基于 ClickStack 的告警
ClickStack 内置了告警功能,使团队能够在日志、指标和追踪等各类数据中实时发现并响应问题。
可以直接在 HyperDX 界面中创建告警,并与 Slack、PagerDuty 等常用通知系统集成。
告警功能可以无缝适用于 ClickStack 数据,帮助你跟踪系统健康状况、捕获性能回归,并监控关键业务事件。
告警类型
ClickStack 支持两种互补的告警创建方式:搜索告警 和 仪表盘图表告警。告警创建后,会附加到相应的搜索或图表上。
1. 搜索告警
搜索告警允许根据已保存搜索的结果触发通知,帮助你检测特定事件或模式出现频率高于(或低于)预期的情况。
当在定义的时间窗口内,匹配结果的数量超过或低于指定阈值时,就会触发告警。
要创建搜索告警:
创建告警
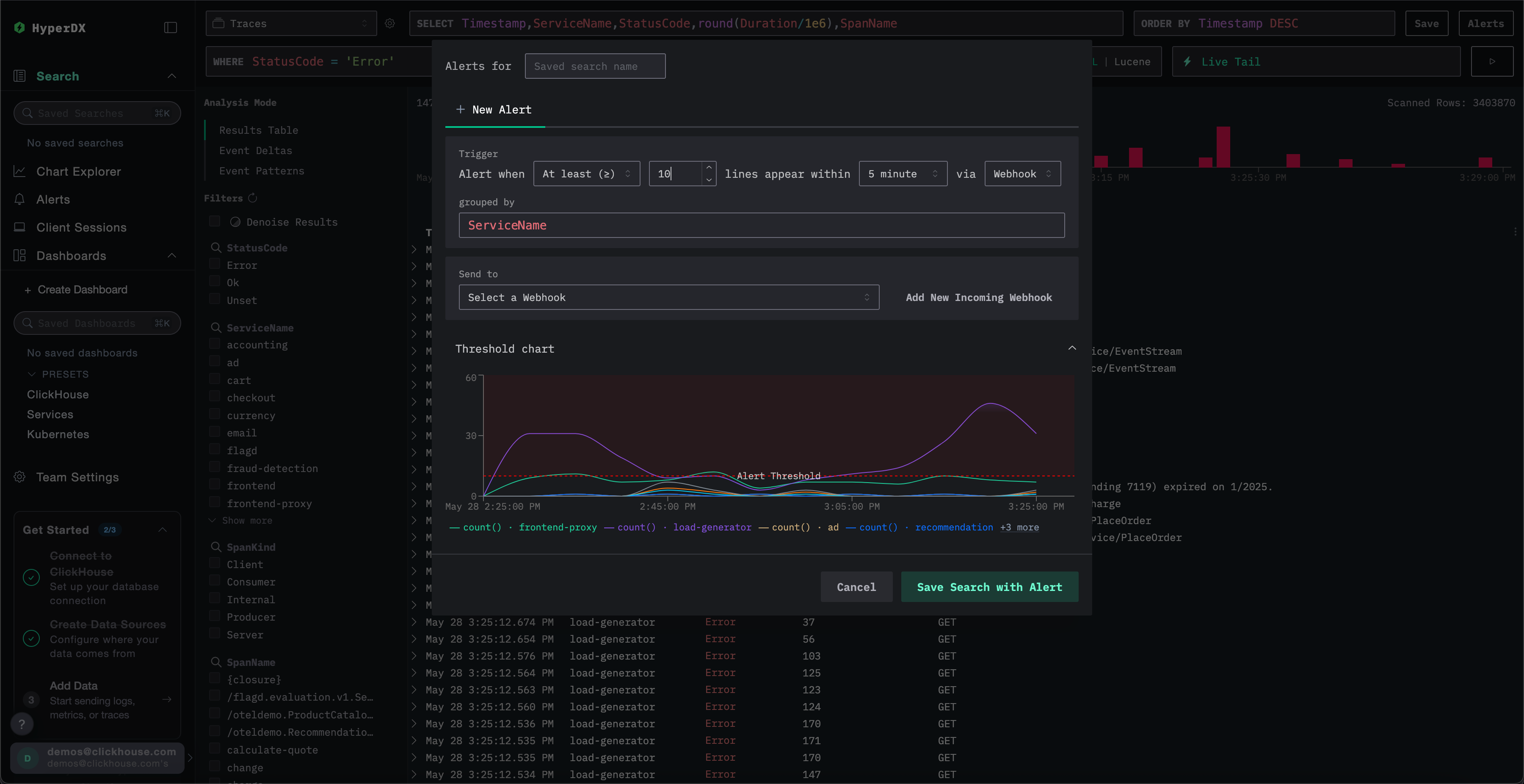
在告警创建面板中,你可以:
- 为与告警关联的已保存搜索指定名称。
- 设置阈值,并指定在给定时间段内需要达到该阈值的次数。阈值既可以作为上限,也可以作为下限。这里的时间段还将决定告警被触发的频率。
- 指定一个
grouped by值。这允许对搜索结果进行聚合,例如按ServiceName聚合,从而基于同一次搜索触发多个告警。 - 选择用于通知的 webhook 目标端点。你可以在此视图中直接添加新的 webhook。详情参见添加 webhook。
在保存之前,ClickStack 会对阈值条件进行可视化展示,以便你确认其行为是否符合预期。
请注意,可以为同一个搜索添加多个告警。如果重复上述过程,你会在编辑告警对话框顶部看到当前告警以标签页形式展示,每个告警都会被分配一个编号。
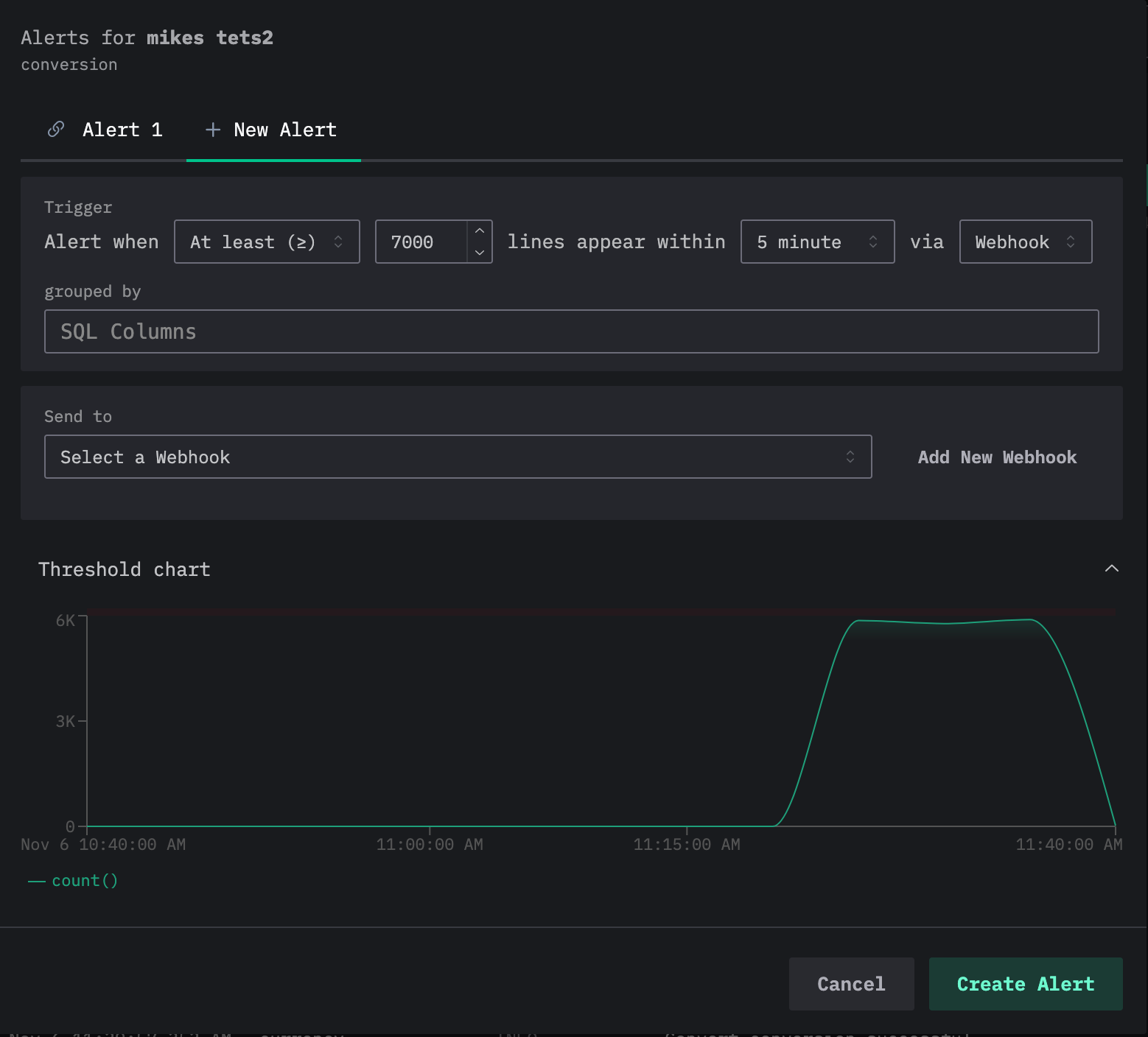
2. 仪表板图表告警
仪表板告警将告警能力扩展到图表层面。
你可以直接在已保存的仪表板上创建基于图表的告警,利用完整的 SQL 聚合能力和 ClickHouse 函数进行高级计算。
当某个指标越过设定阈值时,会自动触发告警,使你能够持续监控 KPI、延迟或其他关键指标。
要为仪表板上的可视化创建告警,必须先保存该仪表板。
要添加仪表板告警:
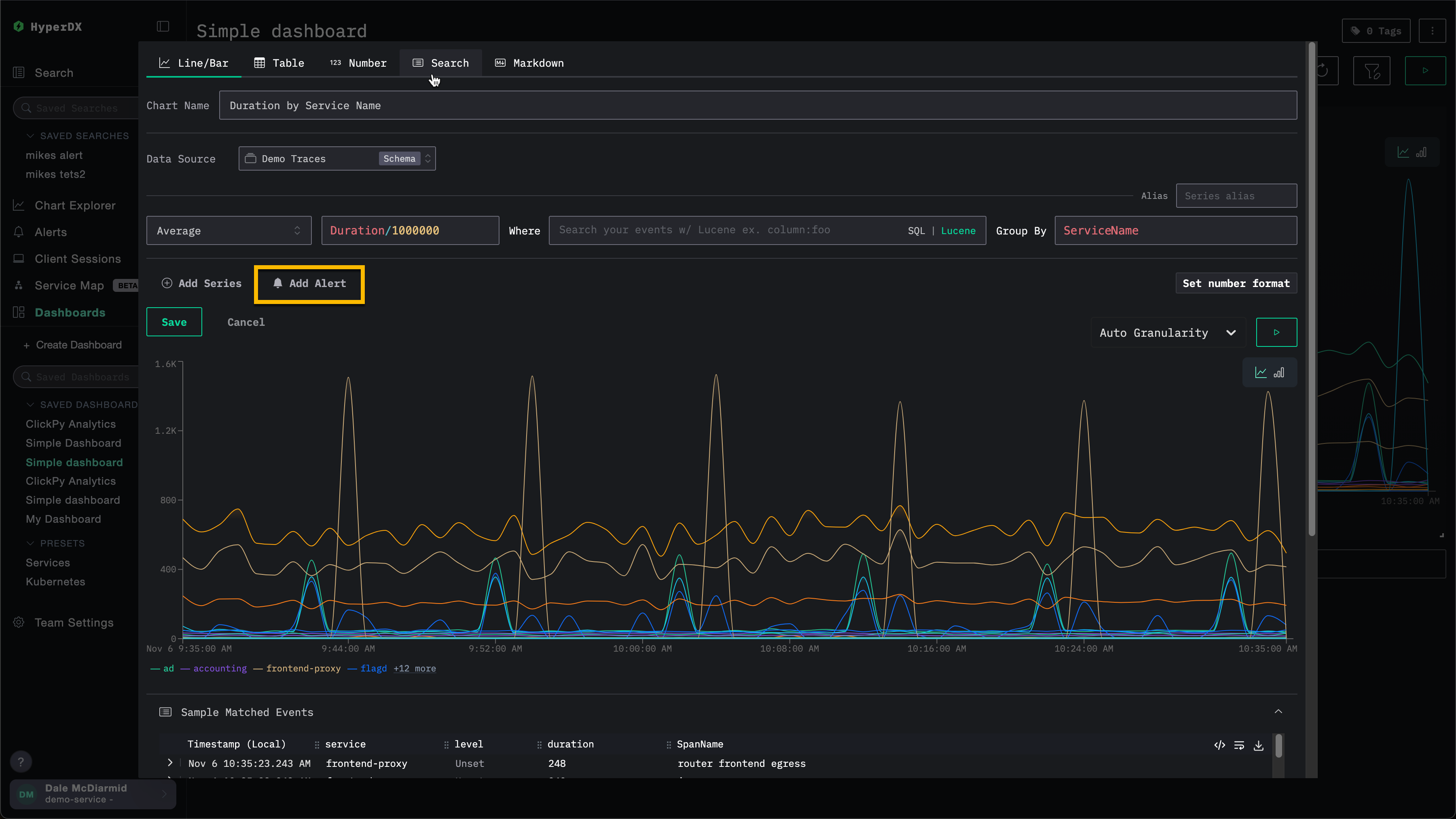
定义告警条件
定义条件 (>=、>、<=、<、=、!=、<= x >=、> or <) 、阈值、持续时间以及 webhook。此处的持续时间也将决定告警的触发频率。
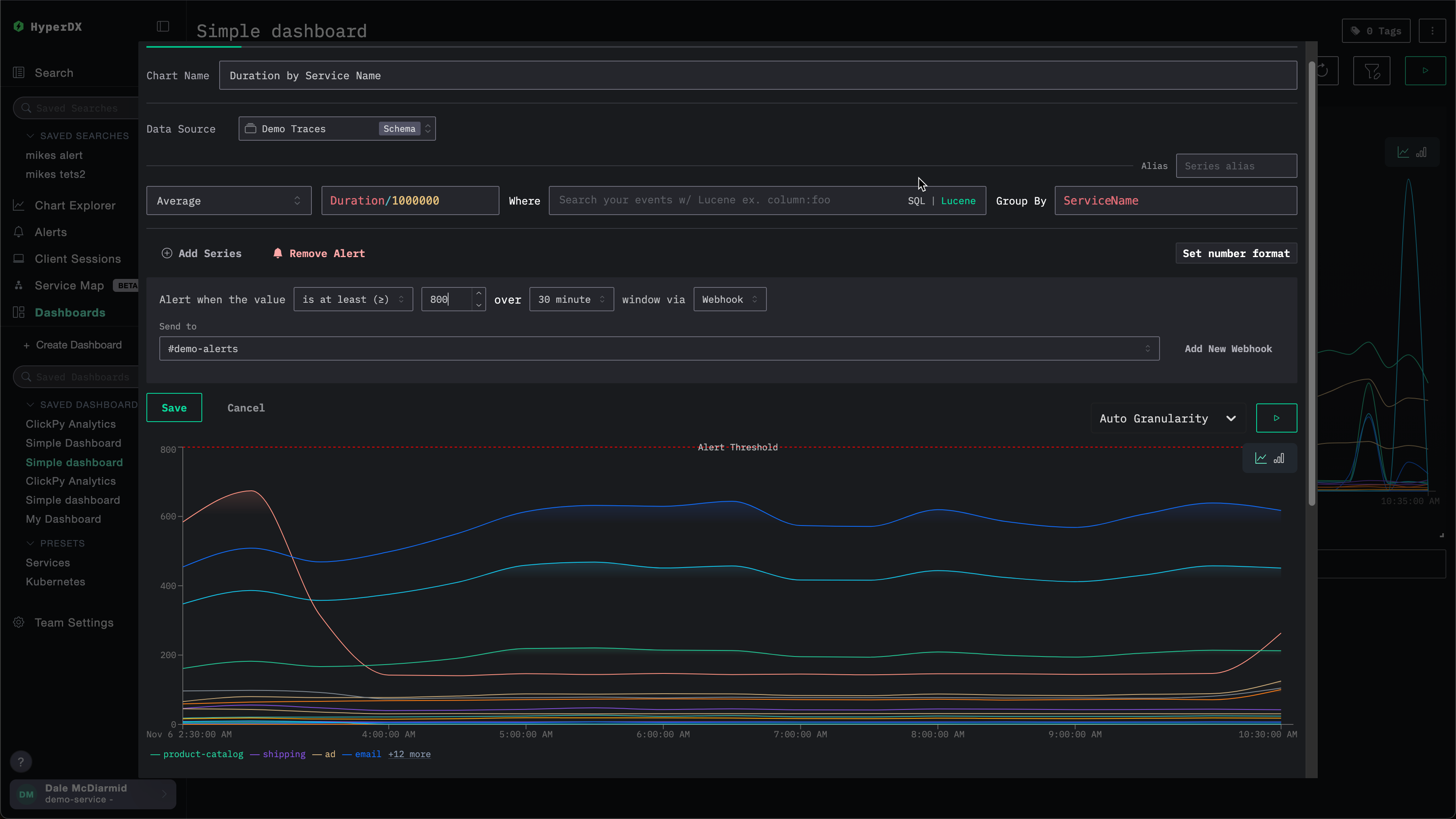
你可以直接在此界面中添加新的 webhook。详细信息参见 添加 webhook。
添加 webhook
在创建告警时,你可以使用已有的 webhook,或创建一个新的。一旦创建,该 webhook 就可以在其他告警中复用。
可以为不同的服务类型创建 webhook,包括 Slack、PagerDuty,以及通用目标(generic targets)。
例如,下面是为某个图表创建告警的过程。在指定 webhook 之前,用户可以选择 Add New Webhook。
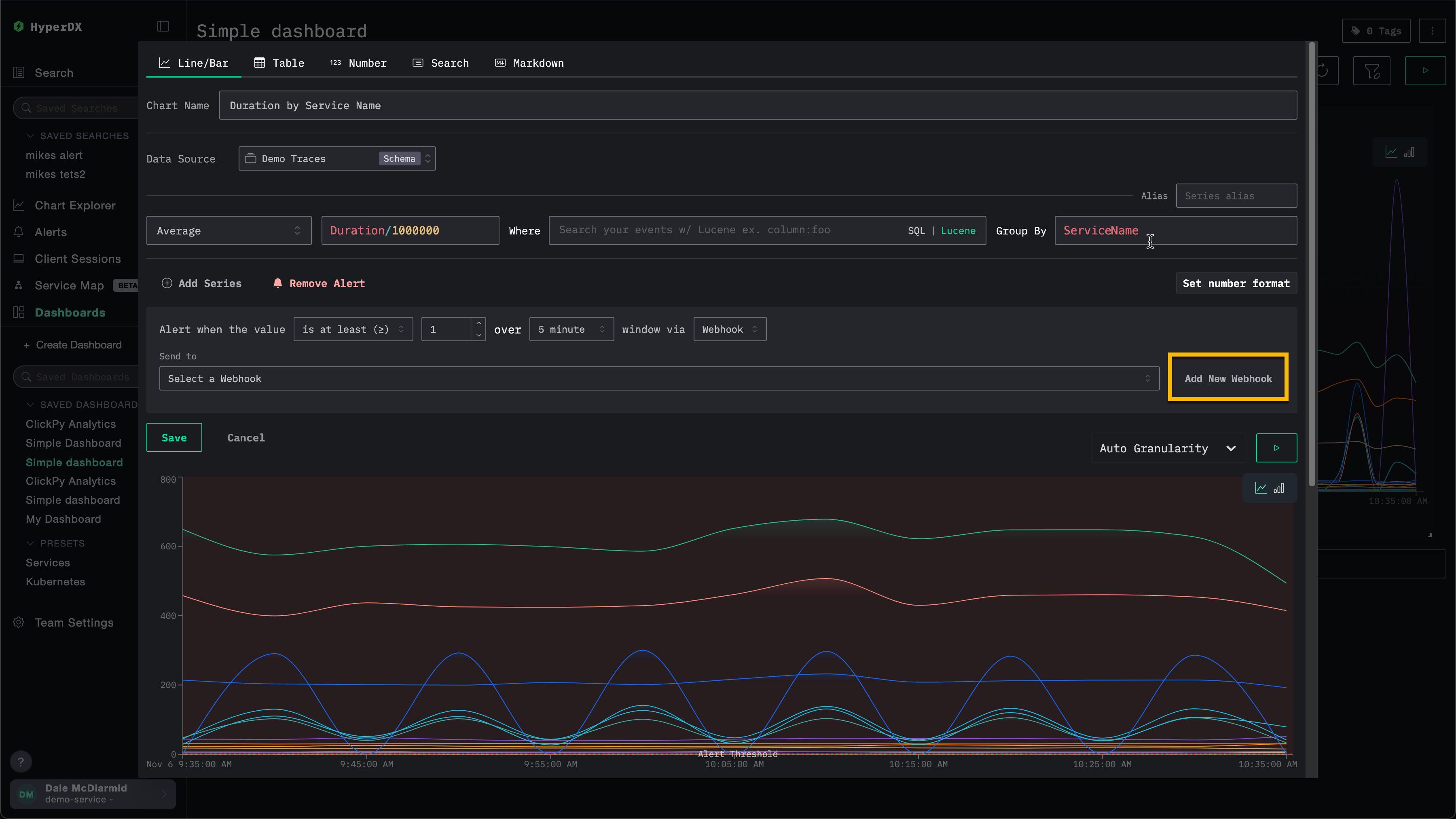
这会打开 webhook 创建对话框,你可以在其中创建一个新的 webhook:
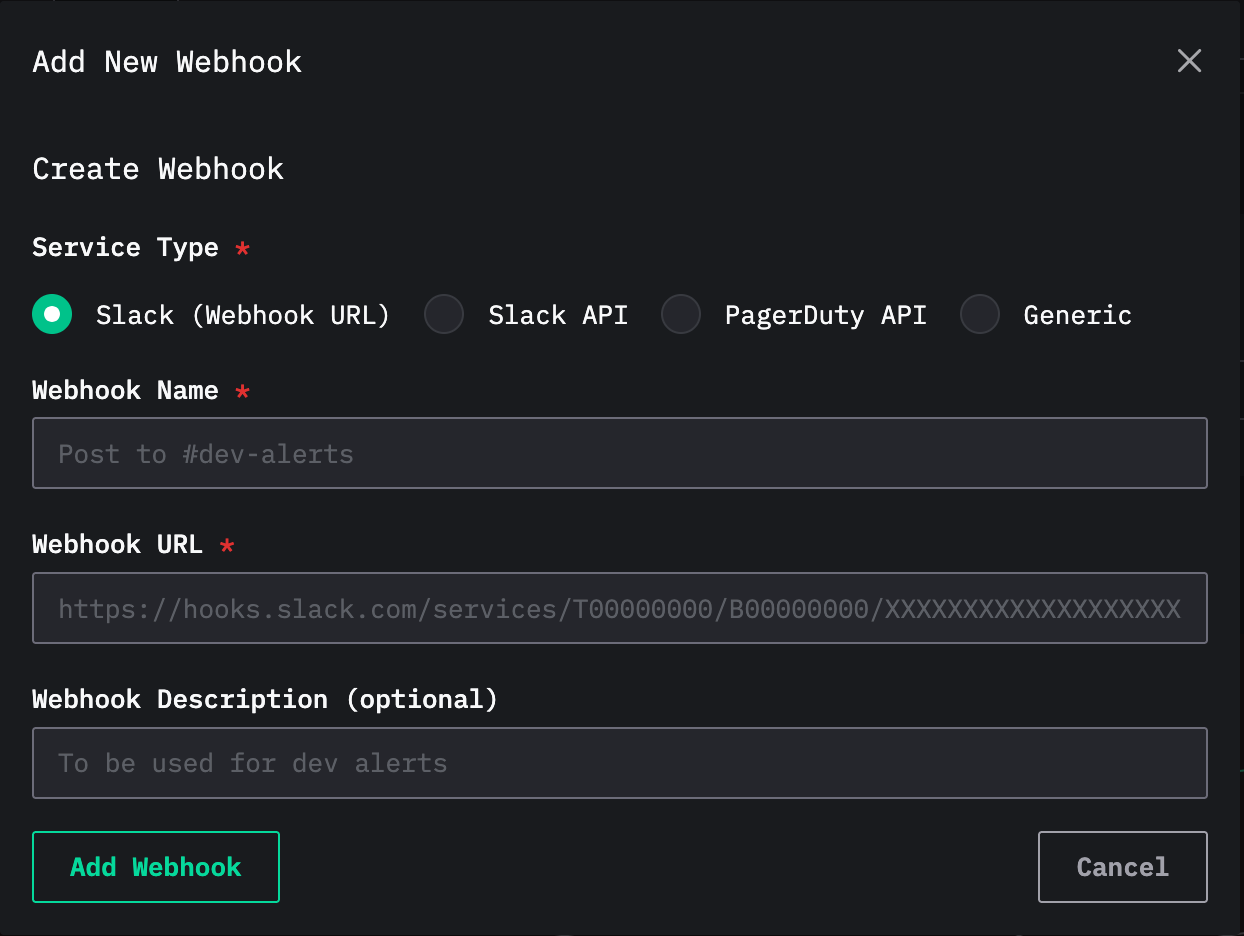
webhook 名称为必填项,描述为可选项。其他必填设置取决于服务类型。
请注意,ClickStack Open Source 与 ClickStack Cloud 所提供的服务类型不同。参见 Service type integrations。
服务类型集成
ClickStack 警报开箱即用地支持与以下服务类型集成:
- Slack:通过 webhook 或 API 直接向频道发送通知。
- PagerDuty:通过 PagerDuty API 将事件路由到值班团队。
- Webhook:通过通用 webhook 将警报连接到任意自定义系统或工作流。
Slack API 和 PagerDuty 集成仅在 ClickHouse Cloud 中提供。
根据服务类型的不同,用户需要提供不同的配置信息。具体如下:
Slack(Webhook URL)
- Webhook URL。例如:
https://hooks.slack.com/services/<unique_path>。更多详情请参阅 Slack 文档。
Slack(API)
- Slack 机器人令牌。更多详情请参阅 Slack 文档。
PagerDuty API
- PagerDuty 集成密钥。更多详情请参阅 PagerDuty 文档。
通用
- Webhook URL
- Webhook 请求头(可选)
- Webhook 请求体(可选)。当前请求体支持模板变量
{{title}}、{{body}}和{{link}}。
管理告警
可以通过 HyperDX 左侧的告警面板集中管理告警。
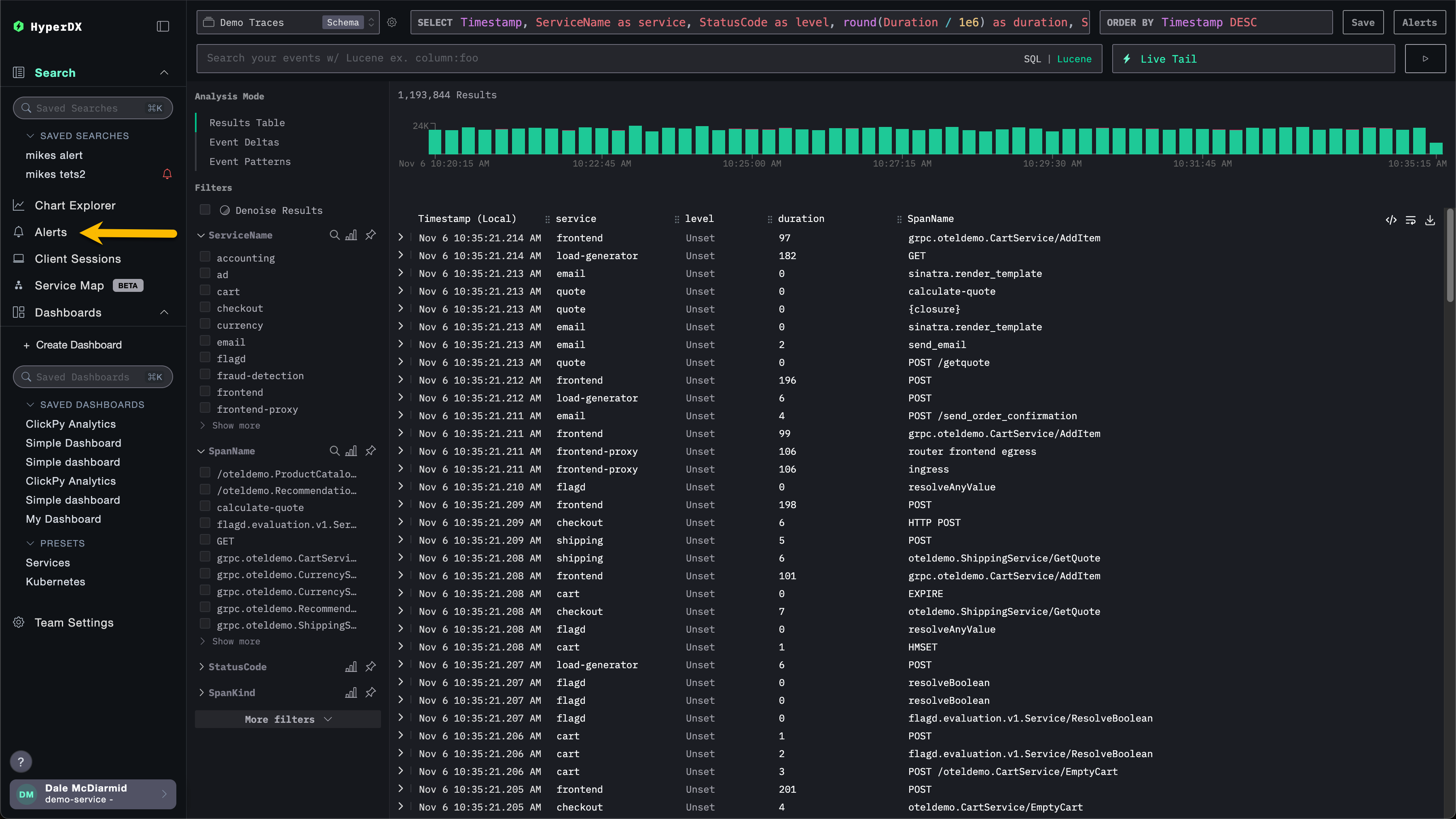
在此视图中,您可以看到已在 ClickStack 中创建且当前正在运行的所有告警。
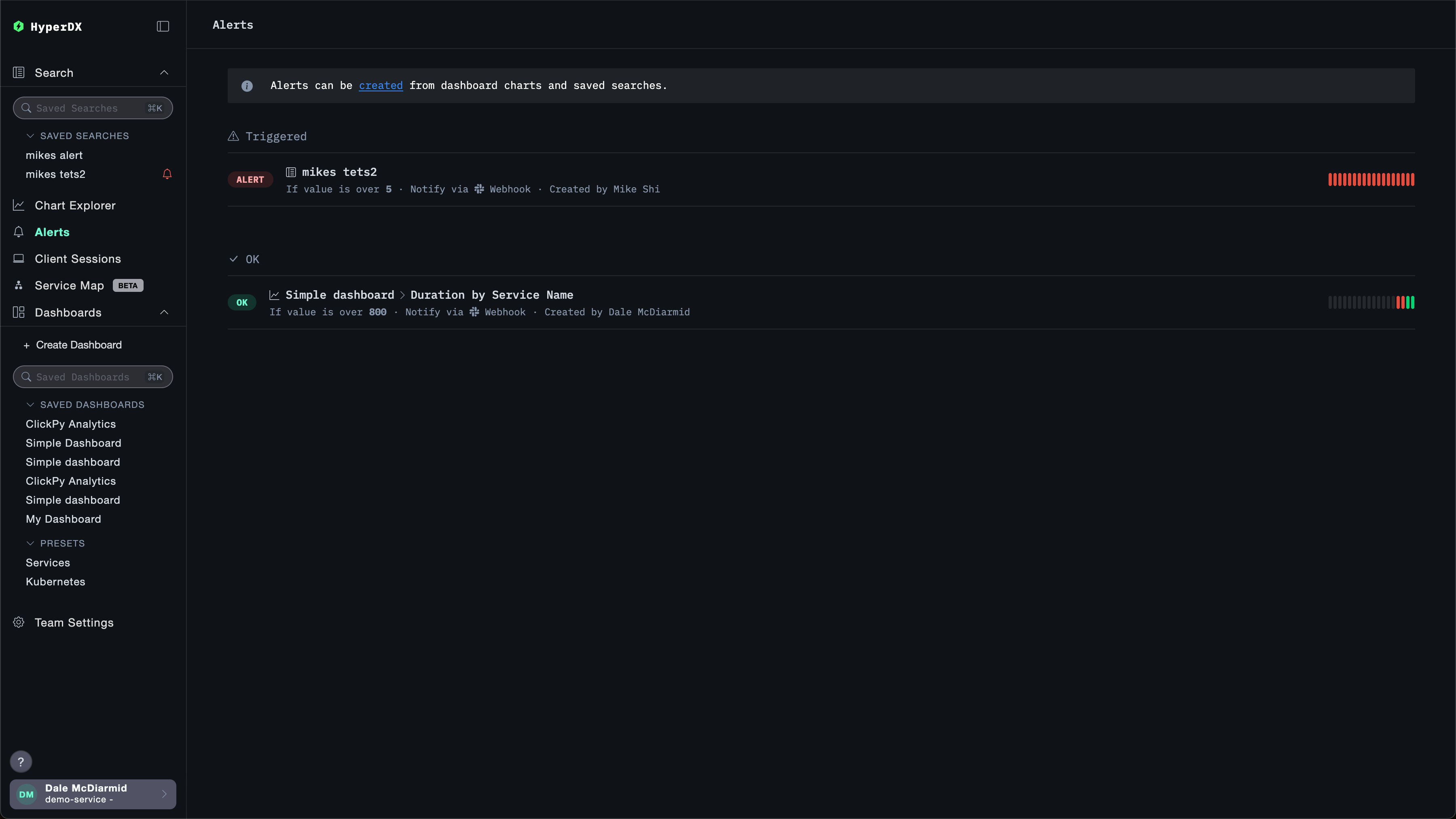
此视图还会显示告警评估历史。告警会按固定时间间隔进行评估(由创建告警时设置的周期/持续时长定义)。在每次评估期间,HyperDX 会查询您的数据,以检查是否满足告警条件:
- 红色条:在本次评估期间满足阈值条件,告警被触发(已发送通知)
- 绿色条:告警已被评估,但未满足阈值条件(未发送通知)
每次评估都是相互独立的——告警会检查该时间窗口内的数据,仅在该时刻条件为真时才会触发。
在上面的示例中,第一个告警在每次评估时都被触发,表明存在持续性问题。第二个告警表示问题已解决——它在最初两次评估时被触发(红色条),随后几次评估中阈值条件不再满足(绿色条)。
点击某个告警会跳转到该告警所关联的图表或搜索。
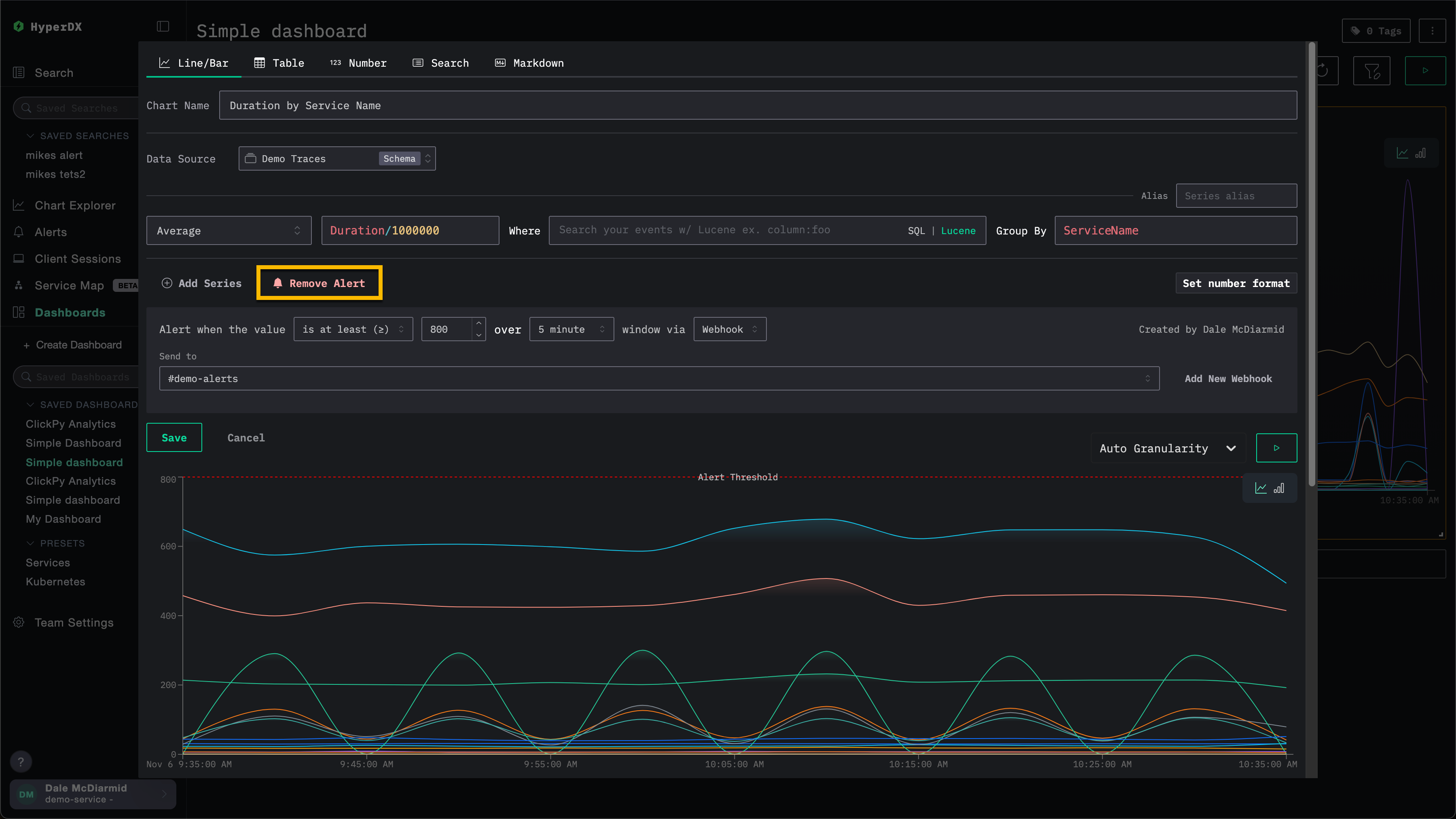
删除告警
要删除告警,请打开相关搜索或图表的编辑对话框,然后选择 Remove Alert(删除告警)。
在下图示例中,Remove Alert 按钮会将该告警从图表中删除。
基于 SQL 的图表告警
基于 SQL 的图表告警允许您编写任意 ClickHouse SQL 来定义告警条件。这样,您就可以完全控制过滤、聚合和计算——凡是能用 SQL 表达的内容,都可以设置为告警。
支持的图表类型
基于 SQL 的告警支持以下三种图表展示类型:
| 图表类型 | 行为 |
|---|---|
| 折线图 | 时序告警。查询必须生成按时间分桶的行。系统会针对每个桶独立与阈值进行比较。 |
| 堆叠条形图 | 时序告警。行为与折线图相同。 |
| 数值 | 单值告警。查询返回单个数值结果,系统会在每次评估时将其与阈值比较一次。 |
其他基于 SQL 的图表类型 (表格、饼图、热力图等) 不支持告警。
创建 SQL 告警
要在基于 SQL 的图表上创建告警:
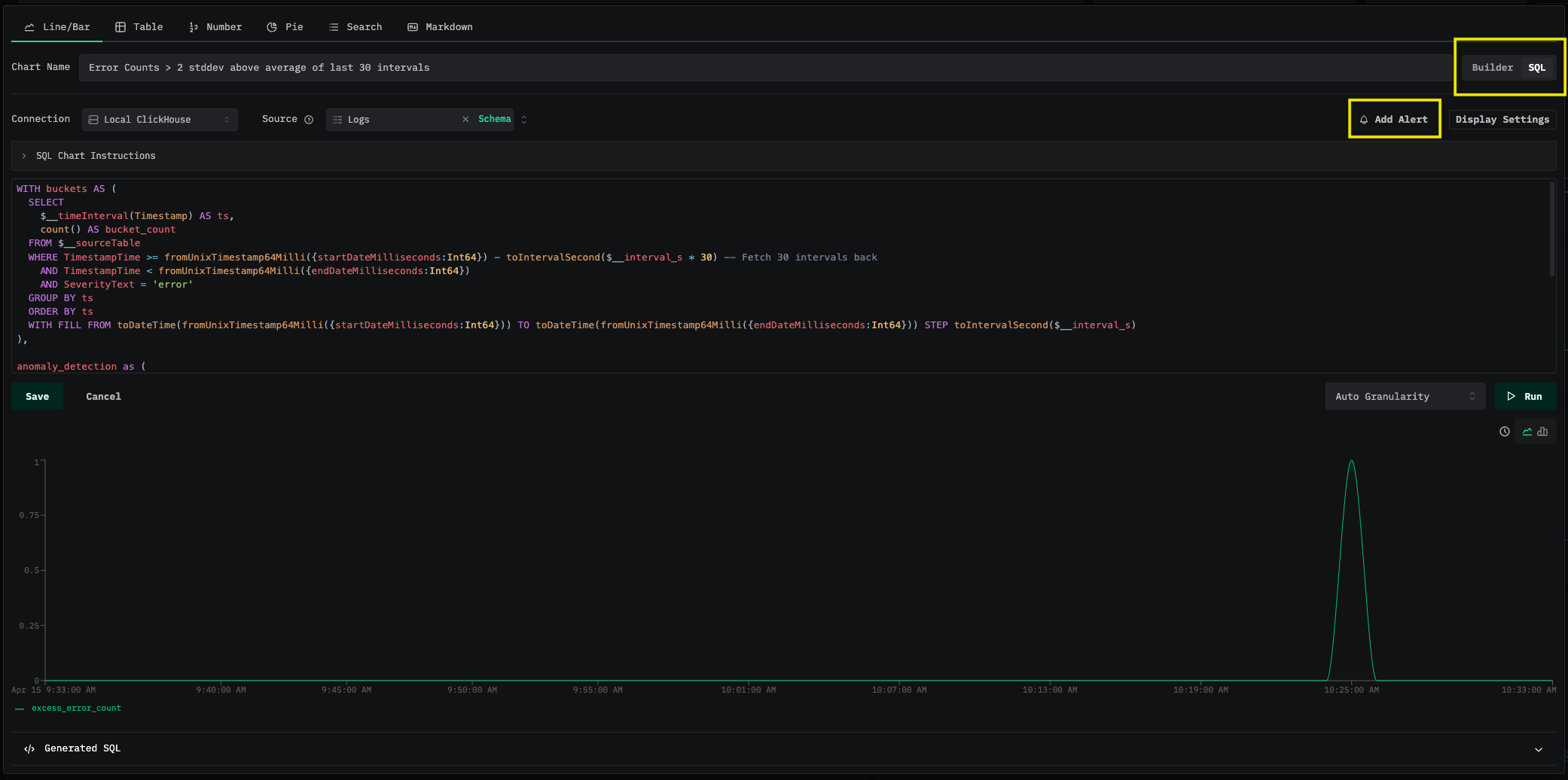
添加告警
在图表编辑器的告警部分选择 Add Alert。配置以下内容:
- Threshold type:
>=(大于或等于) 、>(大于) 、<=(小于或等于) 、<(小于) 、=(等于) 、!=(不等于) 、<= x >=(介于两者之间) 或> or <(超出范围) - Threshold value:用于比较的数值
- Interval:告警的评估频率 (1m、5m、15m、30m、1h、6h、12h 或 1d) 。这也定义了每次评估的时间窗口。
- Webhook:告警触发时使用的通知渠道。请参见添加 webhook。
通常,告警查询会按每个时间间隔执行一次。但是,如果由于错误或查询过慢而跳过了一个或多个时间间隔,下一次执行将使用包含这些遗漏时间间隔的时间范围。在这种情况下,查询的 时间间隔 参数仍会设置为告警配置的周期,而 time range 参数则会反映更长的时间范围。
保存仪表板
保存仪表板以激活告警。告警将按配置的时间间隔开始评估。
查询结果的解释方式
告警系统会检查 SQL 查询返回的列,以确定应将哪个值与阈值进行比较。
- 值列:
SELECT子句中的最后一个数值列会被用作告警值。如果查询返回多个数值列 (例如count, avg_latency, p99_latency) ,则只有最后一列 (p99_latency) 会与阈值进行比较。 - 时间戳列:对于时序图表 (折线图和堆叠条形图) ,系统会将结果中的 Date/DateTime 列识别为时间桶 (即时序图表的 x 轴) 。每个时间桶对应的值都会单独与阈值进行比较;如果任一时间桶的值超过已配置的阈值,就会触发告警。
- 分组列:任何非数值、非时间戳的列 (例如
ServiceName、Environment) 都会被视为分组维度。存在分组时,系统会分别跟踪每组唯一的分组值组合,并单独触发告警。对于值超过已配置阈值的每个分组,ClickStack 都会发送一条告警。分组仅适用于时序图表。
查询参数和宏
SQL 告警查询支持模板参数和宏,系统会在评估时自动将其替换。这些参数和宏与构建基于 SQL 的图表时可用的相同。
必需和推荐参数
用于折线图或堆叠条形图告警的查询必须包含时间间隔参数或宏 ({intervalSeconds:Int64}、{intervalMilliseconds:Int64}、$__timeInterval(col) 或 $__timeInterval_ms(col)) 。执行告警时,该参数或宏会被替换为告警配置的周期。
用于告警的查询应当包含时间范围过滤器 ({startDateMilliseconds:Int64} 和 {endDateMilliseconds:Int64},或 $__timeFilter(col) 等) 。无论查询中是否包含时间范围过滤器,告警查询都会按告警配置的周期运行。如果没有时间范围过滤器,则查询每次执行时都会读取源表中可用的整个时间范围的数据。
通常,告警查询每个时间间隔执行一次。但是,如果由于错误或查询过慢而跳过了一个或多个时间间隔,则下一次执行将使用包含这些遗漏时间间隔的时间范围。在这种情况下,查询的时间间隔参数仍会设置为告警配置的周期,但时间范围参数会反映更长的时间范围。
告警查询示例
每个服务的错误率 (时序)
当任一服务的错误率高于 5% 时触发告警;同时要求在告警周期内至少有 10 个请求,以避免低流量服务产生噪声告警。
显示类型:折线图或堆叠条形图
阈值:>= 5 (当错误速率达到 5% 时触发)
在此查询中,ServiceName 是一个非数值、非时间戳列,因此每个服务都会作为单独的告警组进行跟踪。告警会按服务分别独立触发。
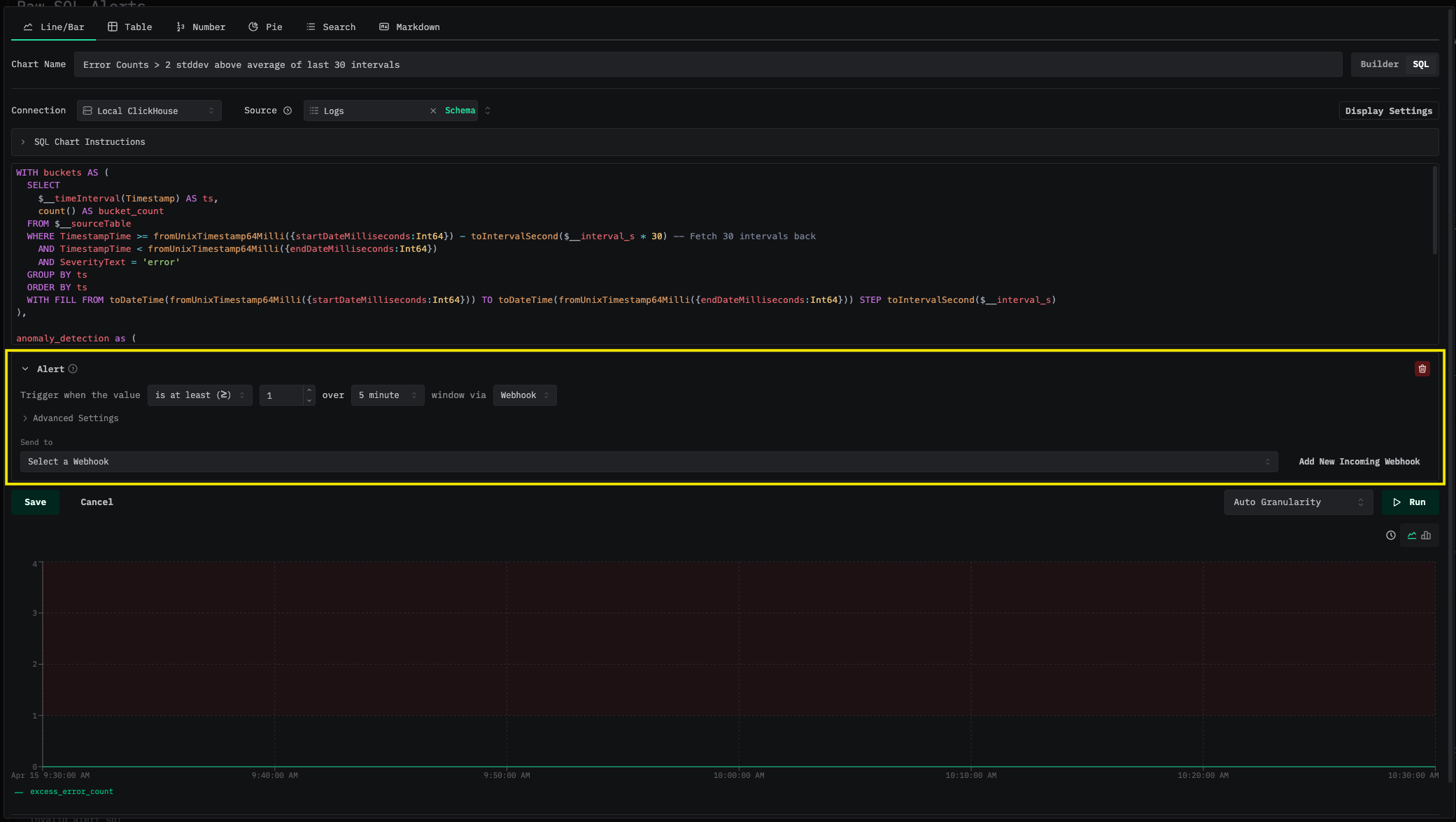
使用滞后平均值进行异常检测 (时序)
针对错误计数异常升高 (即超过滚动平均值两个标准差以上) 的情况设置告警。这样捕捉到的是相对于近期基线的突增,而不是依赖固定阈值。
显示类型: 折线图
阈值: > 0 (检测到超过滚动基线的额外错误时触发)
请注意,该查询会在日期范围开始之前额外拉取 30 个时间间隔的数据,以便为滚动窗口计算提供初始值,然后再将最终输出筛选为仅包含评估窗口内的数据。
常见告警场景
以下是一些可以使用 HyperDX 配置的常见告警场景:
错误: 建议为默认的 All Error Events 和 HTTP Status >= 400 这两个已保存搜索创建告警,以便在错误数量过多时收到通知。
慢操作: 可以为慢操作(例如 duration:>5000)创建搜索,并在慢操作数量过多时触发告警。
用户事件: 也可以为面向客户的团队设置告警,在有新用户注册或执行关键用户操作时收到通知。
