从 BigQuery 迁移到 ClickHouse Cloud
为什么选择 ClickHouse Cloud 而不是 BigQuery?
简而言之:在现代数据分析场景中,ClickHouse 比 BigQuery 更快、更便宜,也更强大:
从 BigQuery 向 ClickHouse Cloud 加载数据
数据集
作为展示从 BigQuery 迁移到 ClickHouse Cloud 典型流程的示例数据集,我们使用了 Stack Overflow 数据集,相关说明文档见此处。该数据集包含自 2008 年至 2024 年 4 月期间出现在 Stack Overflow 上的每条 post、vote、user、comment 和 badge。该数据在 BigQuery 中的 schema 如下所示:
对于希望在自己的 BigQuery 实例中填充该数据集以测试迁移步骤的用户,我们在一个 GCS bucket 中提供了这些表的 Parquet 格式数据,并提供了在 BigQuery 中创建并加载这些表的 DDL 命令,详见此处。
数据迁移
在 BigQuery 和 ClickHouse Cloud 之间迁移数据,大致可以分为两类主要工作负载模式:
- 初始批量加载与周期性更新 - 首先需要迁移一个初始数据集,随后按照固定周期(例如每天)执行更新。这里的更新通过重新发送已发生变更的行来处理——这些行通常通过某个可用于比较的列(例如日期列)来识别。删除操作则通过周期性地对整个数据集执行完全重新加载来处理。
- 实时复制或 CDC - 首先需要迁移一个初始数据集。随后对该数据集的变更必须在 ClickHouse 中实现近实时反映,只允许数秒级的延迟。这实质上是一个CDC(变更数据捕获)流程,即 BigQuery 中的表必须与 ClickHouse 中的表保持同步,也就是说,BigQuery 表中的插入、更新和删除必须应用到 ClickHouse 中对应的表上。
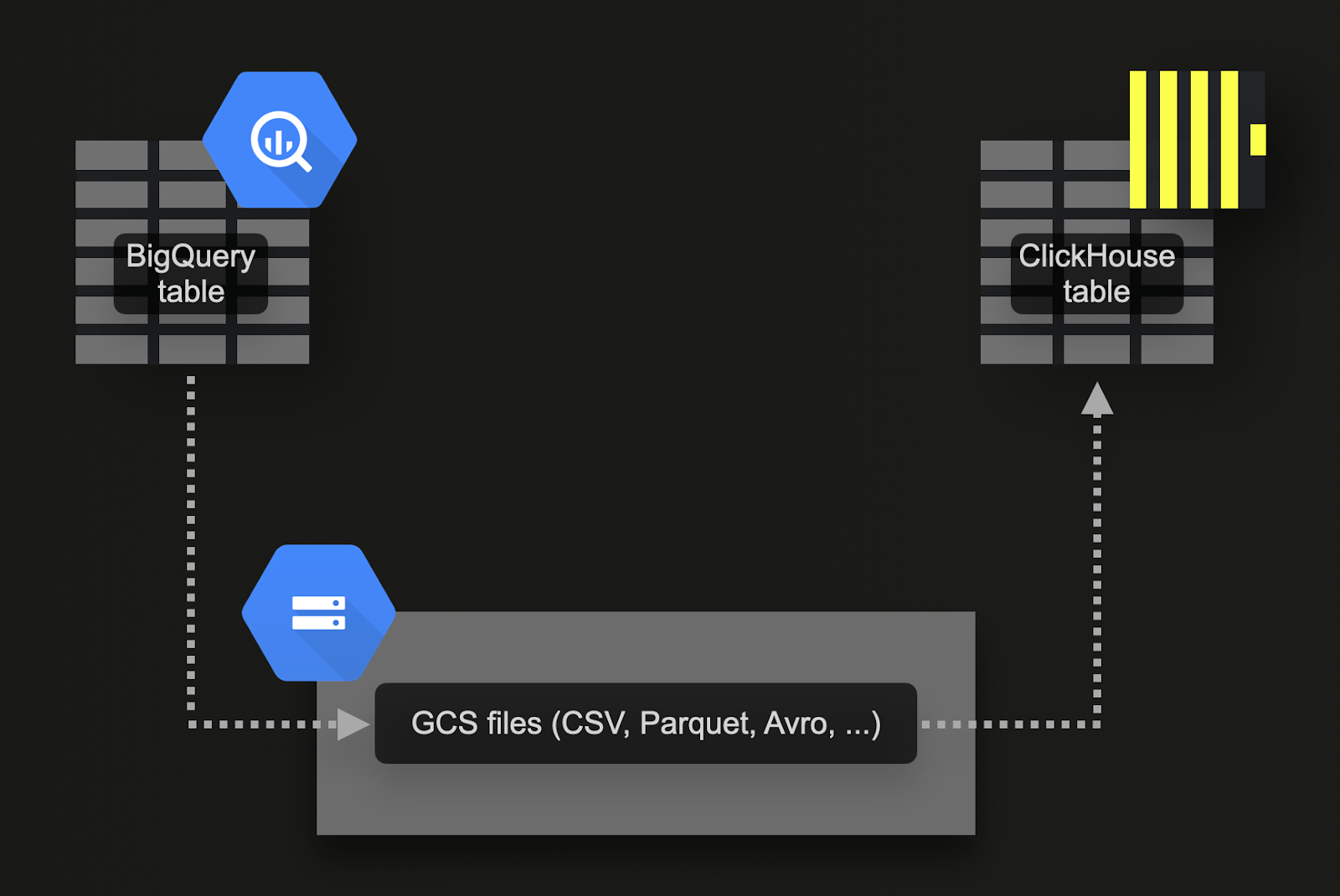
通过 Google Cloud Storage(GCS)进行批量加载
BigQuery 支持将数据导出到 Google 的对象存储服务(GCS)。针对我们的示例数据集:
-
将这 7 张表导出到 GCS。相关命令可在此处获取。
-
将数据导入到 ClickHouse Cloud。为此我们可以使用 gcs 表函数。对应的 DDL 语句和导入查询可在此处获取。请注意,由于一个 ClickHouse Cloud 实例由多个计算节点组成,我们并未直接使用 gcs 表函数,而是使用了 s3Cluster 表函数。该函数同样支持 GCS bucket,并且利用 ClickHouse Cloud 服务中的所有节点以并行方式加载数据。
该方法具有如下优势:
在尝试以下示例之前,我们建议用户先查看导出所需权限和数据位置方面的建议,以最大化导出与导入性能。
通过计划查询实现实时复制或 CDC
CDC(变更数据捕获)是指在两个数据库之间保持表数据同步的过程。如果需要在近实时场景下处理更新和删除操作,这会变得更加复杂。一种方法是简单地利用 BigQuery 的计划查询功能定期导出数据。只要能够接受数据在插入 ClickHouse 时存在一定延迟,这种方法就非常容易实现和维护。示例见这篇博客文章。
模式设计
Stack Overflow 数据集包含许多相关的表。我们建议优先迁移主表。这不一定是最大的那张表,而是您预计会收到最多分析查询的那张表。这样可以帮助您熟悉 ClickHouse 的核心概念。随着后续添加更多表,为了充分利用 ClickHouse 的特性并获得最佳性能,可能需要对该表进行重新建模。我们在数据建模文档中对这一建模过程进行了探讨。
遵循这一原则,我们重点关注主表 posts。其在 BigQuery 中的模式如下所示:
CREATE TABLE stackoverflow.posts (
id INTEGER,
posttypeid INTEGER,
acceptedanswerid STRING,
creationdate TIMESTAMP,
score INTEGER,
viewcount INTEGER,
body STRING,
owneruserid INTEGER,
ownerdisplayname STRING,
lasteditoruserid STRING,
lasteditordisplayname STRING,
lasteditdate TIMESTAMP,
lastactivitydate TIMESTAMP,
title STRING,
tags STRING,
answercount INTEGER,
commentcount INTEGER,
favoritecount INTEGER,
conentlicense STRING,
parentid STRING,
communityowneddate TIMESTAMP,
closeddate TIMESTAMP
);
优化数据类型
按照此处所述的流程进行后,将得到如下模式:
CREATE TABLE stackoverflow.posts
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
COMMENT 'Optimized types'
我们可以使用一个简单的 INSERT INTO SELECT,通过 gcs 表函数 从 GCS 读取导出的数据来填充此表。请注意,在 ClickHouse Cloud 上还可以使用与 GCS 兼容的 s3Cluster 表函数,在多个节点上并行加载数据:
INSERT INTO stackoverflow.posts SELECT * FROM gcs( 'gs://clickhouse-public-datasets/stackoverflow/parquet/posts/*.parquet', NOSIGN);
在我们的新模式中不会保留任何 null 值。上面的 insert 语句会将这些值隐式转换为其各自类型的默认值——整数为 0,字符串为空字符串。ClickHouse 还会自动将所有数值类型转换为其目标精度。
ClickHouse 主键有何不同?
如此处所述,与 BigQuery 一样,ClickHouse 不会对表主键列的取值强制唯一性。
与 BigQuery 中的分簇 (clustering) 类似,ClickHouse 表的数据在磁盘上按照主键列的顺序进行存储。查询优化器会利用这一排序来避免重新排序、减少用于连接的内存占用,并支持对 limit 子句进行短路执行。
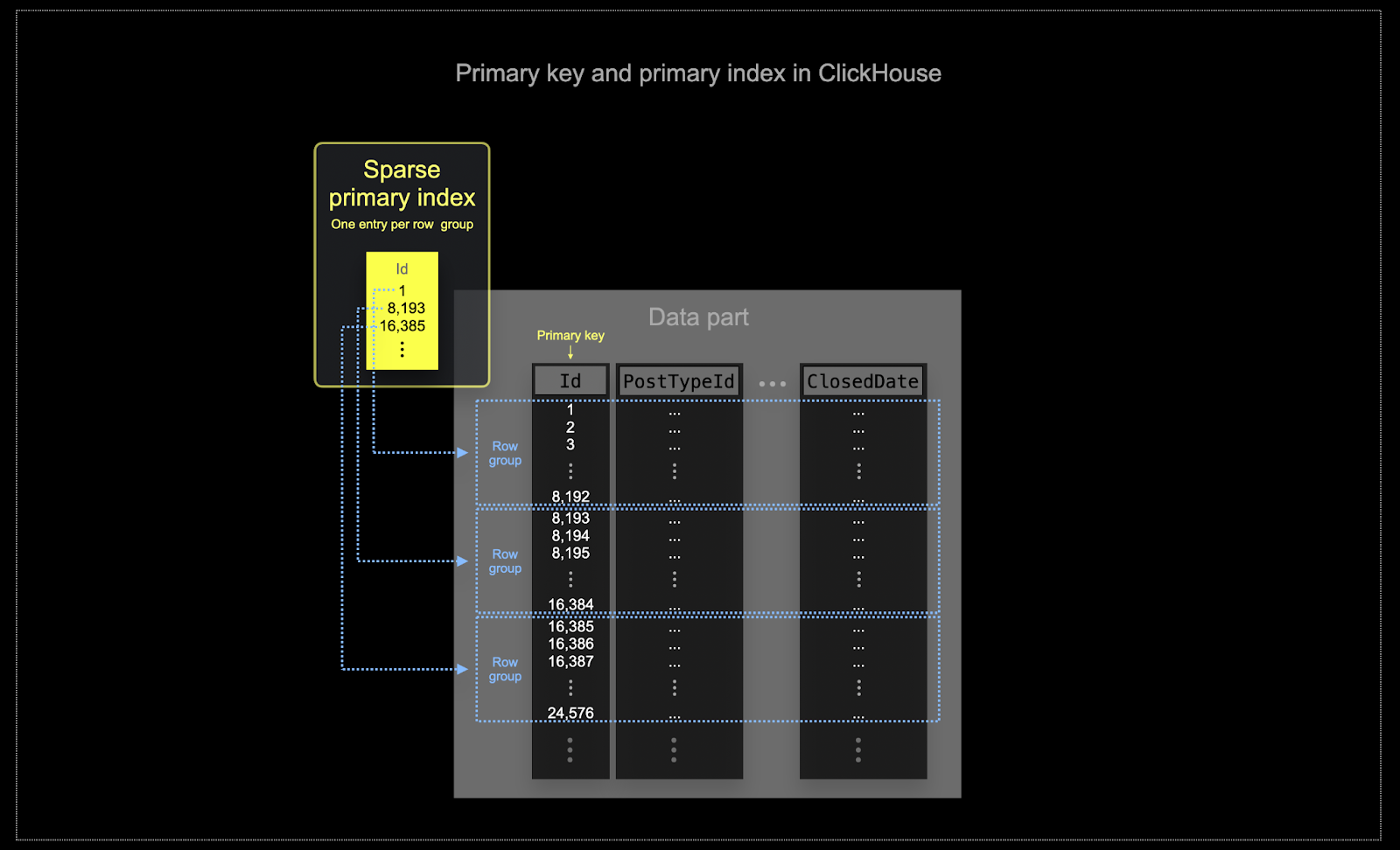
与 BigQuery 不同,ClickHouse 会基于主键列值自动创建 (稀疏) 主索引。该索引用于加速所有包含主键列过滤条件的查询。具体来说:
- 内存和磁盘效率对于 ClickHouse 常见的使用规模至关重要。数据以称为 part 的数据块写入 ClickHouse 表,并在后台根据一定规则对 part 进行合并。在 ClickHouse 中,每个 part 都有自己的主索引。当 part 被合并时,合并后 part 的主索引也会被合并。请注意,这些索引并不是为每一行构建的,而是一个 part 的主索引是每一组行对应一个索引条目——这种技术称为稀疏索引。
- 稀疏索引之所以可行,是因为 ClickHouse 会按照指定的键在磁盘上存储一个 part 的行。稀疏主索引并不是像基于 B-Tree 的索引那样直接定位单行数据,而是通过对索引条目做二分查找,快速定位可能匹配查询的行组。然后,这些被定位出的潜在匹配行组会并行地以流式方式送入 ClickHouse 引擎,以查找真正的匹配。这样的索引设计使主索引可以保持较小 (完全常驻于主内存中) ,同时显著加速查询执行时间,尤其是数据分析场景中常见的范围查询。更多细节请参考这篇深入指南。
在 ClickHouse 中,所选择的主键不仅决定索引本身,还会决定数据写入磁盘的顺序。由于这一点,它会显著影响压缩率,进而影响查询性能。使大多数字段的值以连续顺序写入的排序键,将有利于所选压缩算法 (以及编码器) 更高效地压缩数据。
表中的所有列都会根据指定排序键的值进行排序,而不论这些列本身是否包含在排序键中。例如,如果使用 CreationDate 作为排序键,那么所有其他列中的取值顺序将与 CreationDate 列中的值顺序保持一致。可以指定多个排序键——其排序语义与 SELECT 查询中的 ORDER BY 子句相同。
选择排序键
有关选择排序键时的考量因素和具体步骤,并以 posts 表为例进行说明,请参见此处。
数据建模技术
我们建议从 BigQuery 迁移的用户阅读在 ClickHouse 中进行数据建模的指南。该指南使用相同的 Stack Overflow 数据集,并结合 ClickHouse 的特性来探索多种建模方法。
BigQuery 用户应该已经熟悉表分区的概念:通过将表拆分为更小、更易管理的部分(称为分区),来提升大型数据库的性能和可管理性。分区可以通过在指定列(例如日期)上使用范围分区、定义列表分区,或者基于键的哈希分区来实现。这使得管理员可以根据特定条件(例如日期范围或地理位置)来组织数据。
分区有助于通过分区裁剪和更高效的索引来提升查询性能。它还可以简化备份和数据清理等维护任务,因为这些操作可以针对单个分区执行,而不必作用于整张表。此外,通过将负载分布到多个分区,分区还能显著提升 BigQuery 数据库的可扩展性。
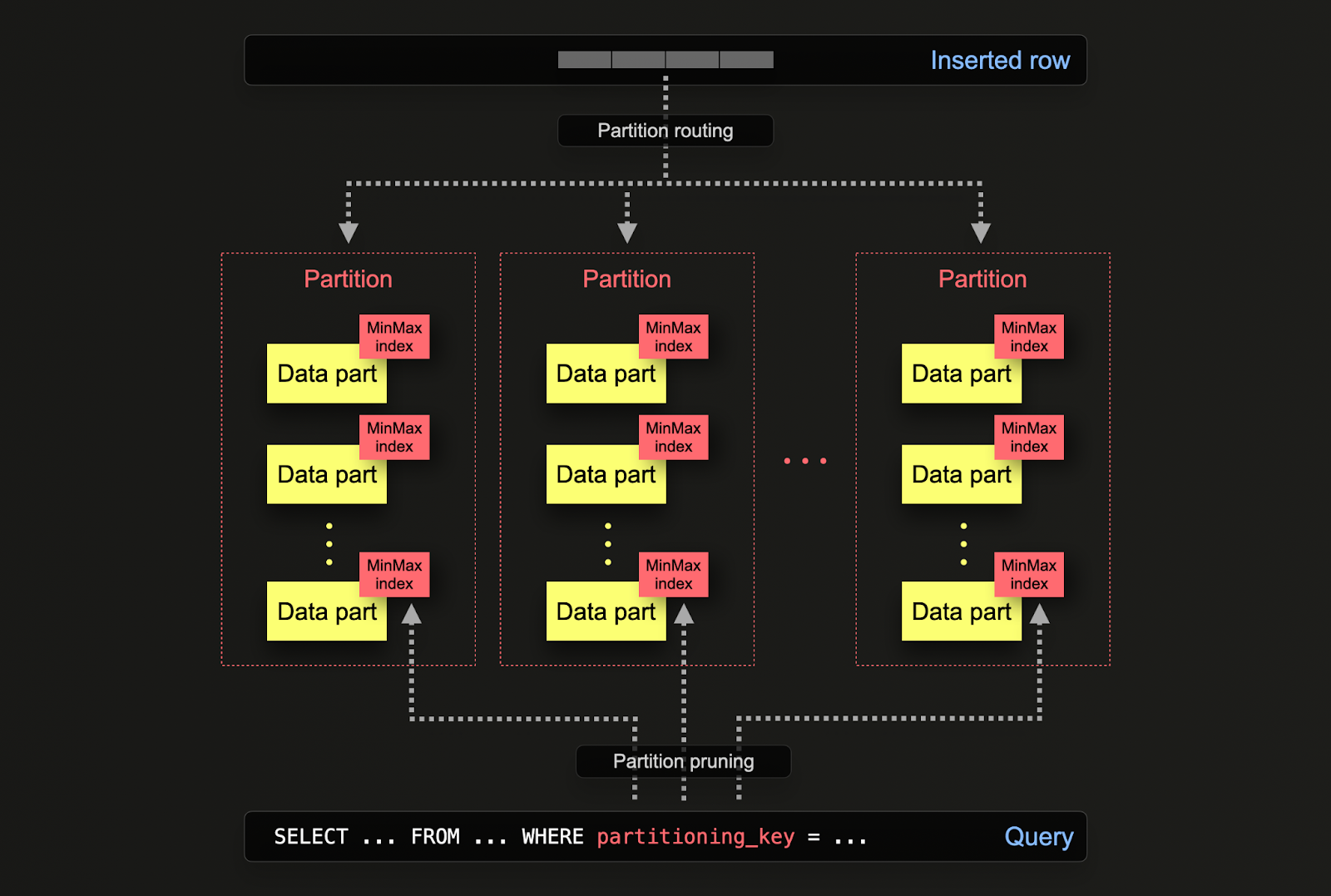
在 ClickHouse 中,分区是在创建表时通过 PARTITION BY 子句指定的。该子句可以包含基于任意列的 SQL 表达式,其结果将决定每一行被写入到哪个分区。
数据片段在磁盘上与各个分区逻辑关联,并且可以被单独查询。对于下面的示例,我们使用表达式 toYear(CreationDate) 按年份对 posts 表进行分区。当行被插入到 ClickHouse 时,该表达式会对每一行进行计算——然后这些行会被路由到对应的分区,并以属于该分区的新数据片段形式存储。
CREATE TABLE posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
...
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate)
PARTITION BY toYear(CreationDate)
应用场景
ClickHouse 中的分区与 BigQuery 中的分区有类似的用途,但也存在一些细微差别。更具体来说:
- 数据管理 - 在 ClickHouse 中,应主要将分区视为一种数据管理功能,而不是查询优化手段。通过基于某个键在逻辑上划分数据,可以对每个分区进行独立操作,例如删除。这样,你就可以根据时间在存储层级之间高效地移动分区(从而移动数据子集),或让数据过期/高效地从集群中删除数据。例如,下面我们将删除 2008 年的帖子:
SELECT DISTINCT partition
FROM system.parts
WHERE `table` = 'posts'
┌─partition─┐
│ 2008 │
│ 2009 │
│ 2010 │
│ 2011 │
│ 2012 │
│ 2013 │
│ 2014 │
│ 2015 │
│ 2016 │
│ 2017 │
│ 2018 │
│ 2019 │
│ 2020 │
│ 2021 │
│ 2022 │
│ 2023 │
│ 2024 │
└───────────┘
17 rows in set. Elapsed: 0.002 sec.
ALTER TABLE posts
(DROP PARTITION '2008')
Ok.
0 rows in set. Elapsed: 0.103 sec.
- 查询优化 - 虽然分区可以帮助提高查询性能,但这在很大程度上取决于访问模式。如果查询只会命中少量分区(理想情况下是一个),则性能可能会得到提升。这通常只在分区键不在主键中且你按该键进行过滤时才有用。然而,需要扫描许多分区的查询,其性能可能会比不使用分区时更差(因为分区可能会导致存在更多的分区片段)。如果分区键已经是主键中靠前的字段,那么针对单个分区的好处会明显减弱,甚至几乎不存在。如果每个分区中的值是唯一的,分区也可以用于优化
GROUP BY 查询。但是,总体来说,你应首先确保主键已得到优化,仅在少数特殊场景下才将分区视作查询优化手段,例如访问模式稳定且只访问一天内某个可预测的时间子区间时(例如按天分区,而大多数查询只访问最近一天的数据)。
用户应将分区视为一种数据管理技术。在处理时序数据并需要让数据从集群中过期时,它是理想的选择,例如可以直接删除最老的分区。
重要:确保你的分区键表达式不会产生高基数集合,即应避免创建超过 100 个分区。例如,不要按客户端标识符或名称等高基数列对数据进行分区。相反,应将客户端标识符或名称设为 ORDER BY 表达式中的第一列。
在内部,ClickHouse 会为插入的数据创建 part。随着更多数据被插入,part 的数量会增加。为了避免 part 数量过多(这会降低查询性能,因为需要读取的文件更多),这些 part 会在后台异步合并。如果 part 的数量超过了预先配置的上限,ClickHouse 会在插入时抛出一个"too many parts" 错误。在正常运行下这不应发生,只会在 ClickHouse 配置错误或使用不当(例如大量小批量插入)时出现。由于 part 是在每个分区内独立创建的,增加分区数量会导致 part 数量增加,即 part 数量是分区数量的倍数。因此,高基数分区键可能会导致该错误,应当避免。
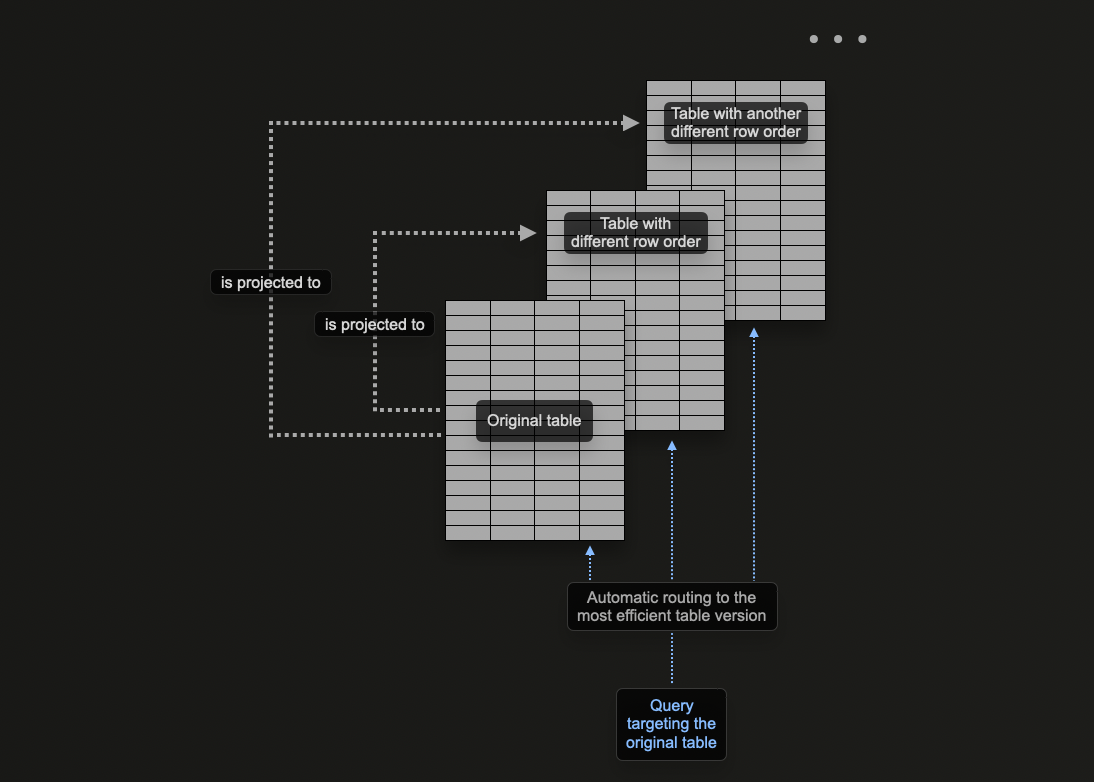
物化视图与投影
ClickHouse 的投影(projection)概念允许用户为同一张表指定多个 ORDER BY 子句。
在 ClickHouse 数据建模 中,我们探讨了如何在 ClickHouse 中使用物化视图
预先计算聚合、转换行,以及针对不同访问模式优化查询。对于后者,我们给出了一个示例,其中
物化视图会将行写入一个目标表,该表的排序键与接收插入的原始表不同。
例如,考虑以下查询:
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
--highlight-next-line
1 row in set. Elapsed: 0.040 sec. Processed 90.38 million rows, 361.59 MB (2.25 billion rows/s., 9.01 GB/s.)
Peak memory usage: 201.93 MiB.
此查询需要扫描全部 9000 万行数据(尽管速度很快),因为 UserId 并不是排序键。之前,我们通过使用一个充当 PostId 查找索引的物化视图来解决这个问题。使用投影(projection)也可以解决同样的问题。下面的命令添加了一个使用 ORDER BY user_id 的投影。
ALTER TABLE comments ADD PROJECTION comments_user_id (
SELECT * ORDER BY UserId
)
ALTER TABLE comments MATERIALIZE PROJECTION comments_user_id
请注意,我们必须先创建该 projection,然后再对其进行物化。
第二个命令会使数据在磁盘上以两种不同的顺序各存储一份。
projection 也可以在创建表时定义,如下所示,并且会在插入数据时自动维护。
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String),
--highlight-begin
PROJECTION comments_user_id
(
SELECT *
ORDER BY UserId
)
--highlight-end
)
ENGINE = MergeTree
ORDER BY PostId
如果通过 ALTER 命令创建投影,那么在执行 MATERIALIZE PROJECTION 命令时,该投影的创建是异步进行的。
用户可以通过以下查询来确认该操作的进度,并等待 is_done=1。
SELECT
parts_to_do,
is_done,
latest_fail_reason
FROM system.mutations
WHERE (`table` = 'comments') AND (command LIKE '%MATERIALIZE%')
┌─parts_to_do─┬─is_done─┬─latest_fail_reason─┐
1. │ 1 │ 0 │ │
└─────────────┴─────────┴────────────────────┘
1 row in set. Elapsed: 0.003 sec.
如果我们重复执行上述查询,可以看到性能有了显著提升,但代价是需要占用更多的存储空间。
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
--highlight-next-line
1 row in set. Elapsed: 0.008 sec. Processed 16.36 thousand rows, 98.17 KB (2.15 million rows/s., 12.92 MB/s.)
Peak memory usage: 4.06 MiB.
借助 EXPLAIN 命令,我们还能确认该查询确实使用了这个 projection:
EXPLAIN indexes = 1
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌─explain─────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY)) │
2. │ Aggregating │
3. │ Filter │
4. │ ReadFromMergeTree (comments_user_id) │
5. │ Indexes: │
6. │ PrimaryKey │
7. │ Keys: │
8. │ UserId │
9. │ Condition: (UserId in [8592047, 8592047]) │
10. │ Parts: 2/2 │
11. │ Granules: 2/11360 │
└─────────────────────────────────────────────────────┘
11 rows in set. Elapsed: 0.004 sec.
何时使用投影
投影对新用户来说是一个极具吸引力的特性,因为它们会在数据插入时自动维护。此外,查询只需发送到单个表,投影会在可能的情况下被自动利用以加快响应时间。
这与物化视图形成对比。在物化视图中,用户必须根据过滤条件选择相应的优化目标表或重写查询。这对用户应用程序提出了更高的要求,并增加了客户端的复杂性。
尽管有这些优势,投影也存在一些固有的局限性,用户应当了解这些局限性,因此应谨慎部署。有关更多详细信息,请参阅"物化视图与投影对比"
我们建议在以下情况下使用投影:
- 需要对数据进行完全重新排序。虽然投影中的表达式理论上可以使用
GROUP BY,但物化视图在维护聚合方面更为有效。查询优化器也更有可能利用使用简单重新排序的投影,即 SELECT * ORDER BY x。用户可以在此表达式中选择列的子集以减少存储占用空间。
- 用户能够接受相关的存储占用空间增加以及两次写入数据的开销。测试对插入速度的影响并评估存储开销。
在 ClickHouse 中重写 BigQuery 查询
下文给出了 BigQuery 与 ClickHouse 的对比查询示例。该列表旨在演示如何利用 ClickHouse 的特性来大幅简化查询。这里的示例使用完整的 Stack Overflow 数据集(截至 2024 年 4 月)。
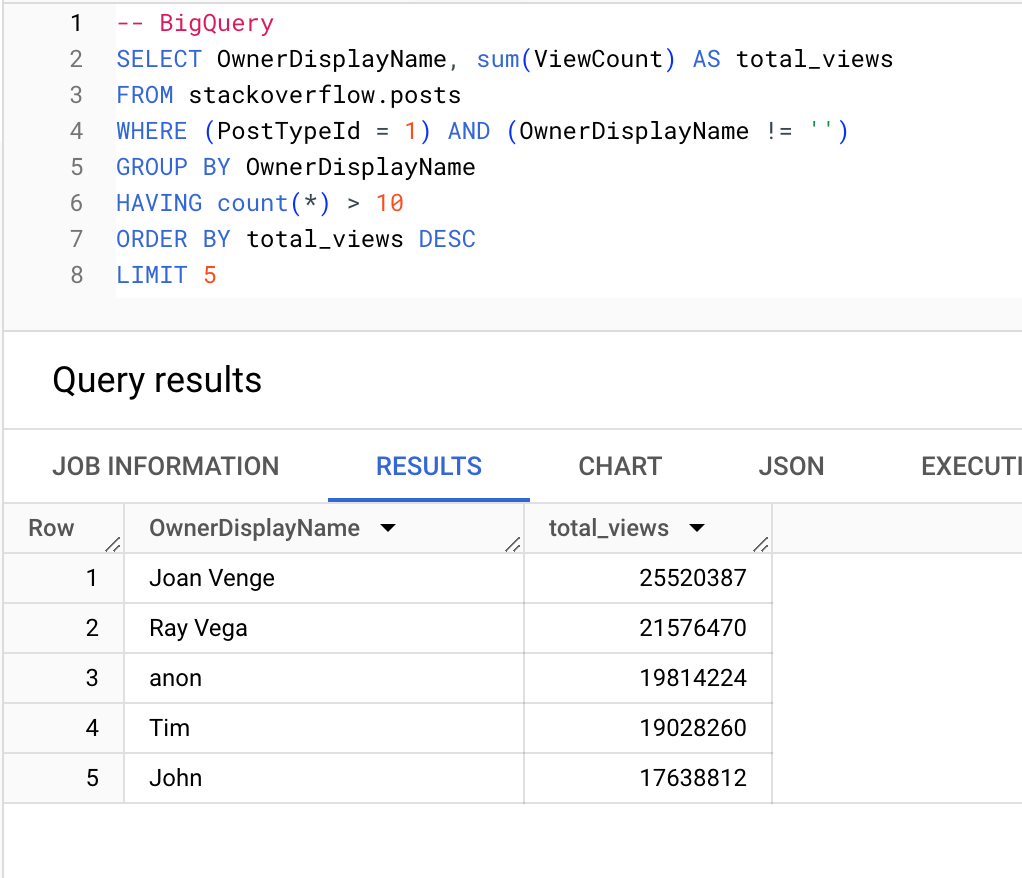
收到最多浏览量的用户(提问数超过 10 个):
BigQuery
ClickHouse
SELECT
OwnerDisplayName,
sum(ViewCount) AS total_views
FROM stackoverflow.posts
WHERE (PostTypeId = 'Question') AND (OwnerDisplayName != '')
GROUP BY OwnerDisplayName
HAVING count() > 10
ORDER BY total_views DESC
LIMIT 5
┌─OwnerDisplayName─┬─total_views─┐
1. │ Joan Venge │ 25520387 │
2. │ Ray Vega │ 21576470 │
3. │ anon │ 19814224 │
4. │ Tim │ 19028260 │
5. │ John │ 17638812 │
└──────────────────┴─────────────┘
5 rows in set. Elapsed: 0.076 sec. Processed 24.35 million rows, 140.21 MB (320.82 million rows/s., 1.85 GB/s.)
Peak memory usage: 323.37 MiB.
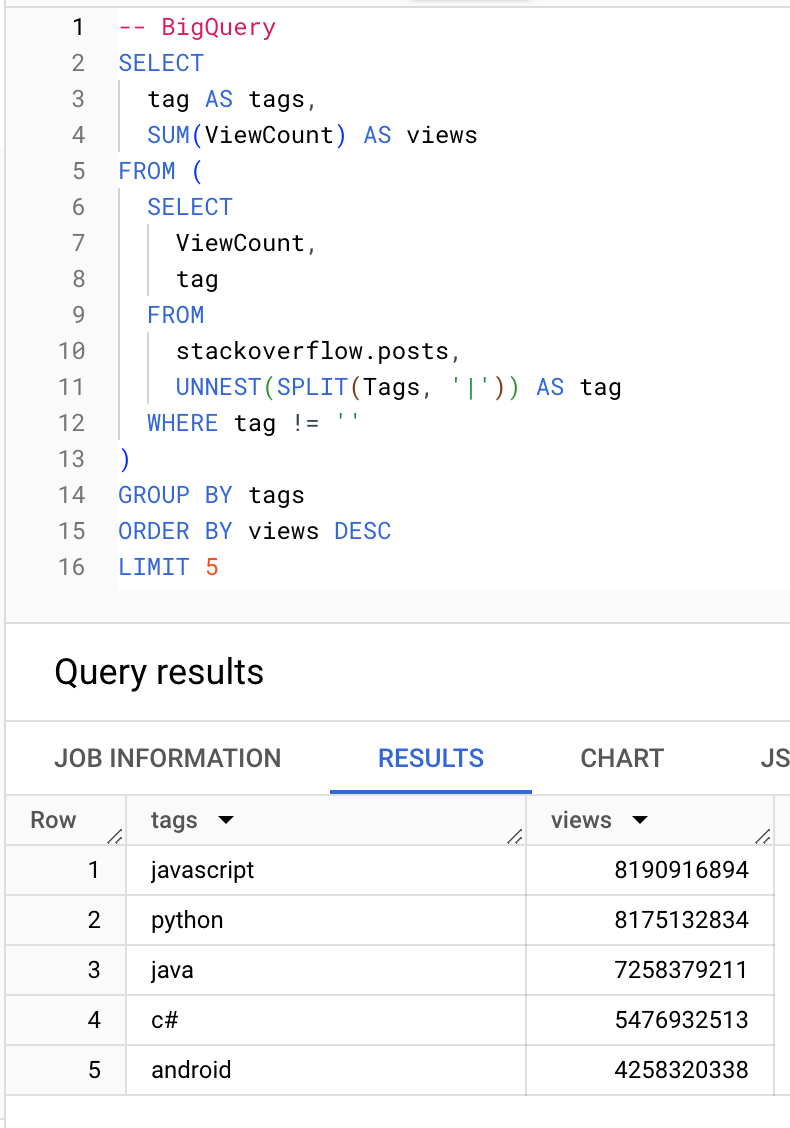
哪些标签的浏览量最高:
BigQuery
ClickHouse
-- ClickHouse
SELECT
arrayJoin(arrayFilter(t -> (t != ''), splitByChar('|', Tags))) AS tags,
sum(ViewCount) AS views
FROM stackoverflow.posts
GROUP BY tags
ORDER BY views DESC
LIMIT 5
┌─tags───────┬──────views─┐
1. │ javascript │ 8190916894 │
2. │ python │ 8175132834 │
3. │ java │ 7258379211 │
4. │ c# │ 5476932513 │
5. │ android │ 4258320338 │
└────────────┴────────────┘
5 rows in set. Elapsed: 0.318 sec. Processed 59.82 million rows, 1.45 GB (188.01 million rows/s., 4.54 GB/s.)
Peak memory usage: 567.41 MiB.
聚合函数
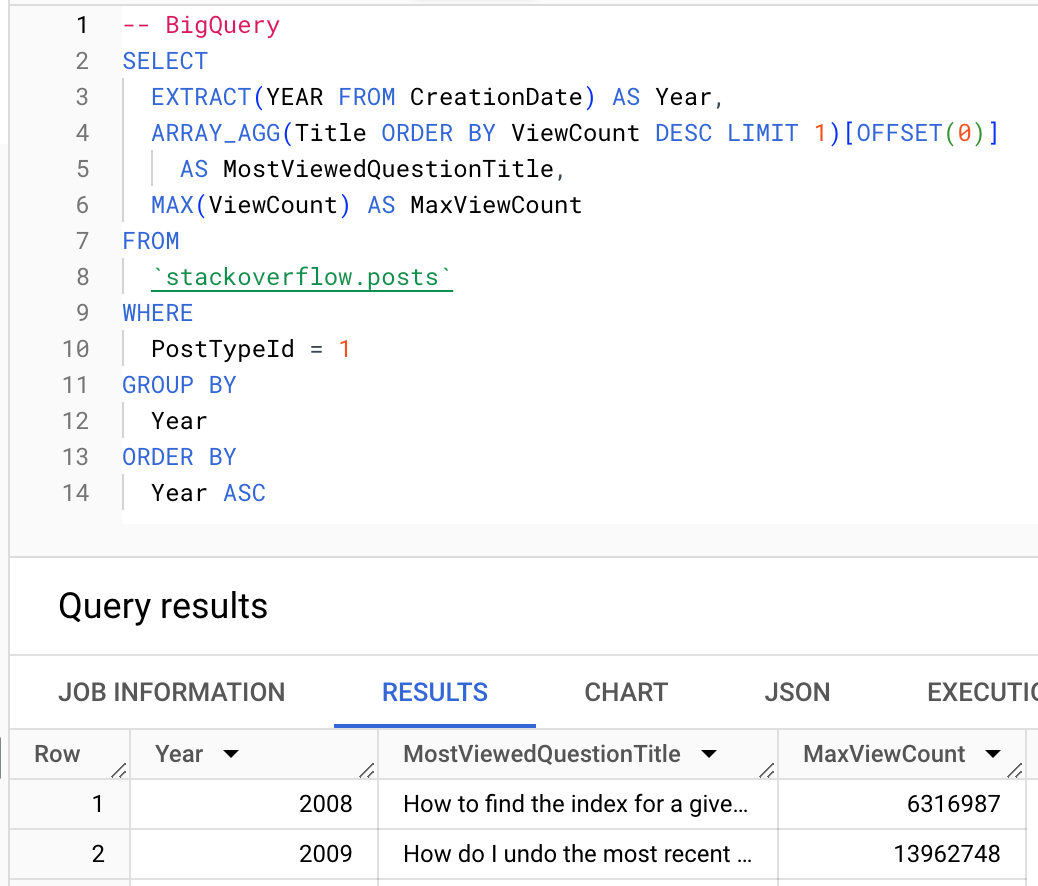
在条件允许的情况下,应尽可能利用 ClickHouse 的聚合函数。下面我们展示如何使用 argMax 函数 来计算每一年浏览次数最多的问题。
BigQuery
ClickHouse
-- ClickHouse
SELECT
toYear(CreationDate) AS Year,
argMax(Title, ViewCount) AS MostViewedQuestionTitle,
max(ViewCount) AS MaxViewCount
FROM stackoverflow.posts
WHERE PostTypeId = 'Question'
GROUP BY Year
ORDER BY Year ASC
FORMAT Vertical
Row 1:
──────
Year: 2008
MostViewedQuestionTitle: How to find the index for a given item in a list?
MaxViewCount: 6316987
Row 2:
──────
Year: 2009
MostViewedQuestionTitle: How do I undo the most recent local commits in Git?
MaxViewCount: 13962748
...
Row 16:
───────
Year: 2023
MostViewedQuestionTitle: How do I solve "error: externally-managed-environment" every time I use pip 3?
MaxViewCount: 506822
Row 17:
───────
Year: 2024
MostViewedQuestionTitle: Warning "Third-party cookie will be blocked. Learn more in the Issues tab"
MaxViewCount: 66975
17 rows in set. Elapsed: 0.225 sec. Processed 24.35 million rows, 1.86 GB (107.99 million rows/s., 8.26 GB/s.)
Peak memory usage: 377.26 MiB.
条件和数组
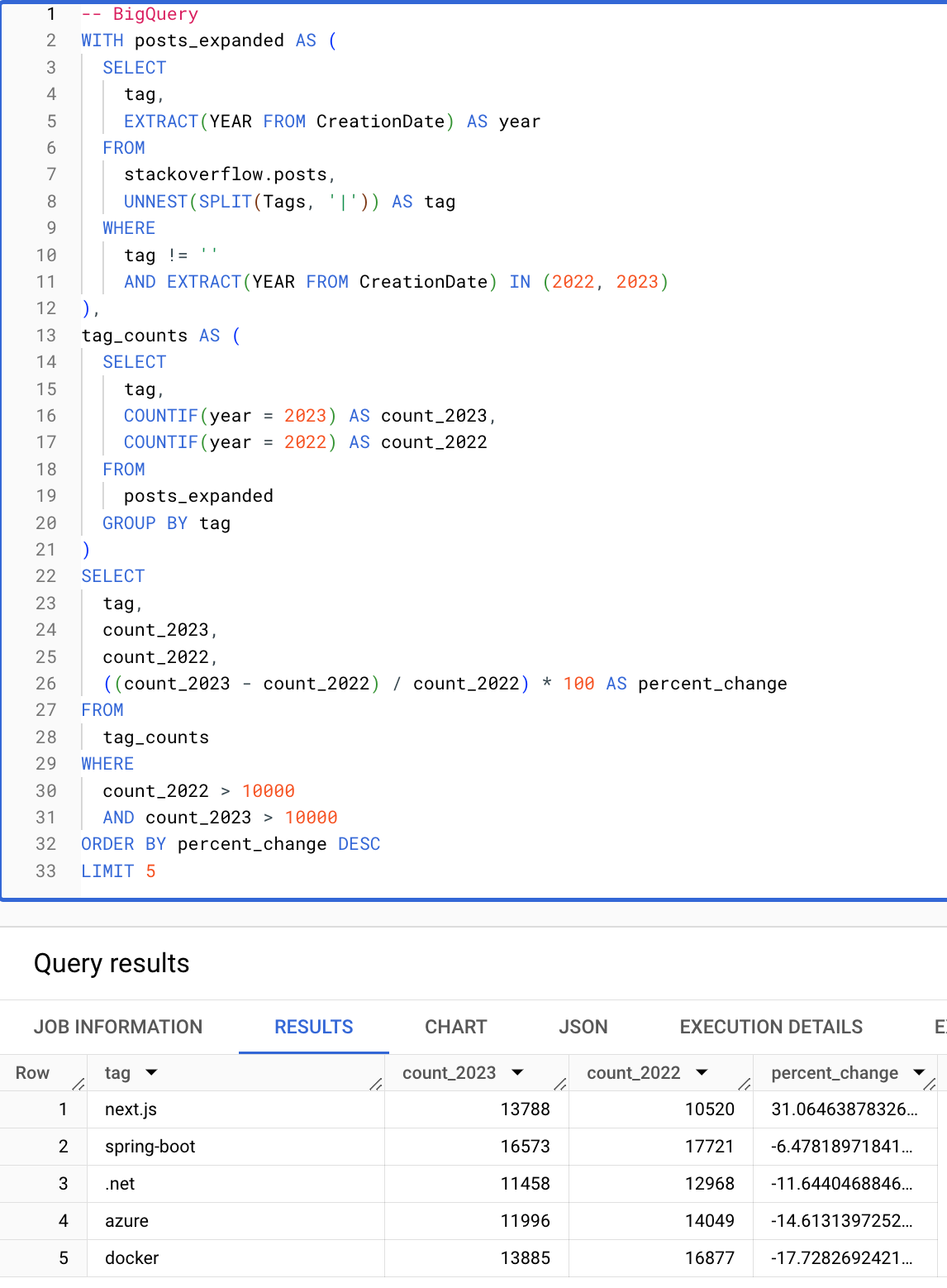
条件和数组函数可以显著简化查询。下面的查询会计算在 2022 年到 2023 年间,出现次数超过 10000 次的标签中,百分比增幅最大的那些标签。请注意,得益于条件函数、数组函数以及在 HAVING 和 SELECT 子句中重复使用别名的能力,下面的 ClickHouse 查询非常简洁。
BigQuery
ClickHouse
SELECT
arrayJoin(arrayFilter(t -> (t != ''), splitByChar('|', Tags))) AS tag,
countIf(toYear(CreationDate) = 2023) AS count_2023,
countIf(toYear(CreationDate) = 2022) AS count_2022,
((count_2023 - count_2022) / count_2022) * 100 AS percent_change
FROM stackoverflow.posts
WHERE toYear(CreationDate) IN (2022, 2023)
GROUP BY tag
HAVING (count_2022 > 10000) AND (count_2023 > 10000)
ORDER BY percent_change DESC
LIMIT 5
┌─tag─────────┬─count_2023─┬─count_2022─┬──────percent_change─┐
│ next.js │ 13788 │ 10520 │ 31.06463878326996 │
│ spring-boot │ 16573 │ 17721 │ -6.478189718413183 │
│ .net │ 11458 │ 12968 │ -11.644046884639112 │
│ azure │ 11996 │ 14049 │ -14.613139725247349 │
│ docker │ 13885 │ 16877 │ -17.72826924216389 │
└─────────────┴────────────┴────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.096 sec. Processed 5.08 million rows, 155.73 MB (53.10 million rows/s., 1.63 GB/s.)
Peak memory usage: 410.37 MiB.
至此,如果你正在从 BigQuery 迁移到 ClickHouse,本基础指南就到这里。我们建议你阅读 在 ClickHouse 中建模数据 文档,以进一步了解 ClickHouse 的高级功能。