ClickHouse Cloud was built in record time and brought to market in December 2022. Since then, over a thousand companies have onboarded their workloads into our managed service, and every day, they now collectively run 5.5 billion queries, scanning 3.5 quadrillion records, on top of 100PB of data!
Over the past two years, we've gained valuable insights from working closely with our users. We continuously listen to their feedback and release new features to meet their evolving needs. We started by focusing on broadening deployment options for our users, by extending support to include all major cloud providers – AWS, GCP, Azure, and AliCloud – and adding support for more regions – we now support 25 regions in total.
We also added new capabilities aimed to reduce time-to-value across data onboarding, operational controls, and analyst tooling. As some examples, we:
- Announced ClickPipes, a managed ingest service initially focused on Kafka-compatible services, and extended it to other streaming services like Amazon Kinesis, as well as capabilities for continuous and bulk-load data from object storage.
- Joined forces with PeerDB to add the best change data capture (CDC) technology to ClickPipes, initially focused on Postgres, with more connectors to follow.
- Relentlessly improved analyst experience, by joining forces with Arctype to bring the best GenAI-assisted SQL Console for ClickHouse Cloud, and extended these capabilities to add query API endpoints and dashboards. We ensured a smooth experience by natively integrating these capabilities with our cloud console.
- Continued to harden our managed database upgrades, one of the most compelling features of our cloud offering, by investing significant cycles into change management and introduction of release channels to provide users with greater control and flexibility in managing upgrades.
- Added a Bring-Your-Own-Cloud (BYOC) deployment option for AWS, via which users can continue to get the benefits of a fully managed service while their data stays in their VPC.
Evolving Existing Deployments #
In the process of building and operating our offering for the last two years we learned a lot from our users about their workloads and requirements, and have been hard at work to not only build features but also fundamentally evolve the underlying architecture of our cloud. As we head into 2025, we are excited to announce a number of significant improvements for the main ClickHouse Cloud offering stemming from these insights.
Compute-compute separation #
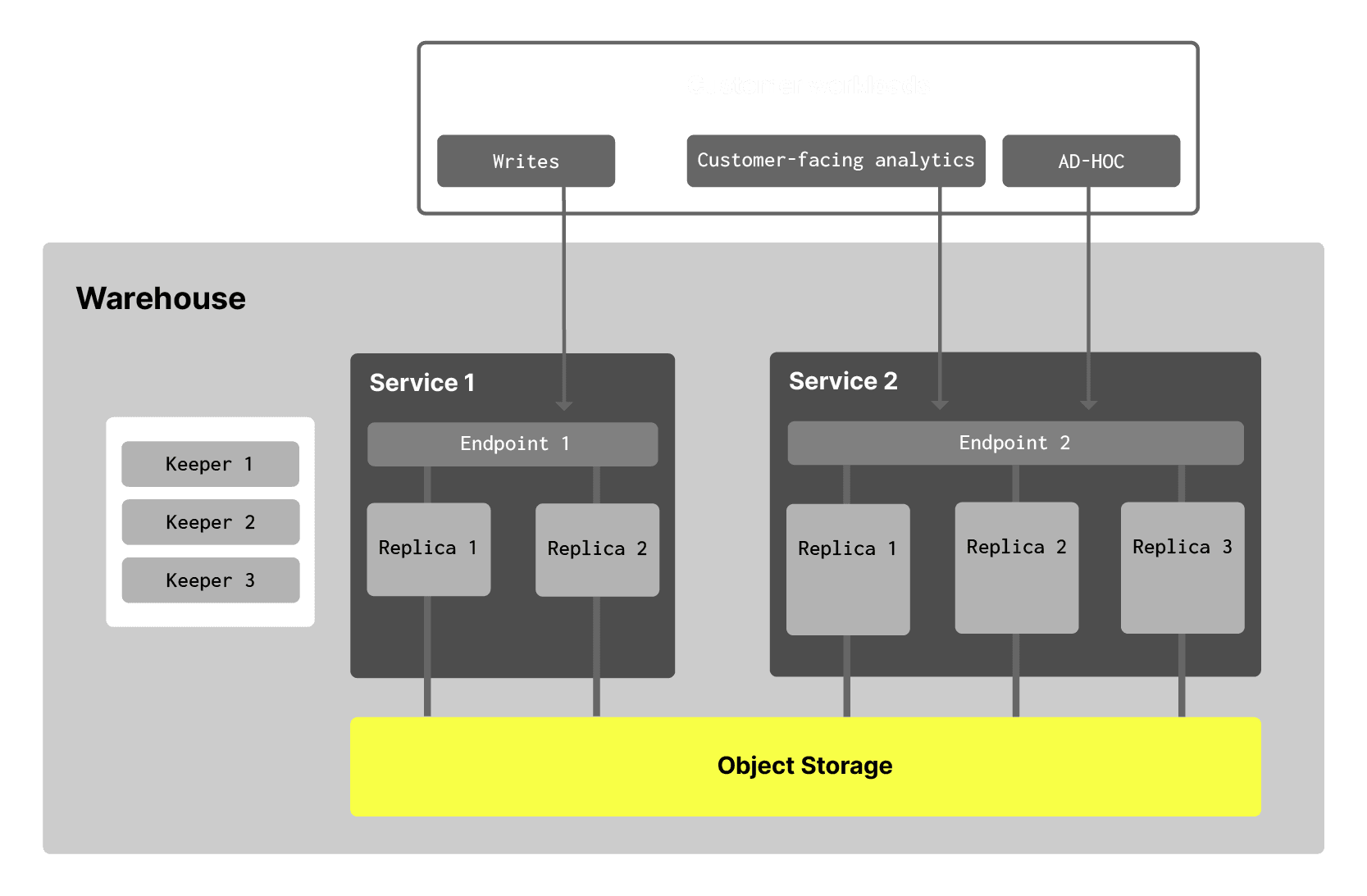
ClickHouse Cloud now supports compute-compute separation, enabling multiple compute replicas to access the same underlying data storage concurrently. This architecture allows for independent scaling of compute resources to handle diverse workloads without data duplication.
This results in much better workload isolation and consistent performance for each type of workload. For example, it is now possible to separate writers from readers, API users from human users, and different types of consumers, by offering them separate compute groups and limiting compute resources accordingly. Separating compute into separate groups also results in significant cost savings due to the ability to right-size each compute group versus over-provisioning overall compute for peak performance (read this blog for more details).
"What used to take 8 hours now takes 30 minutes or less. No noticeable impact on the other services. A+ feature!"
Cypress.io
Automatic scaling evolution #
We are introducing a new mechanism for vertical scaling of compute replicas, a concept we call "make before break" (or MBB). With this new approach, we add replica(s) of a new size before removing the old one(s) during the scaling operation. This results in more seamless scaling operations that are less disruptive to running workloads, because no capacity is lost during scaling. It is especially important during scale-up events as it is triggered by high resource utilization and removing replicas will make it worse. As a result, we can now introduce more agile scale-up and scale-down policies, helping automatically right-size compute resources to bursty workloads.
We are also introducing controls for horizontal scaling, allowing users more ways to change the number of replicas available to process workloads via API and UI. As a result, horizontal scaling can now be utilized in more scenarios to dynamically scale compute capacity when more parallel processing is required.
Managed upgrade improvements #
As mentioned earlier, safe managed upgrades deliver significant value to our users by allowing them to stay current with the database as it moves forward to add features. We thoroughly test databases before upgrades both on synthetic and real-world workloads, and carefully upgrade our user base, rolling back at any sign of degradation. With this rollout, we applied the "make before break" (or MBB) approach to upgrades, further reducing impact to running workloads.
More deployment factors #
We are introducing the concept of a "single-replica service", both as a standalone offering and within warehouses. As a standalone offering, single-replica services are size limited and intended to be used for small test workloads. This is an exciting development for developers looking for an even more cost-effective way to test out new ideas, and we are basing our new Basic tier on this concept.
Within warehouses, single-replica services can be deployed at larger sizes, and utilized for workloads not requiring high availability at scale, such as restartable ETL jobs. We have also expanded availability of 2-replica services to exist at any scale.
Performance and efficiency improvements #
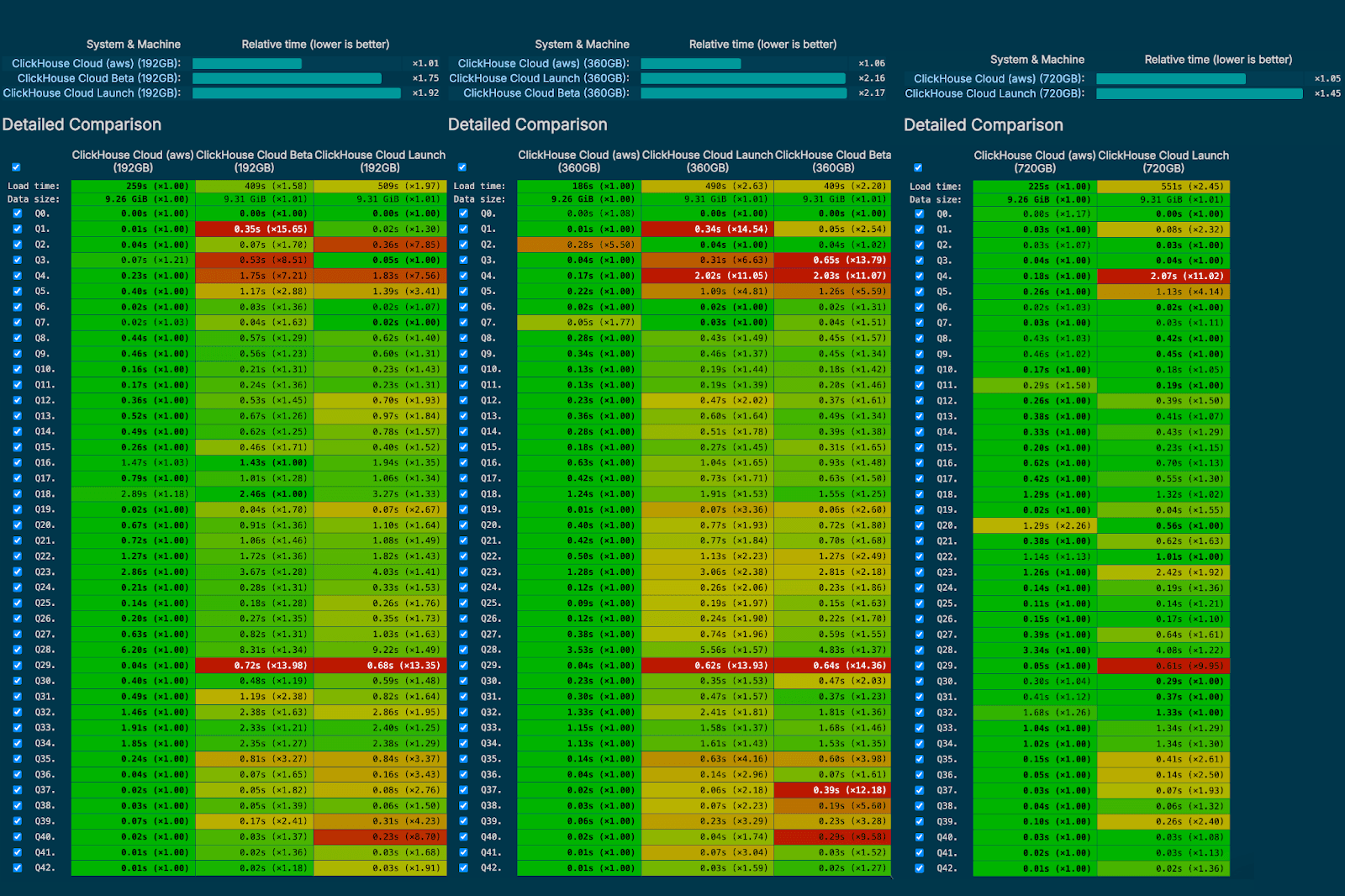
Performance regression testing is continuously performed in our cloud to ensure the best user experience while rolling out changes in new database versions. Over the past two years, we added a number of capabilities that resulted in 1.5-2x faster and more efficiently executed queries on top of the same compute unit, resulting in significant cost savings for our users.
These improvements resulted from many database optimizations. Most significantly, optimized storage for cloud environments was introduced with SharedMergeTree, enabling faster metadata propagation and higher rates of inserts. Furthermore, ephemeral local filesystem cache was introduced to increase performance of small queries and optimized with cache prewarm, which enables propagation of fresh data to all replicas and speeds up queries that access most recent data. Asynchronous inserts were introduced to allow even more frequent and smaller writes, enabling users to remove external approaches to batch data written to ClickHouse. Finally, a new "analyzer" was developed at the database level to support additional query optimizations and streamlined query parsing and interpretation.
Additionally, we constantly look for better underlying hardware to run existing workloads. For this reason, we moved to Graviton instances in AWS. As a result of the migration to the advanced architecture and energy-efficient Graviton instances, we are delivering an average performance boost of 25% for our users, enhancing query speeds and improving resource utilization (read this blog for more details).
Introducing the Enterprise Offering #
We are introducing a new Enterprise Tier to serve the needs of the most demanding customers and workloads, with focus on industry-specific security and compliance features, even more controls over underlying hardware and upgrades, and advanced disaster recovery features.
Advanced security and compliance #
We are introducing support for Transparent Data Encryption (TDE) as an additional layer of protection for data in object storage. Customers may optionally change the encryption key to implement Customer Managed Encryption Keys (CMEK) for additional control, which is required for the most privacy conscious organizations. Additionally, we support single-sign on to the cloud console, and industry-specific compliance options, starting with HIPPA (and PCI on the horizon).
Advanced upgrade controls #
Building on our release channels feature, we are introducing "scheduled upgrades", which allows users to set a specific day of the week and time window for upgrades for each service. We will soon launch a "slow" release channel, enabling users to delay upgrades. Services on the "slow" channel will be upgraded two weeks after the regular release, giving users more time to plan and prepare for critical upgrades.
Advanced disaster recovery #
By default, any service with two or more replicas is deployed across multiple availability zones, ensuring resilience against zone outages. We are adding the ability for customers to export backups to their cloud account, which allows them to execute custom disaster-recovery policies independently. Next up on our roadmap is adding support for cross-region backups, which will enable customers to recover from the unlikely event of a whole region outage faster.
Advanced hardware and region profiles #
We currently offer custom hardware profiles with our Dedicated service type. We are evolving this separate concept to become just one of the features of the Enterprise tier with the idea of "custom hardware profiles". We are starting with HighMem (1:8) and HighCPU (1:2) profiles in addition to our general-purpose compute with 1 CPU ratio available by default.
We are also adding access to additional private regions not available publicly as one of the perks available to Enterprise Tier users. These region requests are evaluated on a case-by-case basis, via support.
Evolving support offerings #
Finally, we are enhancing our support services to better assist our customers. For example, we are introducing a new 30-minute response time 24x7 SLA for Severity-1 issues at the Enterprise tier level. Additionally, we are excited to introduce a dedicated Technical Account Manager (TAM) role to provide dedicated consultative support for customers that require it, offering expertise in design best-practices, solution architecture, migrations, and ongoing guidance to optimize your ClickHouse deployments.
Next steps #
Alongside introducing the Enterprise tier described above, we are restructuring our current Development and Production tiers to more closely match how our evolving customer base is using our offerings – with the Basic tier oriented toward users that are testing out new ideas and projects and the Scale tier matching users working with production workloads and data at scale.
To experience these and other recently introduced capabilities of ClickHouse Cloud as a new customer, start a free $300 trial here. As an existing customer, you can follow the in-product prompts to migrate an existing deployment to one of the new tiers and refer to this FAQ for any questions.



