想了解更进阶的索引内容?
本页介绍 ClickHouse 的稀疏主索引,包括其构建方式、工作原理,以及如何提升查询性能。
如需了解更进阶的索引策略和更深入的技术细节,请参阅主索引深度剖析。
ClickHouse 中的稀疏主键索引是如何工作的?
ClickHouse 中的稀疏主键索引用于高效定位粒度 (granules) ——由多行组成的数据块——这些数据块可能包含满足查询在表主键列上条件的数据。下一节将说明该索引是如何根据这些列中的值构建的。
稀疏主索引的创建
为了演示稀疏主索引是如何构建的,我们会结合一些动画来说明 uk_price_paid_simple 表。
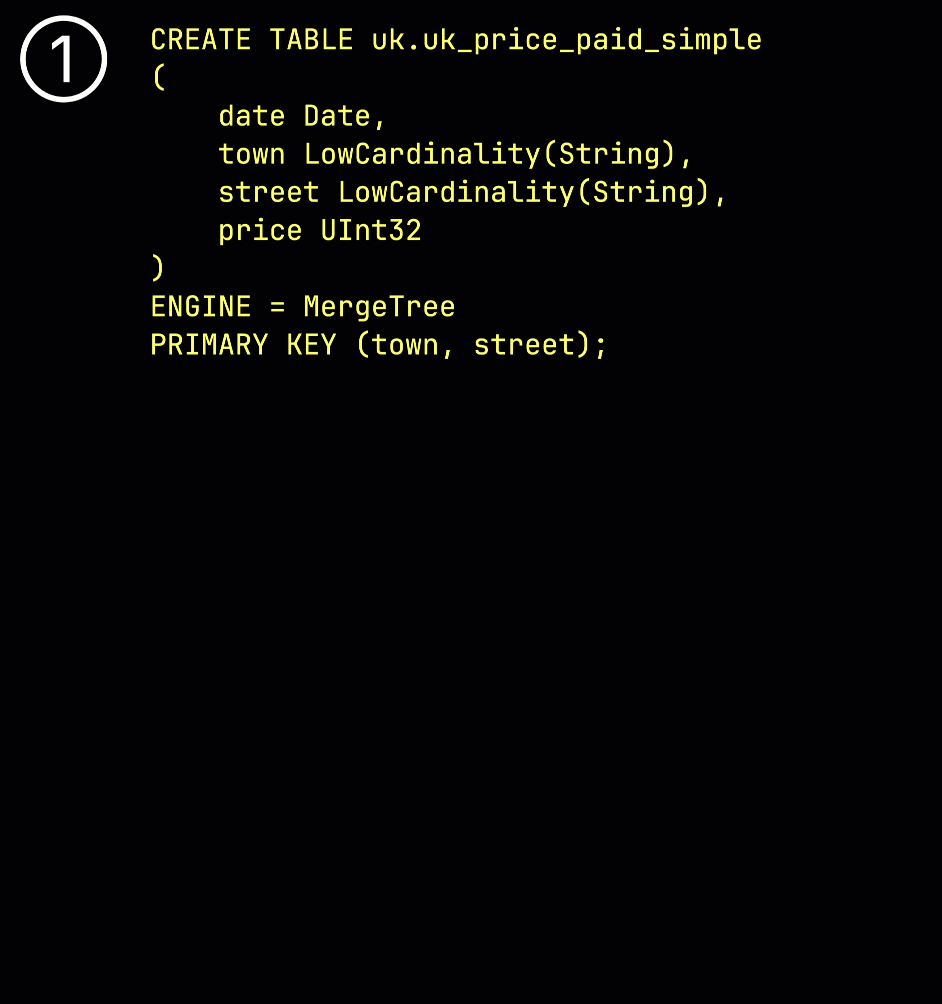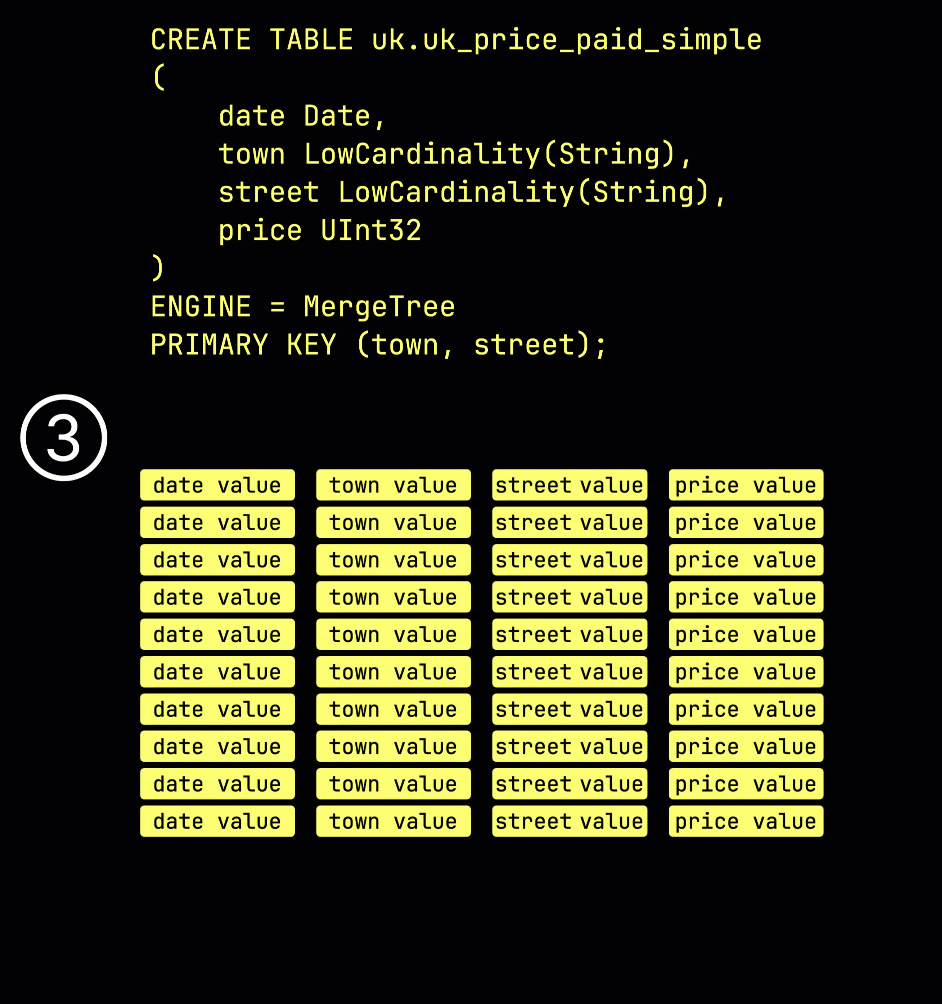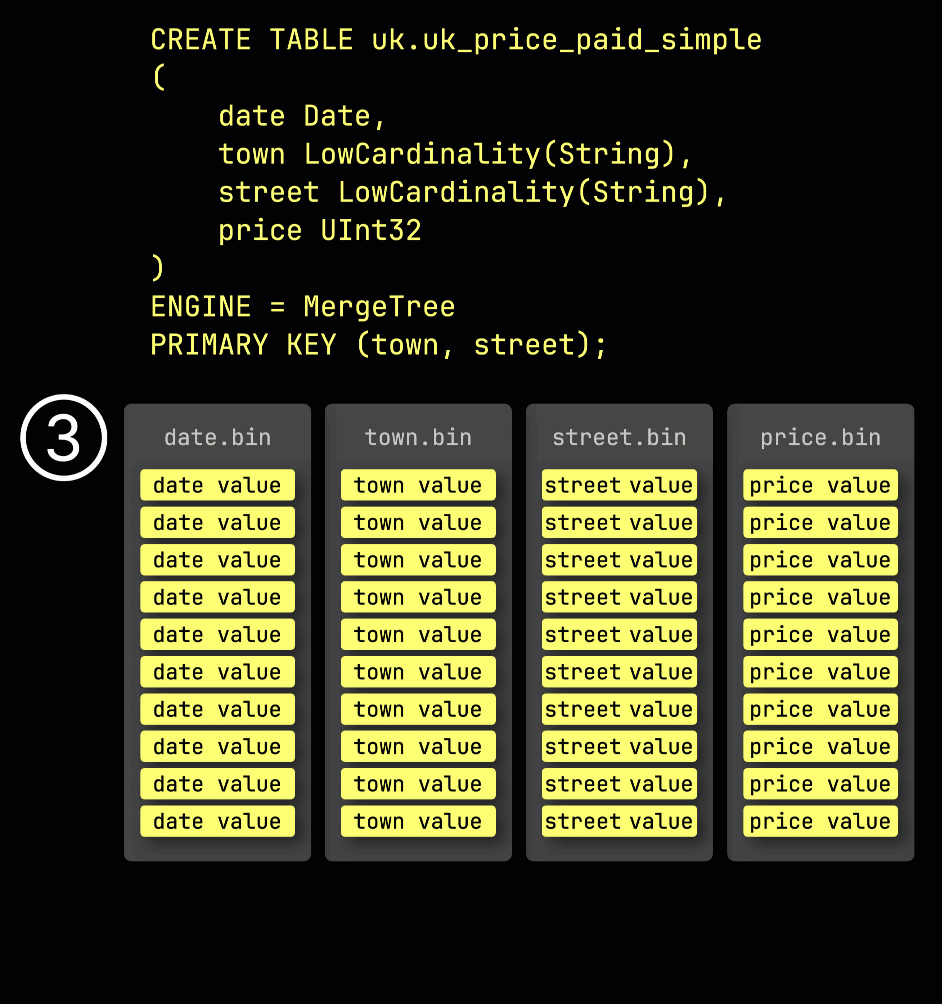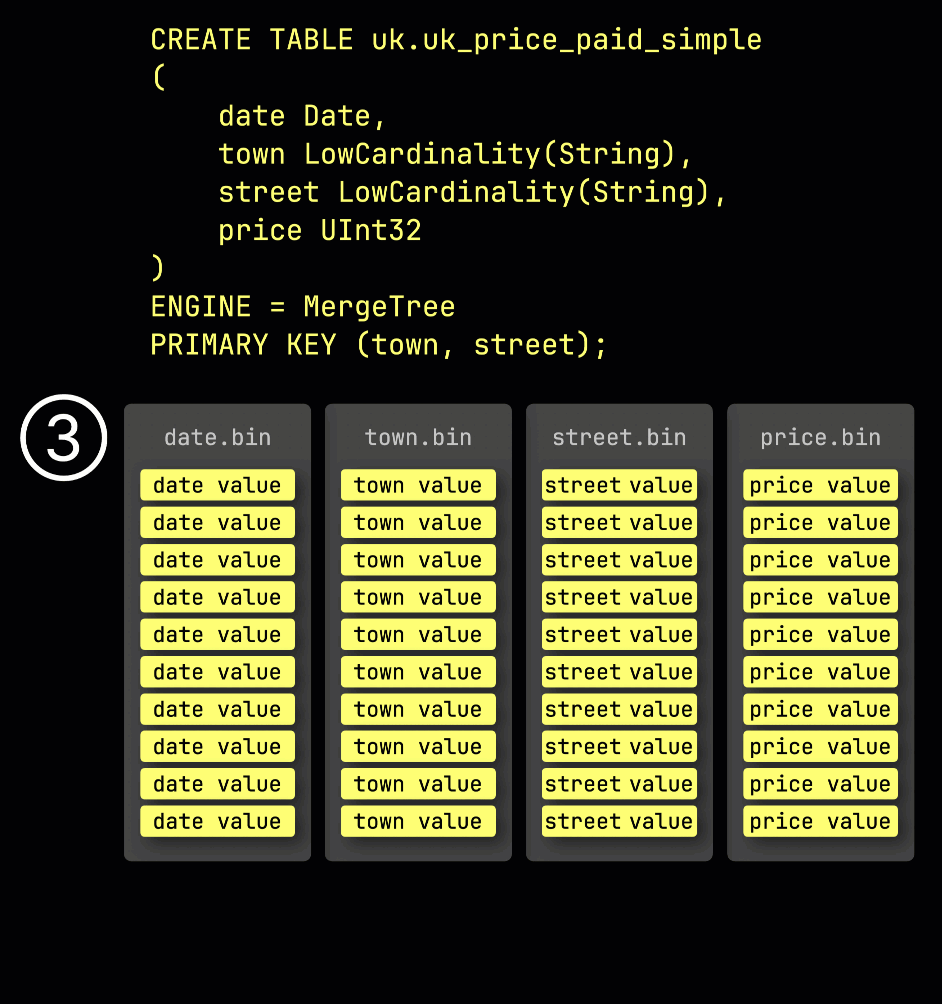
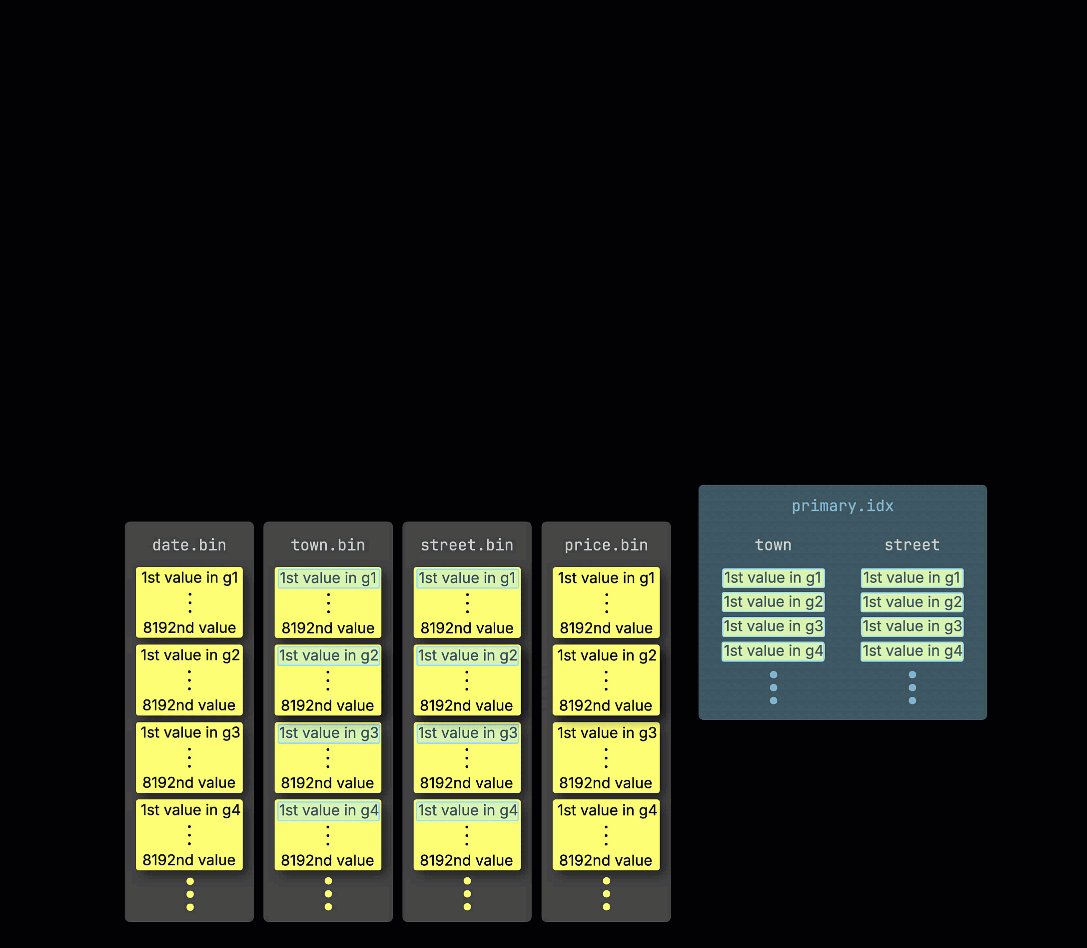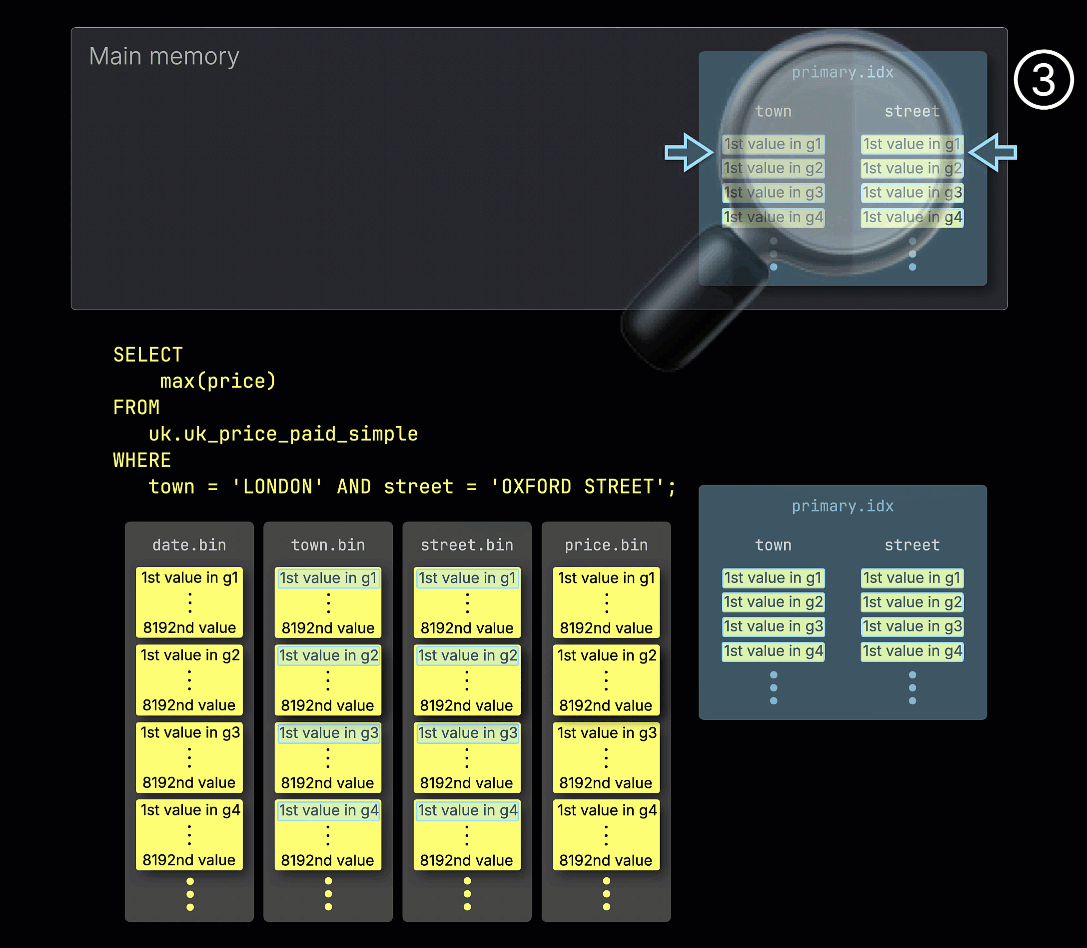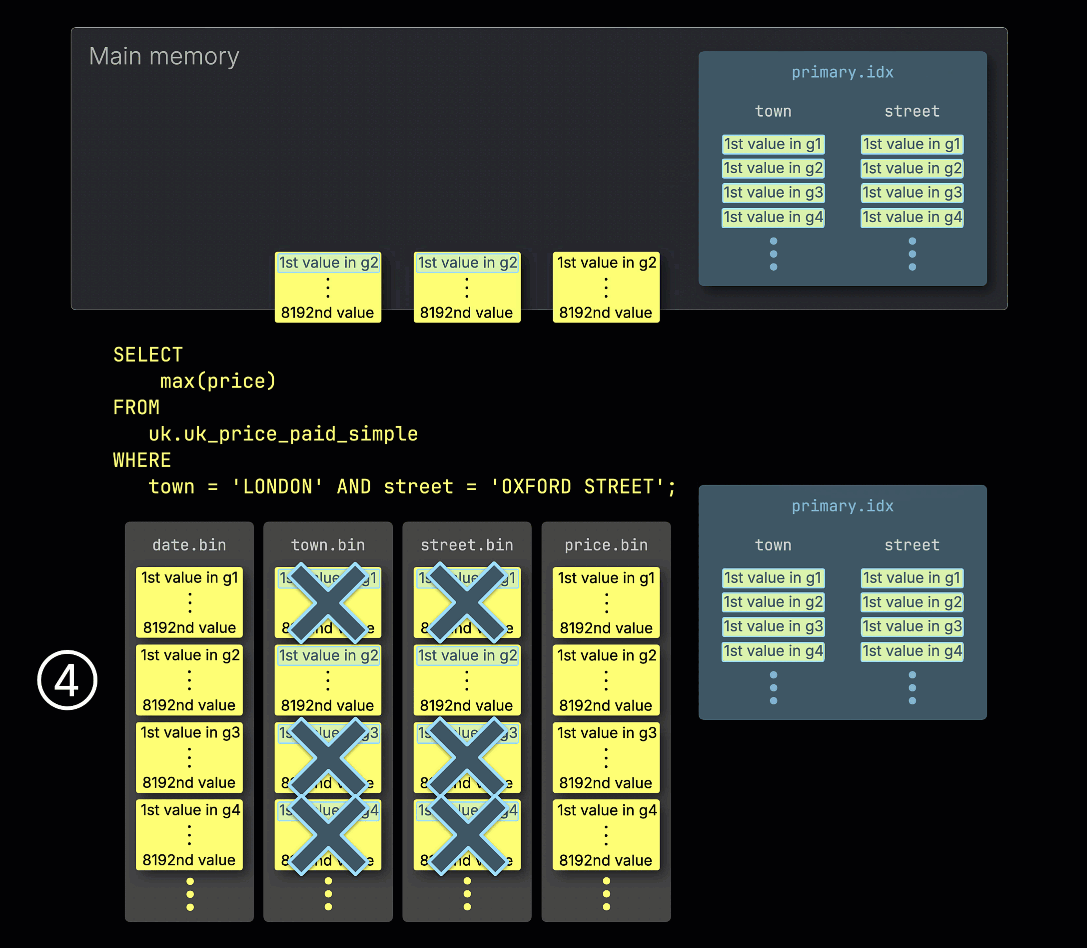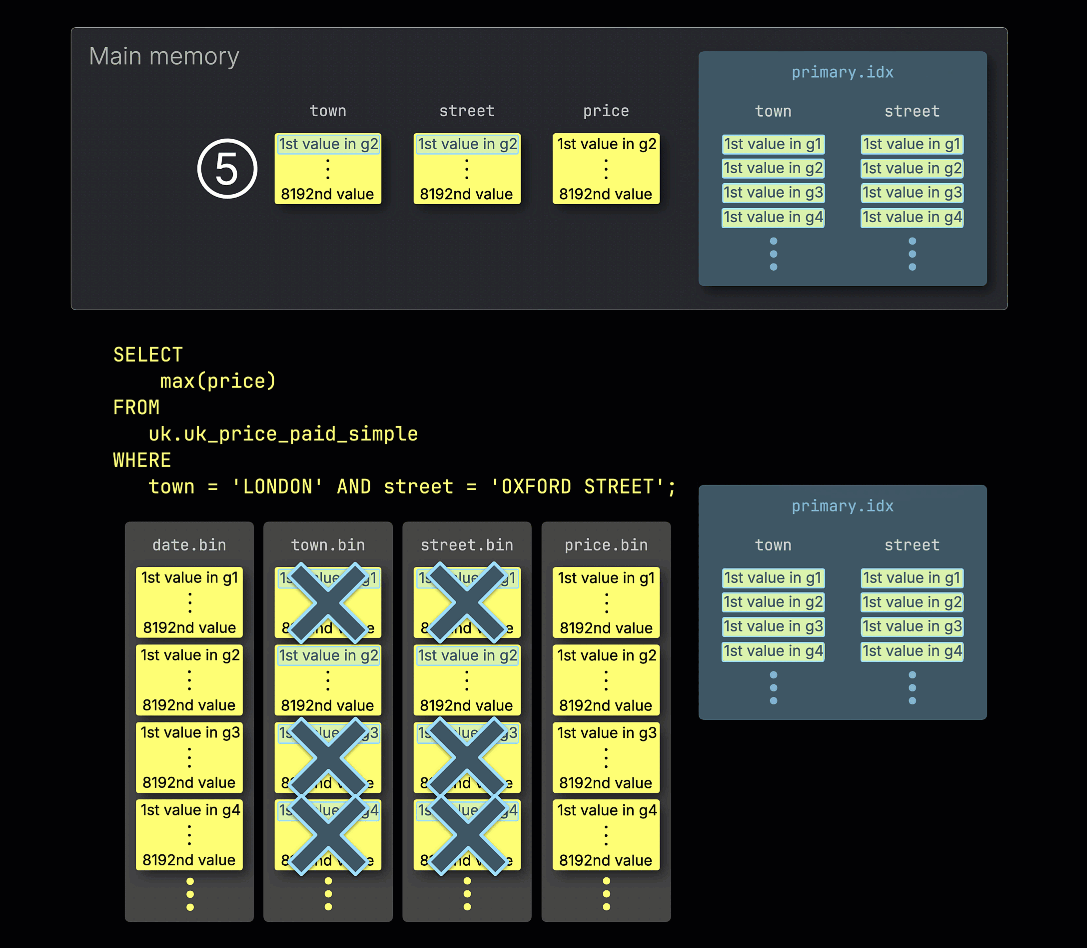
作为回顾,在我们的示例表①中,primary key 为 (town, street),② 插入的数据会被③存储到磁盘上,根据 primary key 列的取值排序并压缩,每一列单独存储在各自的文件中:
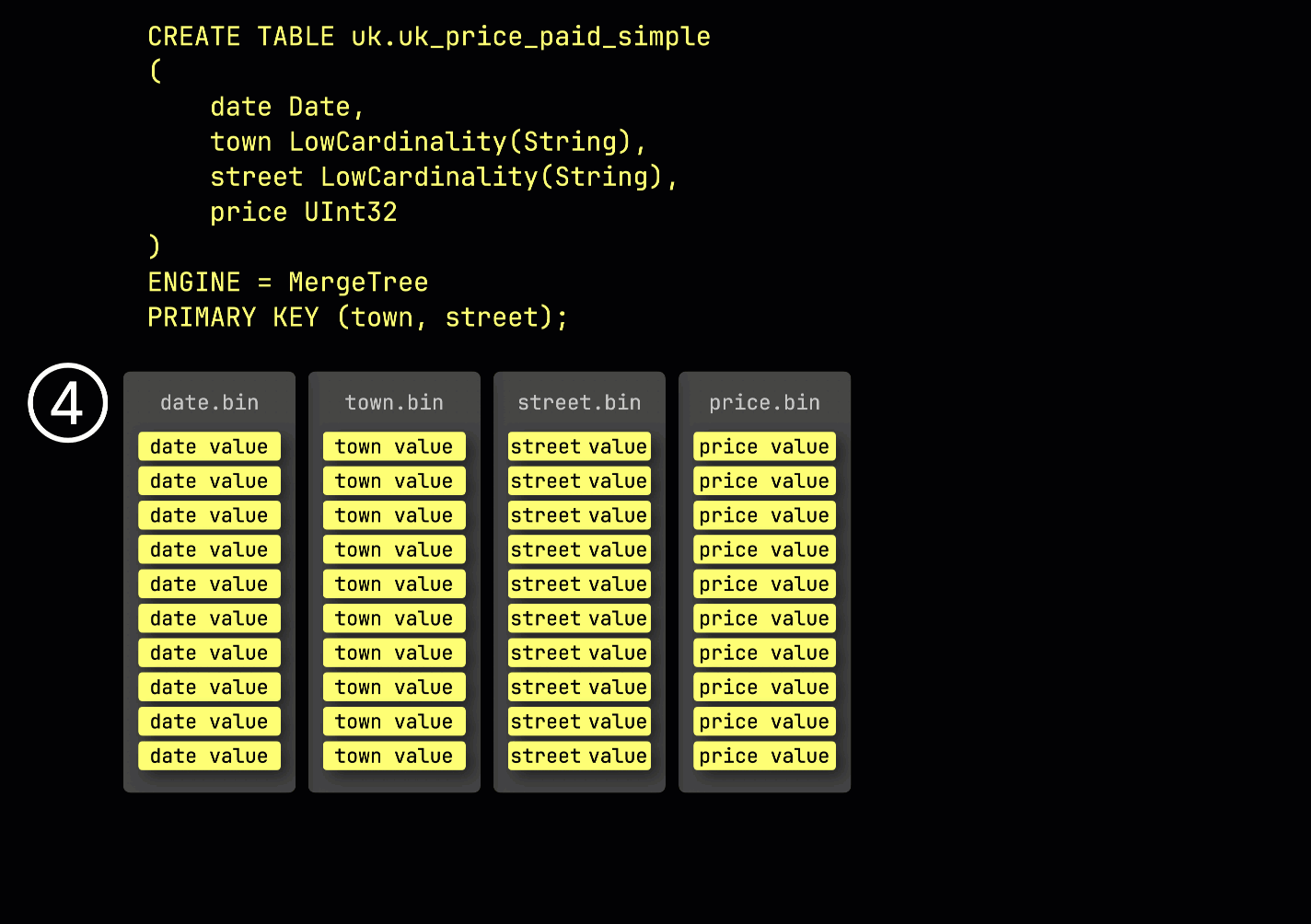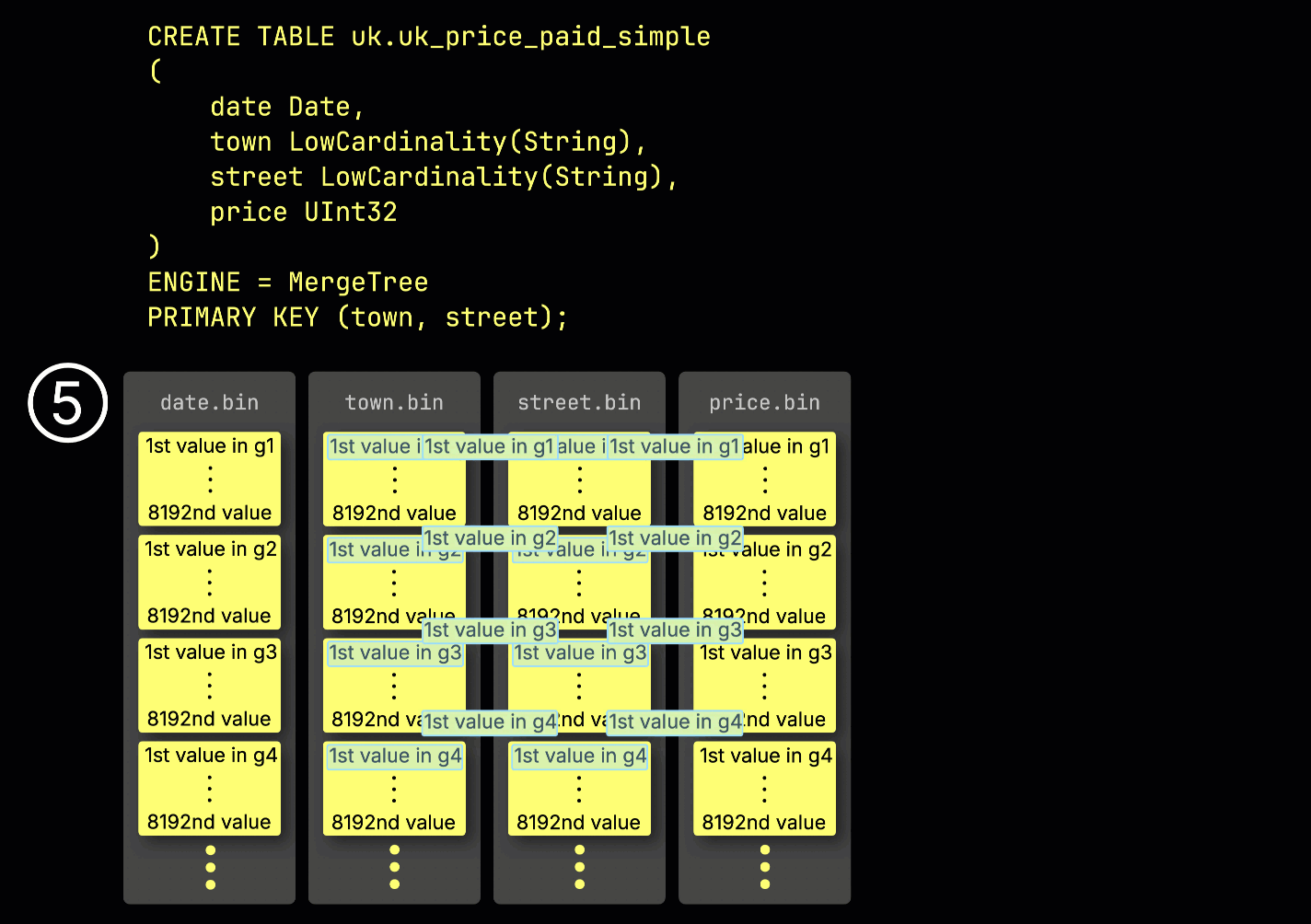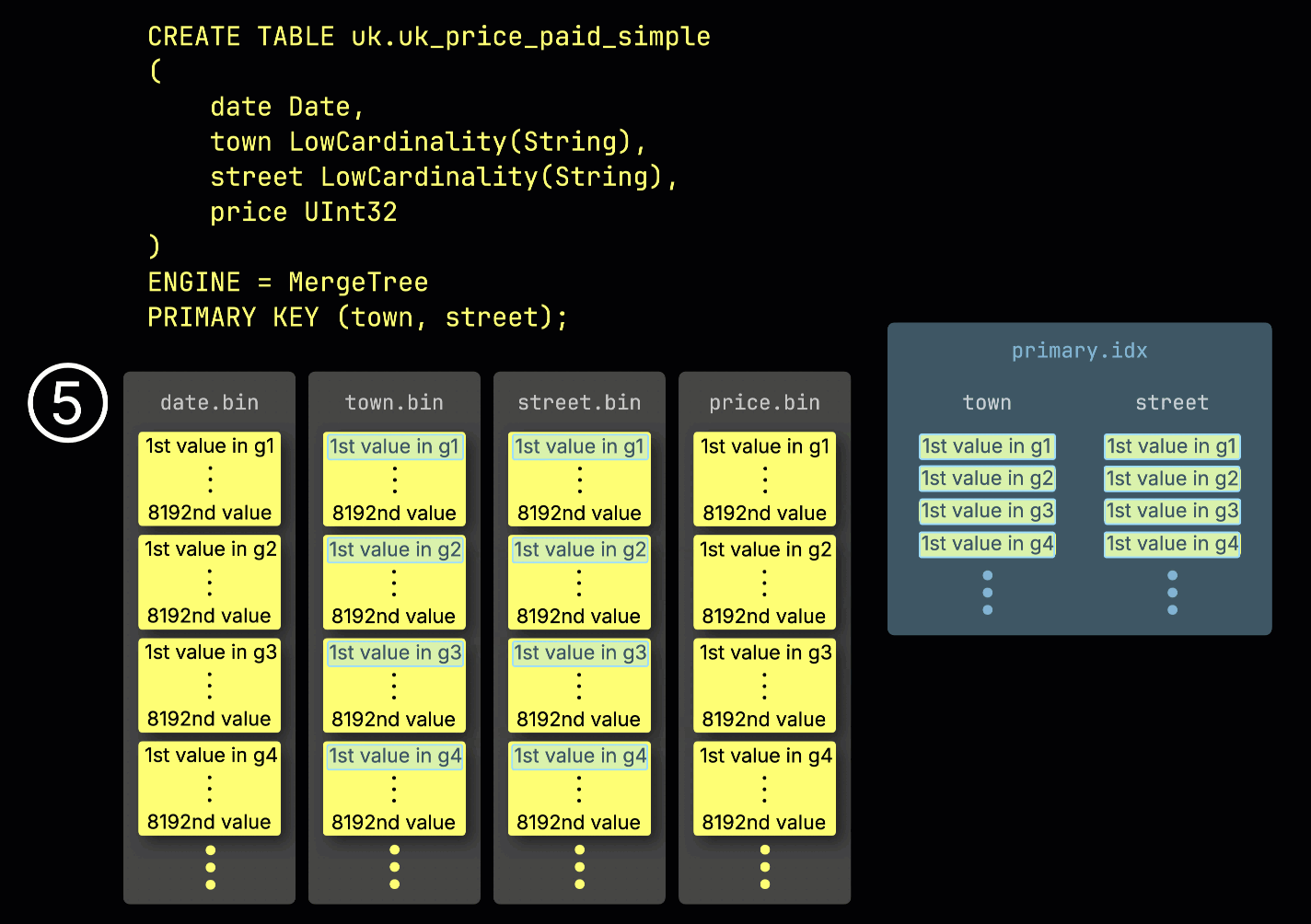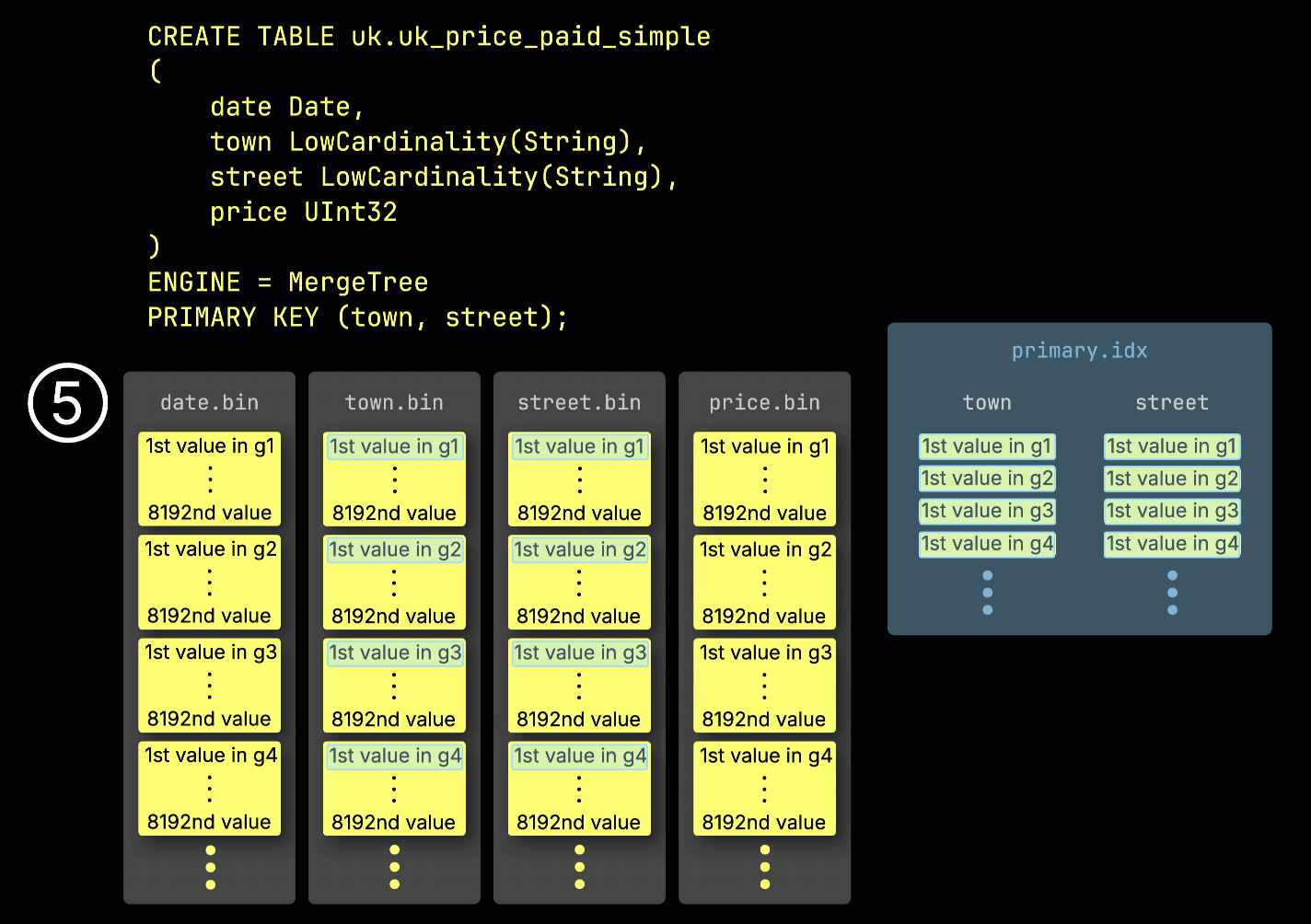
在处理时,每一列的数据会被④在逻辑上划分为多个 granule——每个 granule 覆盖 8,192 行——这是 ClickHouse 数据处理机制所使用的最小单元。
这种 granule 结构也是主索引之所以是稀疏的:ClickHouse 并不会为每一行建立索引,而是只存储每个 granule 中一行的 primary key 值——具体来说,是第一行的值。这样每个 granule 就对应一个索引项:
得益于这种稀疏性,主索引足够小,可以完整地放入内存中,从而为在 primary key 列上带有谓词条件的查询提供快速过滤。在下一节中,我们将展示它如何帮助加速此类查询。
主键索引的使用
下面通过另一段动画概述稀疏主键索引是如何用于加速查询的:
① 示例查询在两个主键列上都包含谓词:town = 'LONDON' AND street = 'OXFORD STREET'。
② 为了加速查询,ClickHouse 会将表的主键索引加载到内存中。
③ 随后,它会扫描索引项,以确定哪些粒度块可能包含与该谓词匹配的行——换句话说,哪些粒度块不能被跳过。
④ 然后将这些可能相关的粒度块,以及查询所需任何其他列中对应的粒度块,一并加载到内存中并进行处理。
监控主索引
表中的每个数据部分都有自己的主索引。我们可以使用 mergeTreeIndex 表函数来查看这些索引的内容。
下面的查询会列出示例表中每个数据部分的主索引中的条目数量:
SELECT
part_name,
max(mark_number) AS entries
FROM mergeTreeIndex('uk', 'uk_price_paid_simple')
GROUP BY part_name;
┌─part_name─┬─entries─┐
1. │ all_2_2_0 │ 914 │
2. │ all_1_1_0 │ 1343 │
3. │ all_0_0_0 │ 1349 │
└───────────┴─────────┘
此查询显示了当前某个数据部分的主索引中的前 10 条记录。请注意,这些部分会在后台持续被合并为更大的部分:
SELECT
mark_number + 1 AS entry,
town,
street
FROM mergeTreeIndex('uk', 'uk_price_paid_simple')
WHERE part_name = (SELECT any(part_name) FROM mergeTreeIndex('uk', 'uk_price_paid_simple'))
ORDER BY mark_number ASC
LIMIT 10;
┌─entry─┬─town───────────┬─street───────────┐
1. │ 1 │ ABBOTS LANGLEY │ ABBEY DRIVE │
2. │ 2 │ ABERDARE │ RICHARDS TERRACE │
3. │ 3 │ ABERGELE │ PEN Y CAE │
4. │ 4 │ ABINGDON │ CHAMBRAI CLOSE │
5. │ 5 │ ABINGDON │ THORNLEY CLOSE │
6. │ 6 │ ACCRINGTON │ MAY HILL CLOSE │
7. │ 7 │ ADDLESTONE │ HARE HILL │
8. │ 8 │ ALDEBURGH │ LINDEN ROAD │
9. │ 9 │ ALDERSHOT │ HIGH STREET │
10. │ 10 │ ALFRETON │ ALMA STREET │
└───────┴────────────────┴──────────────────┘
最后,我们使用 EXPLAIN 子句来查看所有数据部分的主索引如何用于跳过那些不可能包含符合示例查询谓词的行的粒度块。这些粒度块将不会被加载和处理:
EXPLAIN indexes = 1
SELECT
max(price)
FROM
uk.uk_price_paid_simple
WHERE
town = 'LONDON' AND street = 'OXFORD STREET';
┌─explain────────────────────────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Expression │
5. │ ReadFromMergeTree (uk.uk_price_paid_simple) │
6. │ Indexes: │
7. │ PrimaryKey │
8. │ Keys: │
9. │ town │
10. │ street │
11. │ Condition: and((street in ['OXFORD STREET', 'OXFORD STREET']), (town in ['LONDON', 'LONDON'])) │
12. │ Parts: 3/3 │
13. │ Granules: 3/3609 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
请注意,上面 EXPLAIN 输出的第 13 行显示,在所有数据 ^^parts^^ 中的 3,609 个 granule 里,只有 3 个被主键索引的分析选中参与处理。其余 granule 则被完全跳过。
我们还可以通过直接运行该查询来观察到,大部分数据都会被跳过:
SELECT max(price)
FROM uk.uk_price_paid_simple
WHERE (town = 'LONDON') AND (street = 'OXFORD STREET');
┌─max(price)─┐
1. │ 263100000 │ -- 2.631 亿
└────────────┘
返回 1 行。耗时:0.010 秒。已处理 24.58 千行,159.04 KB(253 万行/秒,16.35 MB/秒)。
峰值内存使用:13.00 MiB。
如上所示,在该示例表的大约 3,000 万行记录中,实际只处理了约 25,000 行:
SELECT count() FROM uk.uk_price_paid_simple;
┌──count()─┐
1. │ 29556244 │ -- 2956 万
└──────────┘
Key takeaways
-
稀疏主键索引帮助 ClickHouse 通过识别哪些粒度块可能包含在主键列上与查询条件匹配的行,从而跳过不必要的数据。
-
每个索引只存储每个粒度块首行的主键值(一个粒度块默认包含 8,192 行),因此足够紧凑,可以装入内存。
-
MergeTree 表中的每个数据 part都有其自己的主键索引,并在查询执行期间独立使用。
-
在查询过程中,索引使 ClickHouse 能够跳过粒度块,从而降低 I/O 和内存使用,同时提升性能。
-
你可以使用 mergeTreeIndex 表函数来检查索引内容,并通过 EXPLAIN 子句监控索引使用情况。
若想更深入了解 ClickHouse 中稀疏主键索引的工作机制,包括其与传统数据库索引的差异以及使用它们的最佳实践,请查阅我们的索引深度解析。
如果你对 ClickHouse 如何以高度并行的方式处理经主键索引扫描选取的数据感兴趣,请参阅查询并行性指南。