本文是从 PostgreSQL 迁移到 ClickHouse 指南的第一部分。通过一个实际示例,演示如何采用实时复制(CDC)方案高效完成迁移。文中涉及的许多概念同样适用于从 PostgreSQL 到 ClickHouse 的手动批量数据传输。
数据集
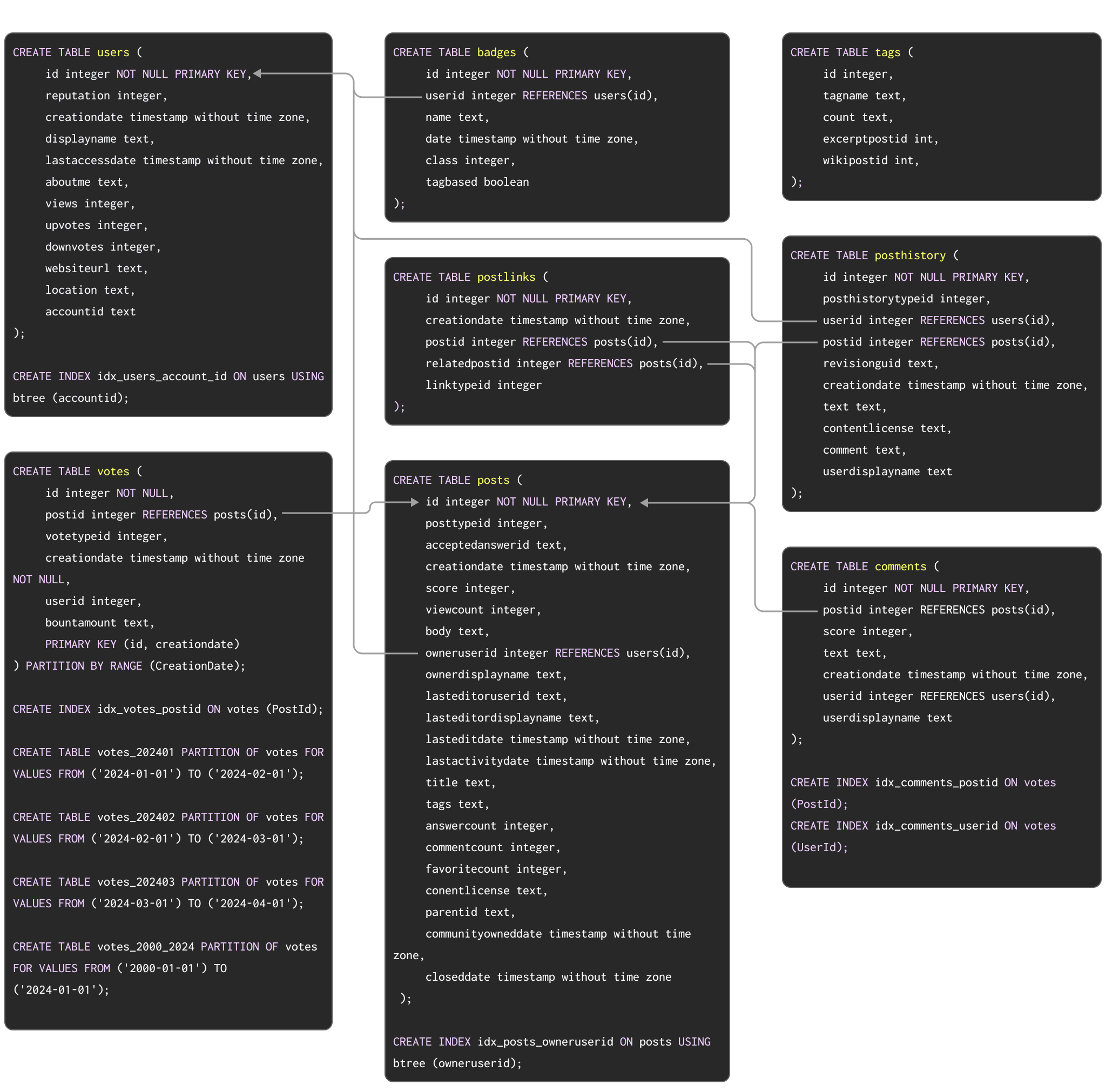
作为一个用于展示从 Postgres 迁移到 ClickHouse 的典型过程的示例数据集,我们使用了 此处 文档化的 Stack Overflow 数据集。该数据集包含从 2008 年到 2024 年 4 月期间在 Stack Overflow 上产生的每一条 post、vote、user、comment 和 badge。该数据在 PostgreSQL 中的模式(schema)如下所示:
用于在 PostgreSQL 中创建这些表的 DDL 命令可在 此处 获取。
该模式虽然不一定是最优的,但利用了多个常用的 PostgreSQL 特性,包括主键、外键、分区以及索引。
我们将把这些概念逐一迁移到它们在 ClickHouse 中的对应实现。
对于希望将该数据集导入 PostgreSQL 实例以测试迁移步骤的用户,我们提供了包含 DDL 的 pg_dump 格式数据供下载,后续的数据加载命令如下所示:
# users
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/users.sql.gz
gzip -d users.sql.gz
psql < users.sql
# posts
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/posts.sql.gz
gzip -d posts.sql.gz
psql < posts.sql
# posthistory
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/posthistory.sql.gz
gzip -d posthistory.sql.gz
psql < posthistory.sql
# comments
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/comments.sql.gz
gzip -d comments.sql.gz
psql < comments.sql
# votes
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/votes.sql.gz
gzip -d votes.sql.gz
psql < votes.sql
# badges
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/badges.sql.gz
gzip -d badges.sql.gz
psql < badges.sql
# postlinks
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/postlinks.sql.gz
gzip -d postlinks.sql.gz
psql < postlinks.sql
对于 ClickHouse 来说该数据集算小,但对于 Postgres 来说已经相当可观。上述内容表示的是覆盖 2024 年前 3 个月的一个子集。
虽然我们的示例结果使用完整数据集来展示 Postgres 与 ClickHouse 之间的性能差异,但下文记录的所有步骤在较小子集上执行时在功能上是完全相同的。希望将完整数据集加载到 Postgres 的用户请参见此处。由于上述模式中施加的外键约束,PostgreSQL 的完整数据集仅包含满足引用完整性的行。一个不包含此类约束的 Parquet 版本 可以在需要时直接加载到 ClickHouse 中。
迁移数据
实时复制(CDC)
请参阅此指南,为 PostgreSQL 配置 ClickPipes。该指南涵盖了多种不同类型的 Postgres 源实例。
使用基于 CDC 的方式(通过 ClickPipes 或 PeerDB),PostgreSQL 数据库中的每个表都会自动复制到 ClickHouse 中。
为了在接近实时的情况下处理更新和删除操作,ClickPipes 会将 Postgres 表映射为使用 ReplacingMergeTree 引擎的 ClickHouse 表,该引擎专门用于在 ClickHouse 中处理更新和删除。你可以在这里了解通过 ClickPipes 将数据复制到 ClickHouse 的更多信息。需要特别注意的是,使用 CDC 进行复制时,在同步更新或删除操作时会在 ClickHouse 中产生重复行。请参考这些处理方法,通过使用 FINAL 修饰符在 ClickHouse 中消除这些重复数据。
下面来看一下使用 ClickPipes 在 ClickHouse 中创建 users 表的方式。
CREATE TABLE users
(
`id` Int32,
`reputation` String,
`creationdate` DateTime64(6),
`displayname` String,
`lastaccessdate` DateTime64(6),
`aboutme` String,
`views` Int32,
`upvotes` Int32,
`downvotes` Int32,
`websiteurl` String,
`location` String,
`accountid` Int32,
`_peerdb_synced_at` DateTime64(9) DEFAULT now64(),
`_peerdb_is_deleted` Int8,
`_peerdb_version` Int64
)
ENGINE = ReplacingMergeTree(_peerdb_version)
PRIMARY KEY id
ORDER BY id;
完成设置后,ClickPipes 会开始将 PostgreSQL 中的所有数据迁移到 ClickHouse。根据网络状况和部署规模,对于 Stack Overflow 数据集,这通常只需要几分钟。
手动批量加载与定期更新
采用手动方式时,可以通过以下方法完成数据集的初始批量加载:
- 表函数(Table functions) - 在 ClickHouse 中使用 Postgres 表函数,从 Postgres 中执行
SELECT 并将结果 INSERT 到 ClickHouse 表中。适用于数百 GB 级别数据集的批量加载。
- 导出(Exports) - 导出为诸如 CSV 或 SQL 脚本文件等中间格式。然后可以通过客户端使用
INSERT FROM INFILE 子句,或借助对象存储及其相关函数(例如 s3、gcs)将这些文件加载到 ClickHouse 中。
当从 PostgreSQL 手动加载数据时,需要先在 ClickHouse 中创建表。请参考这份同样使用 Stack Overflow 数据集、用于在 ClickHouse 中优化表结构的 数据建模文档。
PostgreSQL 与 ClickHouse 之间的数据类型可能不同。要为每个表列确定对应的数据类型,可以将 DESCRIBE 命令与 Postgres 表函数 结合使用。以下命令用于查看 PostgreSQL 中 posts 表的结构,请根据你的环境进行修改:
DESCRIBE TABLE postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
SETTINGS describe_compact_output = 1
关于 PostgreSQL 与 ClickHouse 之间数据类型映射的概览,请参阅附录文档。
针对该 schema 优化数据类型的步骤,与从其他数据源(例如 S3 上的 Parquet)加载数据时完全相同。按照使用 Parquet 的替代指南中描述的流程操作,将得到如下 schema:
CREATE TABLE stackoverflow.posts
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
COMMENT 'Optimized types'
我们可以使用一个简单的 INSERT INTO SELECT 语句,从 PostgreSQL 读取数据并插入到 ClickHouse 中:
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
0 rows in set. Elapsed: 146.471 sec. Processed 59.82 million rows, 83.82 GB (408.40 thousand rows/s., 572.25 MB/s.)
增量加载反过来也可以进行调度。如果 Postgres 表只接收插入操作,并且存在递增的 id 或时间戳,则可以使用上述表函数方式来加载增量数据,即在 SELECT 中应用 WHERE 子句。若更新操作可以保证只更新同一列,此方法也可以用于支持更新。然而,要支持删除操作则需要进行完整重新加载,而随着表规模增长,这可能会变得难以实现。
我们使用 CreationDate 来演示一次初始加载和后续的增量加载(我们假设当行被更新时,该字段也会更新)。
-- initial load
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>', 'postgres', 'posts', 'postgres', '<password')
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>', 'postgres', 'posts', 'postgres', '<password') WHERE CreationDate > ( SELECT (max(CreationDate) FROM stackoverflow.posts)
ClickHouse 会将简单的 WHERE 子句(例如 =, !=, >, >=, <, <= 和 IN)下推至 PostgreSQL 服务器。通过确保在用于标识变更集的列上建立索引,可以让增量加载更加高效。
在使用查询复制时,一种检测 UPDATE 操作的可行方法是使用 XMIN 系统列(事务 ID)作为水位线——该列的变化表明发生了变更,因此可以将其应用到目标表。采用此方法的用户应注意,XMIN 值可能会发生回绕,并且比较操作需要对整张表进行扫描,从而使变更跟踪变得更加复杂。
点击这里查看第 2 部分