TL;DR
· On identical hardware and data, ClickHouse is up to 4,000× faster on bulk UPDATEs, reaches parity on single-row updates, and stays competitive on cached point updates.
· Why it matters: Bulk updates are common in OLTP workloads, and ClickHouse’s columnar design + parallelism make them far faster.
· Caveat: PostgreSQL is fully transactional by default; ClickHouse isn’t. Results reflect native execution models, not identical guarantees.
PostgreSQL is the most popular open-source OLTP database in the world.
It’s a fair assumption that, when a developer thinks about UPDATE performance, they probably think of the baseline that PostgreSQL sets.
In contrast, ClickHouse is the most popular open-source OLAP database in the world.
While ClickHouse sets the expectation of OLAP performance, its OLTP potential is often underrated.
In July 2025, ClickHouse v25.7 brought high-performance SQL-standard UPDATEs to ClickHouse.
Naturally, we want to know how ClickHouse stacks up against the best. Are UPDATEs in ClickHouse competitive with UPDATEs in Postgres?
In this post we first look at cold runs, the stress-test scenario where no data is cached, and then complement them with hot runs, which better reflect everyday workloads where indexes and cache hit rates are high.
Comparing PostgreSQL and ClickHouse isn’t apples-to-apples #
In our previous post, we benchmarked the new high-performance SQL-standard UPDATEs against other ClickHouse update methods. Here, out of curiosity, we’re running the same benchmarks against PostgreSQL on identical hardware and data.
We focus on two OLTP staples: single-row updates and bulk changes on a classic orders dataset. These tests reveal how much update speed depends on finding rows efficiently, a strength ClickHouse inherits from its analytical roots.
Before diving into the numbers, we want to acknowledge something: a PostgreSQL vs. ClickHouse comparison isn’t apples-to-apples.
Both can run UPDATEs, but their execution models differ in ways that matter when interpreting results.
TL;DR: PostgreSQL wraps every statement in a fully transactional context and flushes WAL at commit by default; ClickHouse doesn’t. That means these results aren’t a perfect measure of transaction or durability performance. However, they’re still an interesting and relevant look at how each system handles update workloads under its native execution model.
PostgreSQL and ClickHouse may both run UPDATE statements, but they don’t do it the same way. They share a similar approach to isolation, both use Multi-Version Concurrency Control (MVCC), but differ in how they handle transactions, commit semantics, and durability guarantees.
This difference matters when interpreting benchmark results.
Multi-Version Concurrency Control (MVCC) #
Both PostgreSQL and ClickHouse use MVCC to let readers and writers work in parallel without blocking each other. Every query sees a consistent snapshot of the data as it existed when it started, which means:
-
Readers never see partial changes from concurrent updates.
-
Readers and writers don’t block each other.
-
Data is never overwritten in place; new versions are created, and old ones are kept until no query needs them.
How this looks in practice:
PostgreSQL
-
Creates a new row version with the updated data.
-
Keeps the old version until all readers of the old one finish.
-
Removes old versions later via VACUUM.
ClickHouse
-
Keeps old data parts until all readers of the old one finish.
-
Merges updates into the source data part during a background merge and discards old versions.
On isolation alone, PostgreSQL and ClickHouse behave very similarly; both ensure readers always see a consistent snapshot while updates are in flight.
Transactions, commit, and rollback #
Here’s where the paths diverge:
PostgreSQL
-
Runs every statement, even a single UPDATE, inside a transaction context.
-
If you don’t start one, it still wraps the statement in an implicit transaction (BEGIN → execute → COMMIT).
-
Writes all changes to the Write-Ahead Log (WAL) before touching the table for durability and crash recovery.
-
COMMIT makes changes visible; ROLLBACK discards them before commit, marking old row versions invalid for later cleanup.
ClickHouse
-
Single inserts and updates on a MergeTree table are atomic, consistent, isolated, and durable, applied as a whole, if they are packed and inserted as a single block.
-
By default, it doesn’t wrap every statement in a transaction.
-
Supports experimental multi-statement transactions with explicit BEGIN, COMMIT, and ROLLBACK (not yet in ClickHouse Cloud).
PostgreSQL is fully transactional by default, adding per-update-statement overhead. ClickHouse avoids extra bookkeeping unless you explicitly start a transaction (experimental feature, not yet in ClickHouse Cloud).
Durability and flush policy #
Here’s where the systems differ again, this time in how they guarantee durability and handle flushes to disk.
PostgreSQL:
-
fsync=on,synchronous_commit=onby default → WAL is flushed to disk at every commit. -
Adds latency but guarantees durability even if the OS crashes.
ClickHouse:
-
fsync_after_insert=falseby default → relies on OS page cache, parts are atomic but not immediately flushed. -
Faster inserts/updates, weaker immediate durability; you can enable
fsync_after_insert = 1for stronger guarantees.
Implication for benchmarks: Results reflect the default durability/flush settings. You can shift absolute times by changing these knobs, but the relative patterns (row vs. column update costs) dominate.
With the key execution model differences in mind, let’s look at how we put both systems to the test.
Dataset and benchmark setup #
In our previous blog on fast updates in ClickHouse, we walked through the dataset, schema, and setup in detail. Here’s a quick recap of the essentials so we can focus on the new ClickHouse–PostgreSQL comparison.
Dataset #
We use the TPC-H lineitem table, which models items from customer orders. This is a classic OLTP-style scenario for updates, as quantities, prices, or discounts might change after the initial insert.
ClickHouse #
CREATE TABLE lineitem ( l_orderkey Int32, l_partkey Int32, l_suppkey Int32, l_linenumber Int32, l_quantity Decimal(15,2), l_extendedprice Decimal(15,2), l_discount Decimal(15,2), l_tax Decimal(15,2), l_returnflag String, l_linestatus String, l_shipdate Date, l_commitdate Date, l_receiptdate Date, l_shipinstruct String, l_shipmode String, l_comment String) ORDER BY (l_orderkey, l_linenumber);
PostgreSQL #
CREATE TABLE lineitem ( l_orderkey INT, l_partkey INT, l_suppkey INT, l_linenumber INT, l_quantity DECIMAL(15,2), l_extendedprice DECIMAL(15,2), l_discount DECIMAL(15,2), l_tax DECIMAL(15,2), l_returnflag CHAR(1), l_linestatus CHAR(1), l_shipdate DATE, l_commitdate DATE, l_receiptdate DATE, l_shipinstruct CHAR(25), l_shipmode CHAR(10), l_comment VARCHAR(44), PRIMARY KEY (l_orderkey, l_linenumber) );
Primary key and indexing #
Both databases use the official TPC-H compound primary key (l_orderkey, l_linenumber).
-
In PostgreSQL, this creates a B-tree index by default.
-
In ClickHouse, it creates a sparse primary index over the same columns.
In both cases, the index ensures that all queries with predicates on these columns can quickly locate matching rows, speeding up both updates and reads.
Data size #
We use the scale factor 100 version of this table, which contains roughly 600 million rows (~600 million items from ~150 million orders) and occupies ~30 GiB on disk with ClickHouse, and ~85 GiB with PostgreSQL.
Test environment #
Hardware and OS #
We used an AWS m6i.8xlarge EC2 instance (32 cores, 128 GB RAM) with a gp3 EBS volume (16k IOPS, 1000 MiB/s max throughput) running Ubuntu 24.04 LTS.
ClickHouse version #
We performed all tests with ClickHouse 25.7 with a default installation without any optimizations applied.
PostgreSQL version #
We used PostgreSQL 17.5 and installed it with optimized settings.
Benchmark methodology #
We measured cold update times by dropping the OS-level page cache before each update. This forces the database to load the affected rows from storage and apply the changes from scratch, without help from cached data or prior reads. The result is upper-bound (worst-case) latency numbers. Warm-cache measurements are harder to compare fairly, as PostgreSQL and ClickHouse cache and reuse data differently.
UPDATE: To give a fuller picture, we now report both cold run and hot runs. Cold runs stress I/O and highlight worst-case latencies, while hot runs simulate typical workloads with data already cached in memory.
Running it yourself #
You can reproduce all results with the Benchmark scripts on GitHub.
We’ll start small, looking at point updates that change a single row at a time, before moving on to multi-row bulk changes.
Single-row (point) updates #
We start with 10 standard SQL UPDATE statements, each targeting a single row identified by its primary key. These updates are executed sequentially in both ClickHouse and PostgreSQL.
Update latency #
For each update, the chart shows the cold time from issuing the UPDATE to when the change becomes visible to queries. The Cols upd column indicates how many of the 16 table columns were updated in that statement.
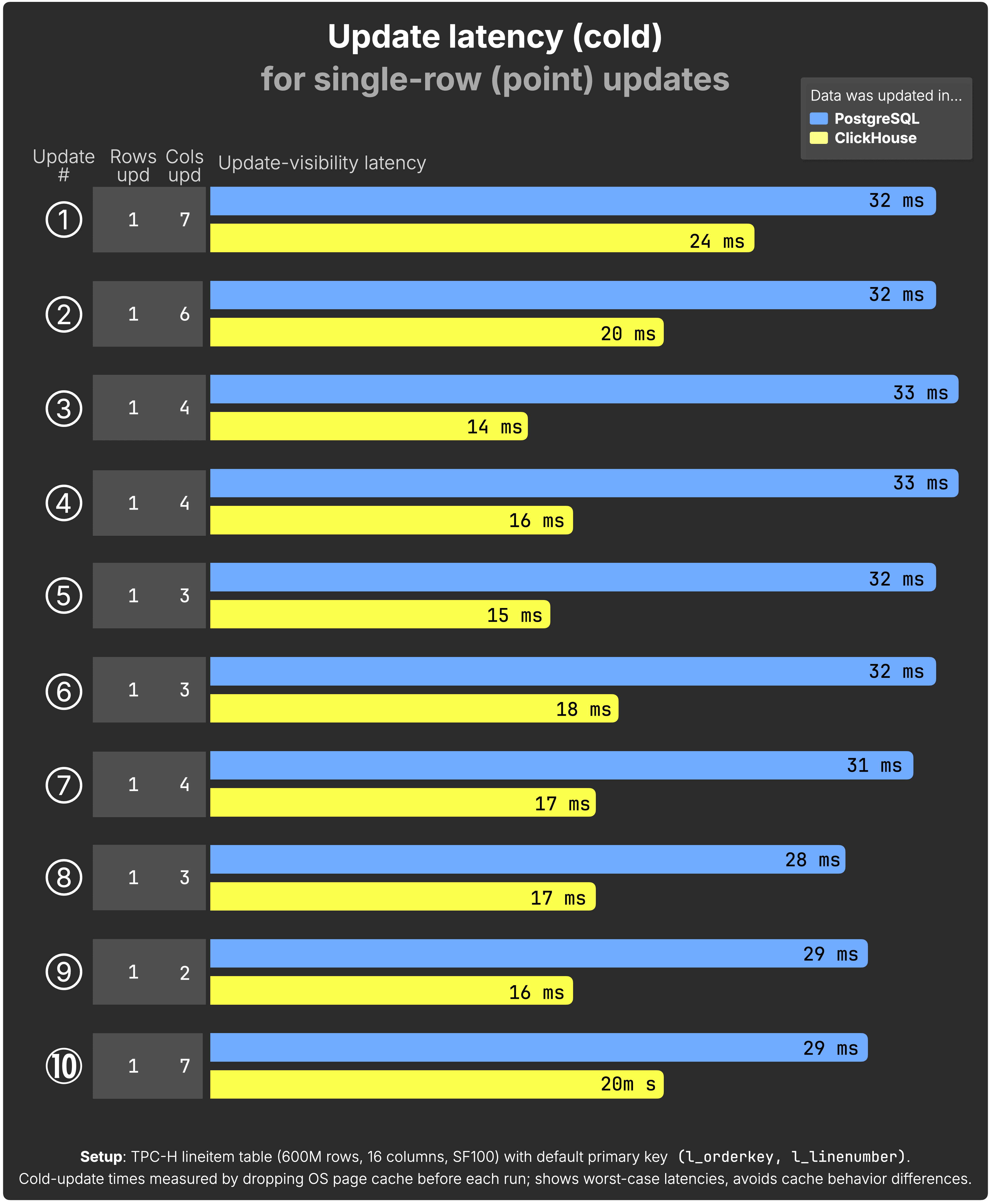
(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
In these point-updates, ClickHouse consistently finished faster, which is a super satisfying result. That said, we’ll highlight again that Postgres is incurring an overhead of wrapping every statement in a transaction context, which ClickHouse is not.
Given that, our main takeaways here are:
- Postgres is really fast!
- ClickHouse UPDATEs have started off strong, with great performance in cases where transactions aren’t needed.
- The current performance is good enough that, should ClickHouse introduce production support for transactions, there is a good chance we’ll end up in parity with Postgres in a more apples-to-apples test.
It’s also interesting to consider that each system finds an individual row in different ways; PostgreSQL uses a B-tree index with one entry per row to locate the target row directly. ClickHouse’s sparse primary index identifies the block of rows (8,192 rows by default) that might contain the target, then searches through all rows in parallel.
For most workloads, the update isn’t the end of the story; it’s what happens next that matters. In real dashboards and reports, updated values need to be reflected right away in downstream queries. So next, we check how each database handles analytical queries that run immediately after these updates.
Query latency after update #
We use 10 typical analytical queries that would immediately benefit from updated data. They cover common warehouse-style patterns, such as:
-
Revenue and margin recalculation – e.g., computing net revenue for a given shipping mode.
-
Aggregates on filtered subsets – e.g., average discounts and taxes for orders with certain comments or statuses.
-
Operational counts – e.g., counting orders shipped under specific modes or with certain instructions.
-
Ad-hoc investigations – e.g., sampling rows that match a comment substring.
These queries represent the kind of real-time dashboards and analytical reports where users expect updated facts to be reflected immediately after a change.
These queries are paired 1 with the 10 updates: After each update, its paired query runs. Each query touches at least the updated rows and columns, but many scan broader data for realistic analytics.
The following chart shows post-update cold query times for all 10 queries after each single-row UPDATE:
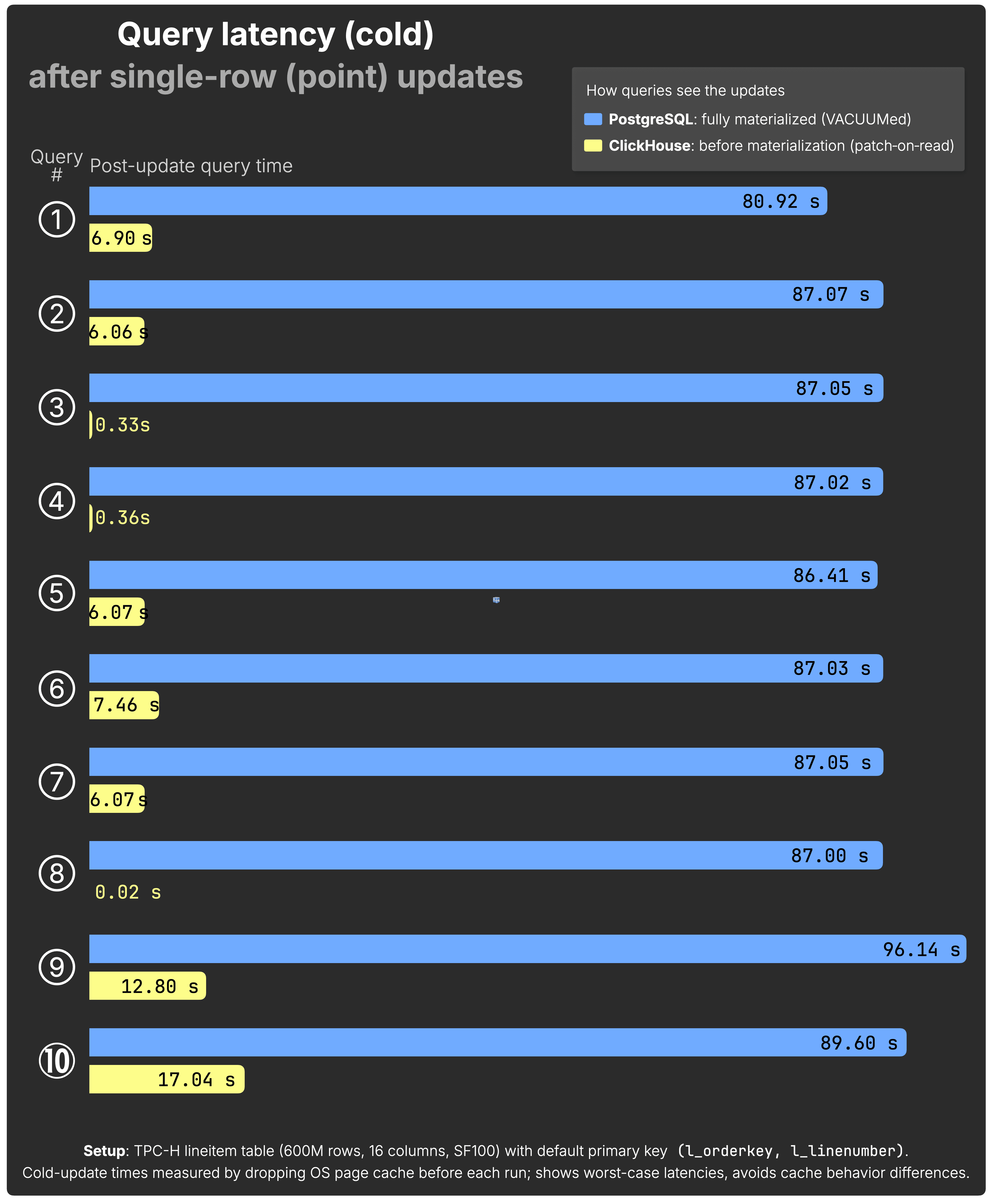
(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
For ClickHouse, we show Before materialization — queries see updated values instantly via patch-on-read, without waiting for background merges.
It’s not too surprising that ClickHouse is consistently much faster here; these are analytical queries over large datasets, and that’s ClickHouse’s home turf. The key takeaway is how little the update stage slows it down: whether updates are freshly applied or fully merged, query performance stays high and predictable.
Single-row updates are the OLTP baseline; they measure how quickly each engine can locate and modify an individual record. But many operational changes touch much larger slices of data, so next we look at bulk updates.
Bulk updates (multi-row changes) #
We took the same 10 standard SQL UPDATE statements used for the single-row updates test, but modified the predicates so they no longer target individual rows by primary key. Instead, they match dozens, hundreds, or even hundreds of thousands of rows, a very common OLTP pattern in an orders table.
Typical reasons for such bulk updates include:
-
Correcting data entry errors – fixing discounts, taxes, or prices for all orders matching a certain date and quantity.
-
Adjusting order statuses – changing return flags, shipping modes, or line statuses in response to business events.
-
Applying policy or pricing changes – repricing items for a given supplier, contract, or campaign.
-
Handling special-case bulk actions – marking orders as “priority,” “warranty extended,” or “return-flagged” based on filters like commit date or quantity.
These scenarios are frequent in production OLTP workloads, where operational changes must be applied to large, filtered subsets of data rather than to just one row at a time.
Update latency #
For every one of the 10 bulk UPDATEs (that we run sequentially in both ClickHouse and PostgreSQL), the chart measures the cold time from issuing the UPDATE to the moment its changes are visible to queries. The Rows upd and Cols upd columns indicate how many rows and how many of the 16 table columns were updated in each statement.

(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
Initially, these results looked a bit off… but they actually make sense. Except for update ⑤, none of these bulk updates can use a primary key index because their WHERE clauses filter on columns other than the primary key. (Both systems could use extra indexes, but with 16 columns, covering all combinations is impractical, especially for ad-hoc bulk updates, where creating the index might take longer than the update.)
In those cases, the real cost isn’t writing the changes, it’s finding the rows. That means scanning the table end to end.
For PostgreSQL, that takes 380–390 s on this dataset before the changes are visible. ClickHouse scans the same data in 0.09–5.23 s, up to 4,000× faster. The advantage comes from highly parallel processing and a column-oriented layout, only reading columns used in the UPDATE’s WHERE clause and only writing values for the columns being updated.
Update ⑤ is the one exception: both systems use an index to jump directly to the matching rows, narrowing the gap to “only” 26×. But in every other case, where both have to scan everything, ClickHouse’s raw scan speed keeps update-visibility latency low, even for massive changes.
In OLTP workloads, you can’t update what you haven’t located, and locating large numbers of rows quickly takes an analytical engine’s horsepower.
Still, applying the update is only part one. Part two is how quickly you can run analytics on the updated data, which is often the whole reason you made the change in the first place. Let’s see how each system performs when we immediately follow these bulk updates with representative analytical queries.
Query latency after update #
We use the same 10 typical analytical queries as before, paired again 1 with the 10 updates: After each update, its paired query runs. Each query touches at least the updated rows and columns, but many scan broader data for realistic analytics.
The next chart shows post-update cold query times for all 10 queries after each bulk-row UPDATE:
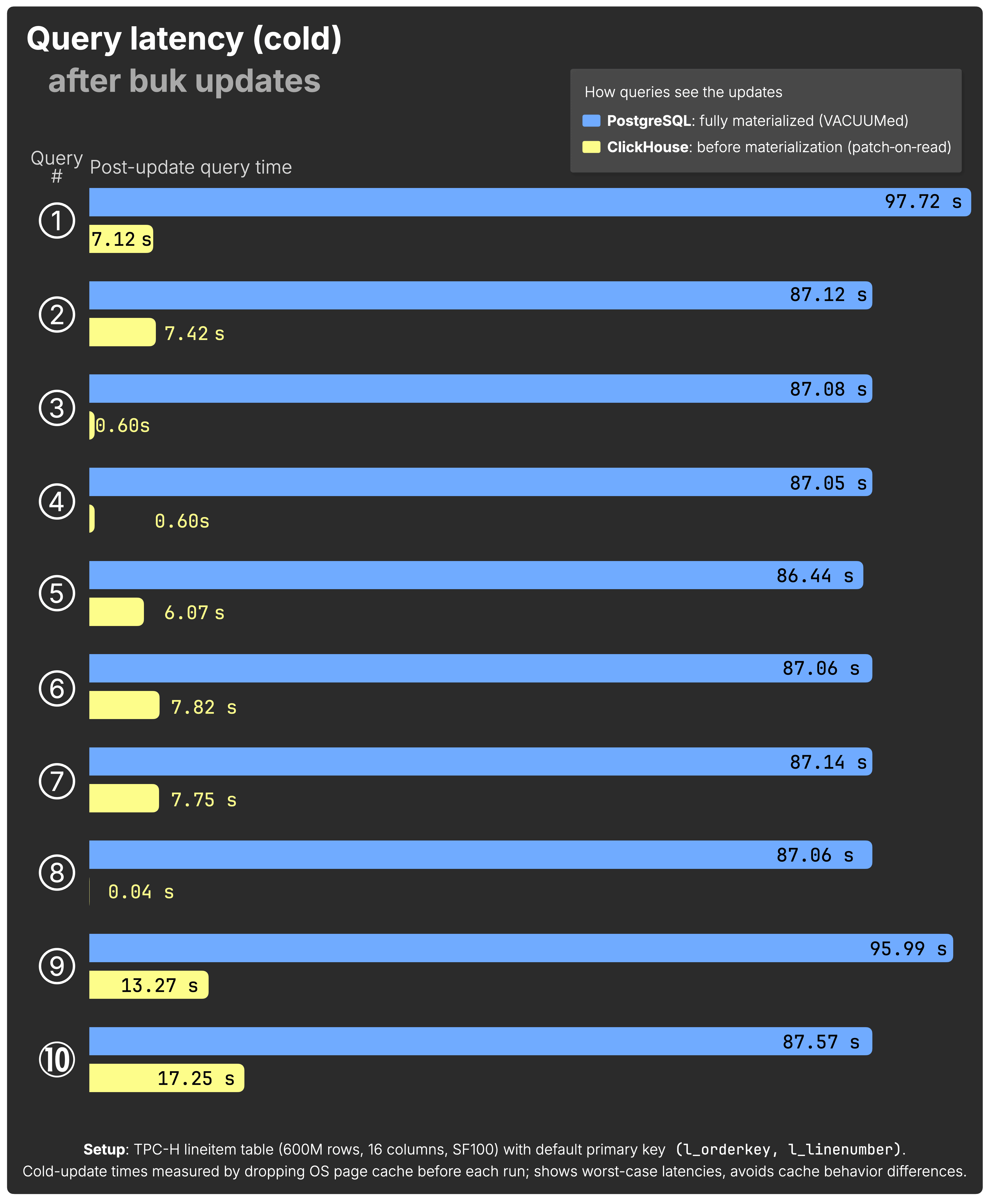
(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
As before, unsurprisingly, ClickHouse is consistently much faster than PostgreSQL on the same hardware and same dataset for typical analytical queries that would immediately benefit from updated data.
But cold runs only tell half the story. To complete the picture, let’s look at hot runs. Updates with data already cached, where different trade-offs emerge.
Hot results: the other side of the story #
In the first version of this post, we focused on cold runs: queries executed without cached data. Cold results are useful as a stress test, since they highlight differences in how systems handle I/O and large batch updates.
That said, we also got valuable feedback: in typical OLTP workloads, cold runs are rare. Index and cache hit rates are often above 99%, which means most updates operate under hot conditions with data already in memory.
To give a fuller picture, we extended our benchmarks with hot results as well. This way, we can compare both the diagnostic “worst case” and the “realistic baseline” for everyday workloads.
To keep things comparable, we’ll walk through the same charts as before, first single-row (point) updates, then bulk updates, this time under hot conditions.
Single-row (point) updates - Update latency and query latency after update #
For each update, the chart shows the hot latency from issuing the UPDATE to when the change becomes visible to queries, with all data already cached in memory. As before, the Cols upd column indicates how many of the 16 table columns were updated in that statement.
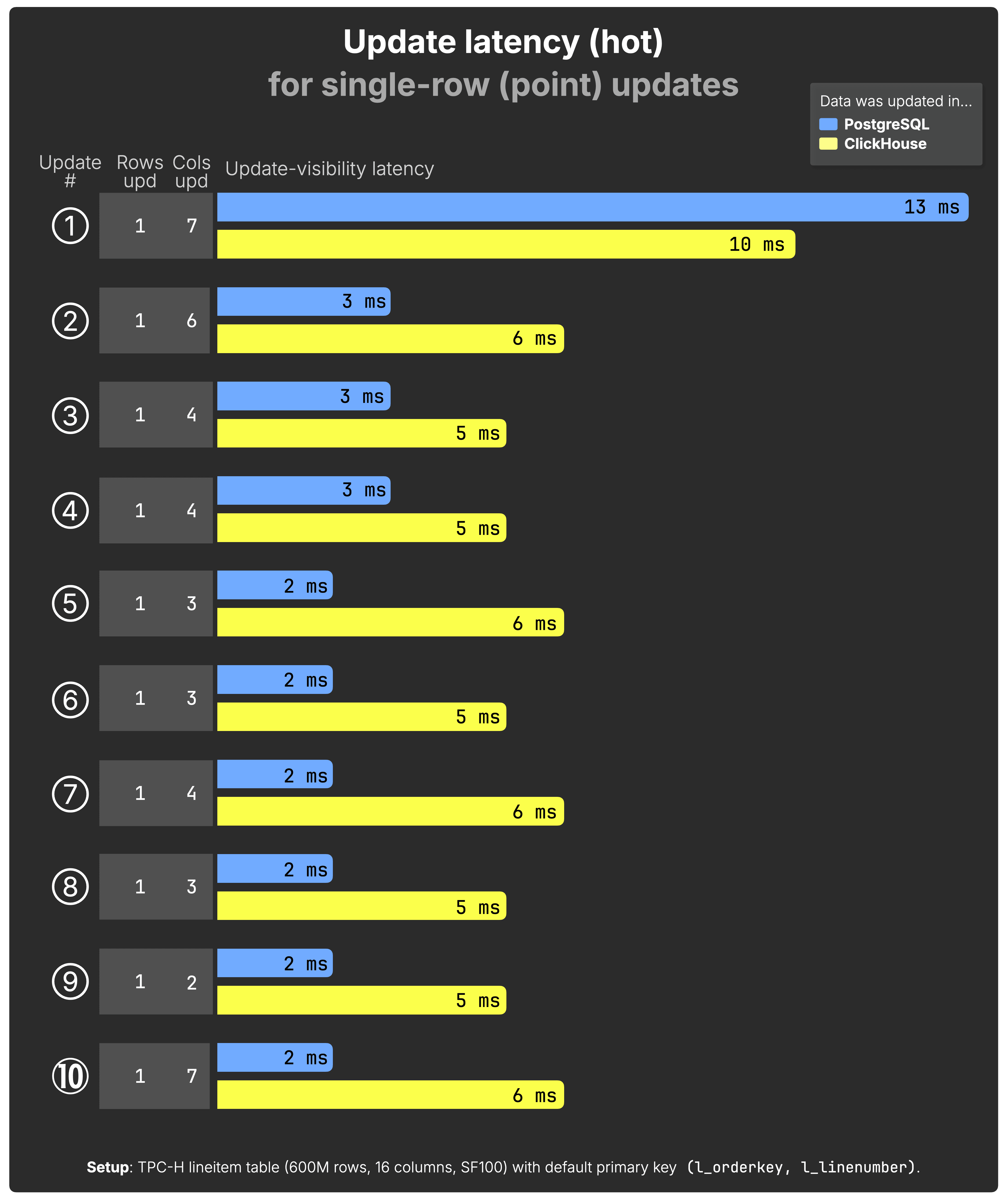
(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
In hot runs, where data is already cached in memory, PostgreSQL takes the lead. Even though every statement still pays the cost of being wrapped in a full transaction, its row-level B-tree index gives it a decisive advantage: it can pinpoint and update rows directly without scanning a block.
ClickHouse remains fast, consistently finishing updates in single-digit milliseconds, but is slightly behind PostgreSQL in these in-memory cases. That gap reflects the different execution models: ClickHouse’s sparse primary index always has to scan a full block of rows (8,192 by default), even when the data is already hot in memory.
The main takeaways are:
-
PostgreSQL wins on hot point updates, despite transactional overhead. Its index structure makes row lookups extremely efficient once data is cached.
-
ClickHouse is only a few milliseconds behind, still delivering excellent OLTP-style latencies.
-
Both systems are highly performant here, but their architectural trade-offs show through clearly: PostgreSQL is optimized for transactional point-updates, while ClickHouse’s design favors analytical workloads and still manages to compete closely.
The following chart shows post-update hot query times for all 10 queries after each single-row UPDATE:
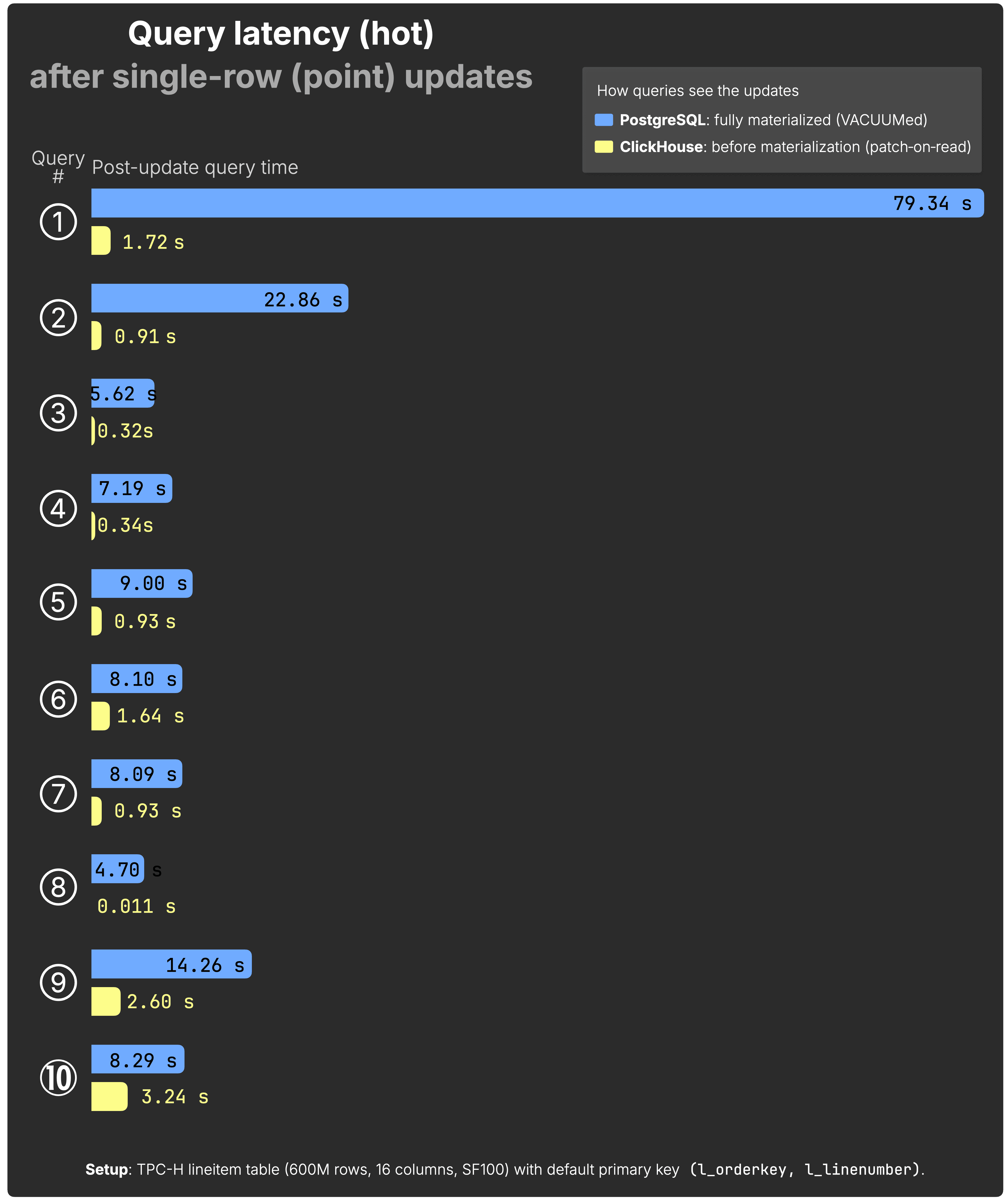
(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
For both PostgreSQL and ClickHouse, hot query runtimes are lower than in the cold runs since the data is already cached. But the relative behavior stays the same: as in the cold results, ClickHouse is consistently much faster than PostgreSQL on the same hardware and dataset when running typical analytical queries that immediately consume the updated data.
Bulk updates - Update latency and query latency after update #
For each of the 10 bulk UPDATEs, the chart shows the hot time from issuing the UPDATE to when its changes become visible to queries. The Rows upd and Cols upd columns indicate how many rows and how many of the 16 table columns were updated in each statement.

(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
In hot runs, where data is already cached, both PostgreSQL and ClickHouse finish bulk updates faster than in the cold case. But the relative picture doesn’t change: PostgreSQL still spends tens of seconds locating rows, while ClickHouse’s parallel scans keep updates in the sub-second range, up to 700× faster on this dataset.
The following chart shows post-update hot query times for all 10 queries after each bulk-row UPDATE:

(See the raw benchmark results for PostgreSQL and ClickHouse behind the chart above.)
With data cached, both systems see faster query times than in the cold runs. But the pattern holds: ClickHouse remains consistently much faster than PostgreSQL on the same hardware for analytical queries that immediately use the updated data.
Taken together, these tests show that ClickHouse not only applies changes quickly, but also makes them immediately useful for analytical queries, a rare combination in OLTP-heavy scenarios.
Conclusion #
High-performance SQL-standard UPDATEs are a rare feature in column stores and analytical databases. They’re hugely beneficial to analytical workloads, and one of the most challenging stepping stones toward supporting OLTP-style workloads.
When we set out to build UPDATEs for ClickHouse, the goal wasn’t to “beat Postgres.” That’s still not the goal. But we’re extremely proud that the effort has paid off with such convincing results: parity with PostgreSQL for single-row updates, and speedups of up to 4,000× for bulk updates.
Cold runs expose how differently the two systems handle large scans: ClickHouse is up to 4,000× faster on bulk updates. Hot runs confirm the trade-offs: PostgreSQL wins on cached point updates thanks to its B-tree index, but ClickHouse remains much faster for analytical queries and even holds its own on single-row OLTP-style updates.
We know that Postgres is offering full transaction semantics that aren’t yet possible in ClickHouse, but never say never. We see no reason why ClickHouse couldn’t support transactions in the future.
And we learned something that, perhaps, should have been obvious: You can’t UPDATE what you can’t find — and ClickHouse finds fast.



