the queries that caused them.
Warehouses limitations #
Though warehouses bring a lot of flexibility to ClickHouse Cloud, there are a few limitations that are presented in the current implementation and that we plan to remove later:
-
The first service in the warehouse should always be up and should not be idled. You cannot stop or idle the first service if there is at least one secondary service. Once all secondary services are removed, you can stop or idle the original service again.
-
As described, all read-write services perform background merge operations. This means that there can be a situation where there is an INSERT query in Service 1, but the merge operation is completed by Service 2. In short, this means that the workload from one RW service can affect the performance of another RW service. Note that read-only services do not execute background merges, so they don't spend their resources on this operation. Consider using a single RW service for ingestion and transformations, and RO services for other needs.
-
Inserts in one read-write service can prevent another read-write service from idling if idling is enabled. Because of the previous point, a second service can perform background merge operations for the first service. These background operations can prevent the second service from going to sleep when idling. Once the background operations are finished, the service will be idled. Read-only services are not affected and will be idled without delay.
-
CREATE/RENAME/DROP DATABASE queries could be blocked by idled/stopped services by default, causing these queries to not complete. To bypass this, you can run database management queries with the
settingat the session or query level. For example:distributed_ddl_task_timeout=0
1create database db_test_ddl_single_query_setting
2settings distributed_ddl_task_timeout=0
Customer feedback #
Before releasing warehouses, we launched a private preview program for a subset of our customers so they can test it in real production workloads. These are a few pieces of feedback from these users:
"We have a smaller dedicated primary cluster for writes only that is isolated from the main bigger cluster for reads. Then we have an ad hoc cluster which goes to sleep when not in use. Ad hoc has been fantastic as it allows users to run whatever inefficient query they want without impacting production"
Beehiiv.com
"So far it’s been working great! We had some extra load on the primary service this week and were able to send traffic to the secondary service to keep customer facing queries fast."
CommonRoom.io
"Just wanted to drop a note and say thank you on the above. We are now running compute-compute in production along with `query_cache` and `allow_experimental_analyzer`, `allow_experimental_parallel_reading_from_replicas`. With this new setup we are in a new dream world."
Vantage.sh
"Compute-compute separation gives satisfaction. From the experimentations, our regular compute task now takes something like 30 seconds, against 30 minutes currently in BigQuery, because we now can separate workloads."
ABTasty.com
"What used to take 8 hours now takes 30 minutes or less. No noticeable impact on the other services. A+ feature."
Cypress.io
Get started now! #
This blog describes how compute-compute is helping ClickHouse Cloud customers achieve better tenant isolation and optimize their overall resource consumption and costs.
To experience warehouses in ClickHouse Cloud as a new customer, start a free $300 trial here. As an existing customer, follow the in-product prompts to migrate an existing deployment to one of the new tiers that supports warehouses and refer to this FAQ for any questions.



