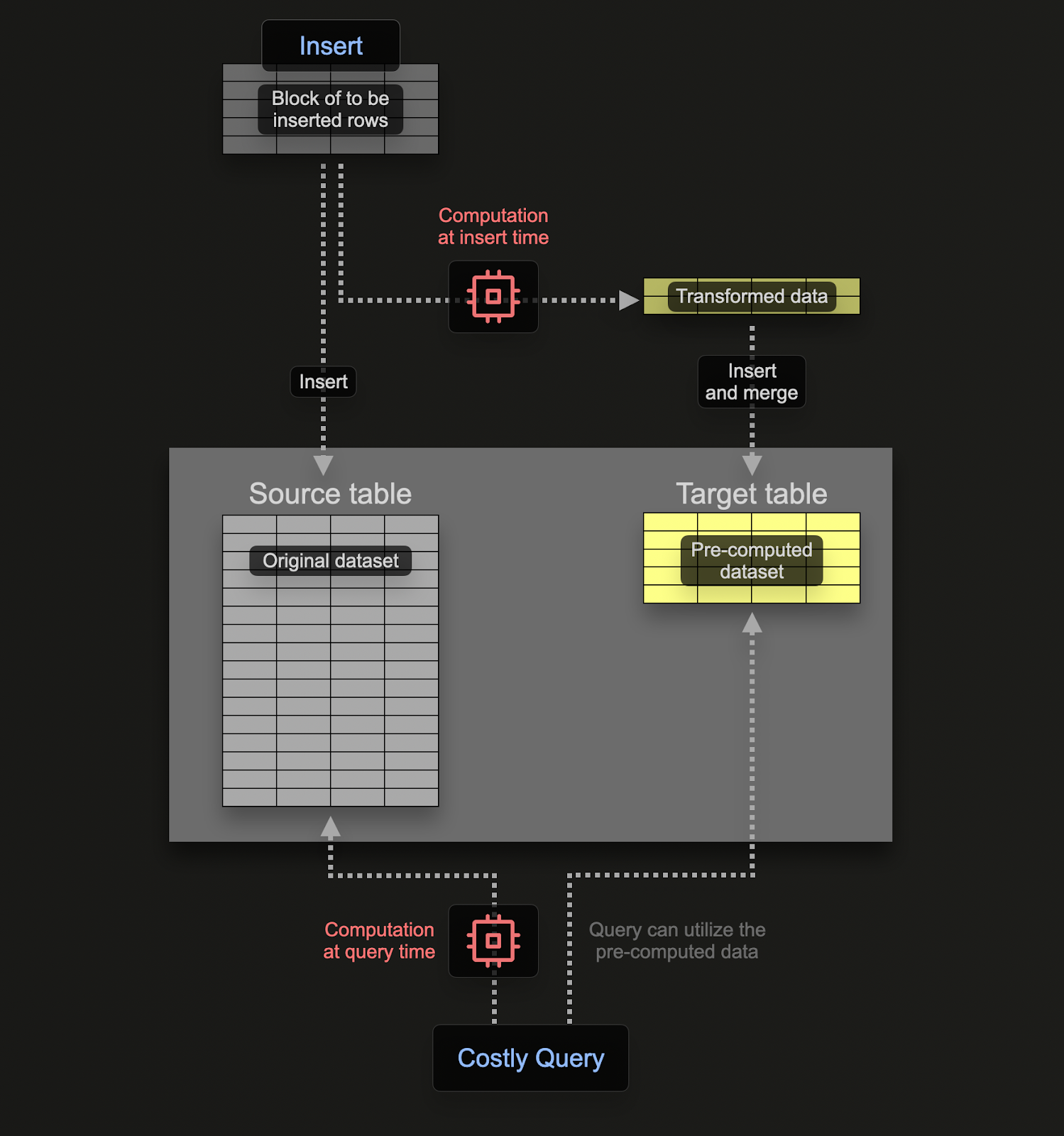
增量materialized view(下文简称 materialized view)允许将计算成本从查询时转移到写入(插入)时,从而加快 SELECT 查询。
与 Postgres 等事务型数据库不同,ClickHouse 中的 materialized view 实质上就是一个触发器,它会在数据块插入到表中时对这些数据块运行一次查询。该查询的结果会被插入到第二个“目标”表中。如果后续再插入更多行,查询结果会再次写入目标表,在那里中间结果会被更新并合并。这个合并后的结果等价于在所有原始数据上运行同一个查询。
使用 materialized view 的主要动机在于,插入到目标表的结果是对行进行聚合、过滤或转换之后的结果。这些结果通常是原始数据的精简表示(在聚合场景下是部分概要 sketch)。再加上从目标表中读取结果所需的查询相对简单,这些因素共同确保查询时间比在原始数据上直接执行相同计算更短,从而将计算(以及由此产生的查询延迟)从查询时转移到写入时。
ClickHouse 中的 materialized view 会在其所依赖的表接收数据时实时更新,其行为更类似于持续更新的索引。这与其他数据库形成对比,在那些数据库中,materialized view 通常是查询的静态快照,需要显式刷新(类似 ClickHouse 的 Refreshable Materialized Views)。
作为示例,我们将使用在《Schema Design》中介绍的 Stack Overflow 数据集。
假设我们希望获取某个帖子每天收到的赞成票和反对票数量。
CREATE TABLE votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId)
INSERT INTO votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 29.359 sec. Processed 238.98 million rows, 2.13 GB (8.14 million rows/s., 72.45 MB/s.)
得益于 toStartOfDay 函数,在 ClickHouse 中这个查询相对来说很简单:
SELECT toStartOfDay(CreationDate) AS day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY day
ORDER BY day ASC
LIMIT 10
┌─────────────────day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 00:00:00 │ 6 │ 0 │
│ 2008-08-01 00:00:00 │ 182 │ 50 │
│ 2008-08-02 00:00:00 │ 436 │ 107 │
│ 2008-08-03 00:00:00 │ 564 │ 100 │
│ 2008-08-04 00:00:00 │ 1306 │ 259 │
│ 2008-08-05 00:00:00 │ 1368 │ 269 │
│ 2008-08-06 00:00:00 │ 1701 │ 211 │
│ 2008-08-07 00:00:00 │ 1544 │ 211 │
│ 2008-08-08 00:00:00 │ 1241 │ 212 │
│ 2008-08-09 00:00:00 │ 576 │ 46 │
└─────────────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.133 sec. Processed 238.98 million rows, 2.15 GB (1.79 billion rows/s., 16.14 GB/s.)
Peak memory usage: 363.22 MiB.
多亏了 ClickHouse,这个查询已经很快了,但我们还能进一步优化吗?
如果我们想在写入时使用 materialized view 来完成这类计算,就需要一张表来接收计算结果。该表应保证每天只保留 1 行。如果某一天的数据收到更新,其他列应与该天已存在的行进行合并。为了实现这种增量状态的合并,其他列必须存储部分聚合状态。
这在 ClickHouse 中需要一种特殊的引擎类型:SummingMergeTree。它会将所有具有相同排序键的行合并为一行,其中包含数值列的求和值。下面的这张表会合并所有具有相同日期的行,并对所有数值列的值进行求和:
CREATE TABLE up_down_votes_per_day
(
`Day` Date,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = SummingMergeTree
ORDER BY Day
为了演示这个 materialized view,假设当前 votes 表是空的,还没有任何数据。我们的 materialized view 会对插入到 votes 中的数据执行上述 SELECT,并将结果写入 up_down_votes_per_day 表:
CREATE MATERIALIZED VIEW up_down_votes_per_day_mv TO up_down_votes_per_day AS
SELECT toStartOfDay(CreationDate)::Date AS Day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY Day
这里的 TO 子句是关键,它表示结果将被发送到哪里,也就是 up_down_votes_per_day。
我们可以根据之前的插入操作重新填充 votes 表:
INSERT INTO votes SELECT toUInt32(Id) AS Id, toInt32(PostId) AS PostId, VoteTypeId, CreationDate, UserId, BountyAmount
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 111.964 sec. Processed 477.97 million rows, 3.89 GB (4.27 million rows/s., 34.71 MB/s.)
Peak memory usage: 283.49 MiB.
完成后,我们可以确认 up_down_votes_per_day 的大小——应该是每天一行:
SELECT count()
FROM up_down_votes_per_day
FINAL
┌─count()─┐
│ 5723 │
└─────────┘
我们已经通过存储查询结果,将这里的行数从 2.38 亿(在 votes 中)有效地减少到 5000 行。关键在于,如果有新的投票被插入到 votes 表中,新值会被写入对应日期的 up_down_votes_per_day,并在后台异步自动合并——从而每天仅保留一行。up_down_votes_per_day 因此会始终保持体量小且数据最新。
由于行的合并是异步进行的,当用户发起查询时,每天可能会存在多行投票记录。为了确保在查询时合并所有尚未合并的行,我们有两个选项:
- 在查询中对表名使用
FINAL 修饰符。我们在上面的计数查询中就是这样做的。
- 按最终表中使用的排序键进行聚合,即按
CreationDate 分组并对相关指标求和。通常这种方式更高效且更灵活(该表可以用于其他用途),但前一种方式对某些查询来说可能更简单。下面我们展示这两种方式:
SELECT
Day,
UpVotes,
DownVotes
FROM up_down_votes_per_day
FINAL
ORDER BY Day ASC
LIMIT 10
10 rows in set. Elapsed: 0.004 sec. Processed 8.97 thousand rows, 89.68 KB (2.09 million rows/s., 20.89 MB/s.)
Peak memory usage: 289.75 KiB.
SELECT Day, sum(UpVotes) AS UpVotes, sum(DownVotes) AS DownVotes
FROM up_down_votes_per_day
GROUP BY Day
ORDER BY Day ASC
LIMIT 10
┌────────Day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 │ 6 │ 0 │
│ 2008-08-01 │ 182 │ 50 │
│ 2008-08-02 │ 436 │ 107 │
│ 2008-08-03 │ 564 │ 100 │
│ 2008-08-04 │ 1306 │ 259 │
│ 2008-08-05 │ 1368 │ 269 │
│ 2008-08-06 │ 1701 │ 211 │
│ 2008-08-07 │ 1544 │ 211 │
│ 2008-08-08 │ 1241 │ 212 │
│ 2008-08-09 │ 576 │ 46 │
└────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.010 sec. Processed 8.97 thousand rows, 89.68 KB (907.32 thousand rows/s., 9.07 MB/s.)
Peak memory usage: 567.61 KiB.
这使我们的查询耗时从 0.133 秒缩短到 0.004 秒——提升超过 25 倍!
信息
重要提示:ORDER BY = GROUP BY在大多数情况下,如果使用 SummingMergeTree 或 AggregatingMergeTree 表引擎,Materialized Views 转换中 GROUP BY 子句所使用的列,应与目标表中 ORDER BY 子句所使用的列保持一致。这些引擎依赖 ORDER BY 中的列在后台合并操作期间合并具有相同值的行。如果 GROUP BY 与 ORDER BY 所使用的列不一致,可能会导致查询性能低下、合并效果不佳,甚至出现数据不一致的情况。
一个更复杂的示例
上面的示例使用 Materialized View 来计算并维护每天的两个求和。求和是在维护中间状态时最简单的聚合形式 —— 当新值到来时,我们只需把它们加到已有的值上即可。不过,ClickHouse 的 Materialized View 可以用于任何聚合类型。
假设我们希望为每天的帖子计算一些统计信息:Score 的第 99.9 百分位数,以及 CommentCount 的平均值。用于进行该计算的查询可能类似于:
SELECT
toStartOfDay(CreationDate) AS Day,
quantile(0.999)(Score) AS Score_99th,
avg(CommentCount) AS AvgCommentCount
FROM posts
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
┌─────────────────Day─┬────────Score_99th─┬────AvgCommentCount─┐
│ 2024-03-31 00:00:00 │ 5.23700000000008 │ 1.3429811866859624 │
│ 2024-03-30 00:00:00 │ 5 │ 1.3097158891616976 │
│ 2024-03-29 00:00:00 │ 5.78899999999976 │ 1.2827635327635327 │
│ 2024-03-28 00:00:00 │ 7 │ 1.277746158224246 │
│ 2024-03-27 00:00:00 │ 5.738999999999578 │ 1.2113264918282023 │
│ 2024-03-26 00:00:00 │ 6 │ 1.3097536945812809 │
│ 2024-03-25 00:00:00 │ 6 │ 1.2836721018539201 │
│ 2024-03-24 00:00:00 │ 5.278999999999996 │ 1.2931667891256429 │
│ 2024-03-23 00:00:00 │ 6.253000000000156 │ 1.334061135371179 │
│ 2024-03-22 00:00:00 │ 9.310999999999694 │ 1.2388059701492538 │
└─────────────────────┴───────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.113 sec. Processed 59.82 million rows, 777.65 MB (528.48 million rows/s., 6.87 GB/s.)
Peak memory usage: 658.84 MiB.
与之前一样,我们可以创建一个 materialized view,当有新帖子插入到我们的 posts 表时,该视图会执行上述查询。
为了便于演示,并避免从 S3 加载帖子数据,我们将创建一个与 posts 具有相同 schema 的 posts_null 副本表。不过,该表本身不会存储任何数据,而只会在插入行时被 materialized view 使用。为避免数据被存储,我们可以使用 Null 表引擎类型。
CREATE TABLE posts_null AS posts ENGINE = Null
Null 表引擎是一种强大的优化手段 —— 可以把它类比为 /dev/null。当 posts_null 表在插入时接收到行数据时,我们的 materialized view 会计算并存储汇总统计信息 —— 它本质上只是一个触发器。不过,原始数据并不会被存储。虽然在我们的示例中,我们很可能仍然希望保留原始帖子,但这种方法可以用于计算聚合的同时避免存储原始数据的开销。
因此,materialized view 将变为:
CREATE MATERIALIZED VIEW post_stats_mv TO post_stats_per_day AS
SELECT toStartOfDay(CreationDate) AS Day,
quantileState(0.999)(Score) AS Score_quantiles,
avgState(CommentCount) AS AvgCommentCount
FROM posts_null
GROUP BY Day
注意我们在聚合函数末尾追加后缀 State。这样可以确保返回的是函数的聚合状态,而不是最终结果。该状态会包含额外信息,从而允许该部分状态与其他状态进行合并。例如,在计算平均值时,其中会包含该列的计数和总和。
部分聚合状态对于计算正确结果是必需的。例如,在计算平均值时,简单地对各个子范围的平均值再取平均会得到不正确的结果。
现在我们为这个视图 post_stats_per_day 创建目标表,用于存储这些部分聚合状态:
CREATE TABLE post_stats_per_day
(
`Day` Date,
`Score_quantiles` AggregateFunction(quantile(0.999), Int32),
`AvgCommentCount` AggregateFunction(avg, UInt8)
)
ENGINE = AggregatingMergeTree
ORDER BY Day
虽然之前使用 SummingMergeTree 足以存储计数,但对于其他函数我们需要一种更高级的引擎类型:AggregatingMergeTree。
为了让 ClickHouse 知道将要存储聚合状态,我们将 Score_quantiles 和 AvgCommentCount 定义为 AggregateFunction 类型,并指定生成这些部分状态的聚合函数以及其源列的类型。与 SummingMergeTree 类似,具有相同 ORDER BY 键值的行将会被合并(在上面的示例中是 Day)。
为了通过 materialized view 填充我们的 post_stats_per_day,我们可以直接将 posts 中的所有行插入到 posts_null 中:
INSERT INTO posts_null SELECT * FROM posts
0 rows in set. Elapsed: 13.329 sec. Processed 119.64 million rows, 76.99 GB (8.98 million rows/s., 5.78 GB/s.)
在生产环境中,通常会将该 materialized view 关联到 posts 表。我们在这里使用 posts_null 是为了演示 null 表。
我们最终的查询需要为函数使用 Merge 后缀(因为这些列存储的是部分聚合状态):
SELECT
Day,
quantileMerge(0.999)(Score_quantiles),
avgMerge(AvgCommentCount)
FROM post_stats_per_day
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
注意,这里我们使用 GROUP BY,而不是 FINAL。
其他应用
上述内容主要聚焦于使用 materialized view 以增量方式更新数据的部分聚合结果,从而将计算从查询阶段前移到写入阶段。除了这一常见用例之外,materialized view 还有许多其他应用场景。
在某些情况下,我们可能只希望在插入时写入部分行和列。此时,我们可以让 posts_null 表接收插入请求,通过 SELECT 查询在写入 posts 表之前先对行进行过滤。比如,假设我们希望对 posts 表中的 Tags 列进行转换。该列中存放的是使用竖线分隔的标签名称列表。通过将其转换为数组,我们可以更容易地按单个标签值进行聚合。
我们可以在执行 INSERT INTO SELECT 时进行此转换。materialized view 允许我们在 ClickHouse 的 DDL 中封装这部分逻辑,从而保持 INSERT 语句简单,并将转换应用到任意新插入的行上。
用于该转换的 materialized view 如下所示:
CREATE MATERIALIZED VIEW posts_mv TO posts AS
SELECT * EXCEPT Tags, arrayFilter(t -> (t != ''), splitByChar('|', Tags)) as Tags FROM posts_null
查找表
在选择 ClickHouse 排序键时,应当考虑其访问模式。应优先选择在过滤和聚合子句中经常使用的列。对于用户访问模式更加多样、无法通过单一列集合来概括的场景,这可能会比较受限。比如,考虑下面的 comments 表:
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY PostId
0 rows in set. Elapsed: 46.357 sec. Processed 90.38 million rows, 11.14 GB (1.95 million rows/s., 240.22 MB/s.)
在这里,排序键使该表针对按 PostId 过滤的查询进行了优化。
假设某个用户希望基于特定的 UserId 进行过滤,并计算该用户的平均 Score:
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.778 sec. Processed 90.38 million rows, 361.59 MB (116.16 million rows/s., 464.74 MB/s.)
Peak memory usage: 217.08 MiB.
虽然这个查询很快(对 ClickHouse 来说数据量仍然较小),但从处理的行数——9038 万行——可以看出,它需要进行一次全表扫描。对于更大的数据集,我们可以使用一个 materialized view,在过滤列 UserId 时先查找排序键 PostId 的取值。然后可以使用这些值来执行高效的查找。
在这个示例中,我们的 materialized view 可以非常简单,只需在插入时从 comments 中选择 PostId 和 UserId。这些结果随后被写入一个按 UserId 排序的表 comments_posts_users。我们在下方创建 Comments 表的一个空表版本,并使用它来填充我们的 materialized view 和 comments_posts_users 表:
CREATE TABLE comments_posts_users (
PostId UInt32,
UserId Int32
) ENGINE = MergeTree ORDER BY UserId
CREATE TABLE comments_null AS comments
ENGINE = Null
CREATE MATERIALIZED VIEW comments_posts_users_mv TO comments_posts_users AS
SELECT PostId, UserId FROM comments_null
INSERT INTO comments_null SELECT * FROM comments
0 rows in set. Elapsed: 5.163 sec. Processed 90.38 million rows, 17.25 GB (17.51 million rows/s., 3.34 GB/s.)
现在我们可以在子查询中使用该 VIEW 来加速之前的查询:
SELECT avg(Score)
FROM comments
WHERE PostId IN (
SELECT PostId
FROM comments_posts_users
WHERE UserId = 8592047
) AND UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 88.61 thousand rows, 771.37 KB (7.09 million rows/s., 61.73 MB/s.)
链式 / 级联 Materialized Views
Materialized views 可以按链式(或级联)方式组合,从而构建复杂的工作流。
更多信息请参阅指南《Cascading materialized views》(https://clickhouse.com/docs/guides/developer/cascading-materialized-views)。
materialized view 与 JOIN
可刷新materialized view
以下内容仅适用于增量materialized view。可刷新materialized view 会定期在完整目标数据集上执行其查询,并完全支持 JOIN。对于复杂的 JOIN,如果可以接受结果时效性有所降低,请考虑使用它们。
ClickHouse 中的增量materialized view 完全支持 JOIN 操作,但有一个关键约束:materialized view 只会在对源表(查询中最左侧的表)执行插入时被触发。 JOIN 中右侧的表即使数据发生变化,也不会触发更新。在构建 增量 materialized view 时,这一点尤为重要,因为数据是在插入时被聚合或转换的。
当使用 JOIN 定义一个增量materialized view 时,SELECT 查询中最左侧的表充当源表。当向该表插入新行时,ClickHouse 只会使用这些新插入的行来执行 materialized view 查询。JOIN 中右侧的表在这次执行中会被完整读取,但仅对它们进行更改并不会触发该 view。
这种行为使得 materialized view 中的 JOIN 类似于针对静态维度数据的快照式 JOIN。
这非常适合使用参考表或维度表来丰富数据。然而,对右侧表(例如用户元数据)的任何更新都不会对已有的 materialized view 结果进行追溯更新。要查看更新后的数据,必须向源表插入新的数据。
下面通过一个使用 Stack Overflow 数据集 的具体示例来说明。我们将使用一个 materialized view 来计算每个用户每天获得的徽章数,并从 users 表中包含用户的显示名称。
回顾一下,我们的表结构如下:
CREATE TABLE badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
CREATE TABLE users
(
`Id` Int32,
`Reputation` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`DisplayName` LowCardinality(String),
`LastAccessDate` DateTime64(3, 'UTC'),
`Location` LowCardinality(String),
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = MergeTree
ORDER BY Id;
我们假设 users 表中已经预先有数据:
INSERT INTO users
SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet');
materialized view 及其关联的目标表的定义如下:
CREATE TABLE daily_badges_by_user
(
Day Date,
UserId Int32,
DisplayName LowCardinality(String),
Gold UInt32,
Silver UInt32,
Bronze UInt32
)
ENGINE = SummingMergeTree
ORDER BY (DisplayName, UserId, Day);
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user AS
SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN users AS u ON b.UserId = u.Id
GROUP BY Day, b.UserId, u.DisplayName;
分组与排序对齐
materialized view 中的 GROUP BY 子句必须包含 DisplayName、UserId 和 Day,以与目标 SummingMergeTree 表中的 ORDER BY 保持一致。这样可以确保行被正确聚合和合并。省略其中任意一项都可能导致结果不正确或合并效率低下。
如果我们现在填充徽章数据,该 view 将被触发,从而向我们的 daily_badges_by_user 表写入数据。
INSERT INTO badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 433.762 sec. Processed 1.16 billion rows, 28.50 GB (2.67 million rows/s., 65.70 MB/s.)
如果我们想查看某个用户获得的徽章,可以编写如下查询:
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'gingerwizard'
┌────────Day─┬──UserId─┬─DisplayName──┬─Gold─┬─Silver─┬─Bronze─┐
│ 2023-02-27 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-28 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-10-30 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2024-03-04 │ 2936484 │ gingerwizard │ 0 │ 1 │ 0 │
│ 2024-03-05 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-04-17 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-11-18 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-10-31 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
└────────────┴─────────┴──────────────┴──────┴────────┴────────┘
8 rows in set. Elapsed: 0.018 sec. Processed 32.77 thousand rows, 642.14 KB (1.86 million rows/s., 36.44 MB/s.)
现在,如果该用户获得了一个新徽章并插入了一行数据,我们的视图会更新:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 7.517 sec.
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'gingerwizard'
┌────────Day─┬──UserId─┬─DisplayName──┬─Gold─┬─Silver─┬─Bronze─┐
│ 2013-10-30 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-11-18 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-27 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-28 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-04-17 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-10-31 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2024-03-04 │ 2936484 │ gingerwizard │ 0 │ 1 │ 0 │
│ 2024-03-05 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2025-04-13 │ 2936484 │ gingerwizard │ 1 │ 0 │ 0 │
└────────────┴─────────┴──────────────┴──────┴────────┴────────┘
9 rows in set. Elapsed: 0.017 sec. Processed 32.77 thousand rows, 642.27 KB (1.96 million rows/s., 38.50 MB/s.)
相反,如果我们先为新用户插入一个 badge,然后再插入该用户的行,我们的 materialized view 将无法捕获该用户的指标。
INSERT INTO badges VALUES (53505059, 23923286, 'Good Answer', now(), 'Bronze', 0);
INSERT INTO users VALUES (23923286, 1, now(), 'brand_new_user', now(), 'UK', 1, 1, 0);
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'brand_new_user';
0 rows in set. Elapsed: 0.017 sec. Processed 32.77 thousand rows, 644.32 KB (1.98 million rows/s., 38.94 MB/s.)
在这种情况下,视图只会在插入 badge 且对应的 user 行尚不存在时执行。若我们之后再为该用户插入一个 badge,就会插入一行记录,这正是预期的行为:
INSERT INTO badges VALUES (53505060, 23923286, 'Teacher', now(), 'Bronze', 0);
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'brand_new_user'
┌────────Day─┬───UserId─┬─DisplayName────┬─Gold─┬─Silver─┬─Bronze─┐
│ 2025-04-13 │ 23923286 │ brand_new_user │ 0 │ 0 │ 1 │
└────────────┴──────────┴────────────────┴──────┴────────┴────────┘
1 row in set. Elapsed: 0.018 sec. Processed 32.77 thousand rows, 644.48 KB (1.87 million rows/s., 36.72 MB/s.)
但需要注意的是,该结果并不正确。
materialized view 中 JOIN 的最佳实践
-
将最左侧的表用作触发源。 只有 SELECT 语句左侧的表会触发 materialized view。右侧表的变更不会触发更新。
-
预先插入用于 JOIN 的数据。 确保在向源表插入行之前,被 JOIN 的表中的数据已经存在。JOIN 在插入时计算,因此缺失数据会导致行无法匹配或产生空值。
-
限制从 JOIN 中读取的列。 只从被 JOIN 的表中选择需要的列,以最小化内存使用并降低插入延迟(见下文)。
-
评估插入时的性能影响。 JOIN 会增加插入的开销,尤其是在右侧表很大的情况下。使用具有代表性的生产数据对插入速率进行基准测试。
-
对于简单查找优先使用字典。 对于键值查找(例如用户 ID 到名称),使用 Dictionaries,以避免代价高昂的 JOIN 操作。
-
对齐 GROUP BY 与 ORDER BY 以提高合并效率。 使用 SummingMergeTree 或 AggregatingMergeTree 时,确保 GROUP BY 与目标表中的 ORDER BY 子句一致,以便高效地合并行。
-
使用显式列别名。 当表之间存在重名列时,使用别名以避免歧义,并确保目标表中的结果正确。
-
考虑插入量和插入频率。 在中等插入负载场景中,JOIN 通常效果良好。对于高吞吐摄取场景,考虑使用中间表、预先进行 JOIN,或其他方案,例如 Dictionaries 和 Refreshable Materialized Views。
在过滤和 JOIN 中使用源表
在 ClickHouse 中使用 Materialized View 时,理解在执行该 Materialized View 的查询时源表是如何处理的非常重要。具体来说,Materialized View 查询中的源表会被替换为当前插入的数据块。如果未充分理解这种行为,可能会导致一些出乎意料的结果。
示例场景
假设有如下设置:
CREATE TABLE t0 (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw1_inner (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw2_inner (`c0` Int) ENGINE = Memory;
CREATE VIEW vt0 AS SELECT * FROM t0;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN ( SELECT * FROM t0 ) AS x ON t0.c0 = x.c0;
CREATE MATERIALIZED VIEW mvw2 TO mvw2_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN vt0 ON t0.c0 = vt0.c0;
INSERT INTO t0 VALUES (1),(2),(3);
INSERT INTO t0 VALUES (1),(2),(3),(4),(5);
SELECT * FROM mvw1;
┌─c0─┐
│ 3 │
│ 5 │
└────┘
SELECT * FROM mvw2;
┌─c0─┐
│ 3 │
│ 8 │
└────┘
在上述示例中,我们有两个 materialized view:mvw1 和 mvw2,它们执行的操作类似,但在引用源表 t0 的方式上有细微差别。
在 mvw1 中,表 t0 在 JOIN 右侧被直接写在子查询 (SELECT * FROM t0) 中。当数据插入到 t0 时,会执行该 materialized view 的查询,并在查询中用插入的数据块替换对 t0 的引用。这意味着 JOIN 操作只会在新插入的行上执行,而不是在整张表上执行。
在第二种与 vt0 进行 JOIN 的情况中,该 VIEW 会从 t0 中读取所有数据。这确保了 JOIN 操作会考虑 t0 中的所有行,而不仅仅是新插入的数据块。
关键差异在于 ClickHouse 在 materialized view 的查询中如何处理源表。当 materialized view 由一次插入触发时,源表(在本例中为 t0)会在查询中被插入的数据块所替代。这种行为可以用来优化查询,但同时也需要谨慎对待,以避免产生意外结果。
用例和注意事项
在实际使用中,可以利用这种行为来优化只需处理源表部分数据的 materialized view。比如,你可以使用子查询在将源表与其他表进行 JOIN 之前先对其进行过滤。这样可以减少 materialized view 需要处理的数据量,从而提升性能。
CREATE TABLE t0 (id UInt32, value String) ENGINE = MergeTree() ORDER BY id;
CREATE TABLE t1 (id UInt32, description String) ENGINE = MergeTree() ORDER BY id;
INSERT INTO t1 VALUES (1, 'A'), (2, 'B'), (3, 'C');
CREATE TABLE mvw1_target_table (id UInt32, value String, description String) ENGINE = MergeTree() ORDER BY id;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_target_table AS
SELECT t0.id, t0.value, t1.description
FROM t0
JOIN (SELECT * FROM t1 WHERE t1.id IN (SELECT id FROM t0)) AS t1
ON t0.id = t1.id;
在此示例中,由子查询 IN (SELECT id FROM t0) 构建的集合只包含新插入的行,这有助于用它来过滤 t1。
Stack Overflow 示例
回顾我们之前的 materialized view 示例,用于计算每位用户的每日徽章数,并从 users 表中包含用户的显示名称。
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user
AS SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN users AS u ON b.UserId = u.Id
GROUP BY Day, b.UserId, u.DisplayName;
该视图对 badges 表的插入延迟产生了显著的影响,例如:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 7.517 sec.
使用上述方法,我们可以优化这个视图。我们将根据插入的徽章行中的用户 ID,为 users 表添加一个过滤条件:
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user
AS SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN
(
SELECT
Id,
DisplayName
FROM users
WHERE Id IN (
SELECT UserId
FROM badges
)
) AS u ON b.UserId = u.Id
GROUP BY
Day,
b.UserId,
u.DisplayName
这不仅加快了首次插入 badges 的速度:
INSERT INTO badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 132.118 sec. Processed 323.43 million rows, 4.69 GB (2.45 million rows/s., 35.49 MB/s.)
Peak memory usage: 1.99 GiB.
但这也意味着之后插入 badge 的操作会很高效:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 0.583 sec.
在上述操作中,只从 users 表中检索到用户 ID 为 2936484 的一行数据。该查找也利用将 Id 作为表的排序键进行了优化。
materialized view 和 UNION 查询
UNION ALL 查询通常用于将来自多个源表的数据合并到一个结果集中。
虽然在增量materialized view 中不直接支持 UNION ALL,但你可以通过为每个 SELECT 分支创建单独的 materialized view,并将它们的结果写入同一个目标表,来实现相同的效果。
在本例中,我们将使用 Stack Overflow 数据集。请看下面的 badges 和 comments 表,它们分别表示用户获得的徽章以及他们在帖子下发表的评论:
CREATE TABLE stackoverflow.comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY CreationDate
CREATE TABLE stackoverflow.badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
这些可以通过以下 INSERT INTO 语句进行填充:
INSERT INTO stackoverflow.badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
INSERT INTO stackoverflow.comments SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/comments/*.parquet')
假设我们想要创建一个统一的用户活动视图,通过合并这两张表的数据来展示每个用户最近一次的活动:
SELECT
UserId,
argMax(description, event_time) AS last_description,
argMax(activity_type, event_time) AS activity_type,
max(event_time) AS last_activity
FROM
(
SELECT
UserId,
CreationDate AS event_time,
Text AS description,
'comment' AS activity_type
FROM stackoverflow.comments
UNION ALL
SELECT
UserId,
Date AS event_time,
Name AS description,
'badge' AS activity_type
FROM stackoverflow.badges
)
GROUP BY UserId
ORDER BY last_activity DESC
LIMIT 10
假设我们已经有一个目标表来接收此查询的结果。请注意此处使用了 AggregatingMergeTree 表引擎和 AggregateFunction,以确保结果被正确合并:
CREATE TABLE user_activity
(
`UserId` String,
`last_description` AggregateFunction(argMax, String, DateTime64(3, 'UTC')),
`activity_type` AggregateFunction(argMax, String, DateTime64(3, 'UTC')),
`last_activity` SimpleAggregateFunction(max, DateTime64(3, 'UTC'))
)
ENGINE = AggregatingMergeTree
ORDER BY UserId
如果希望这个表在向 badges 或 comments 插入新行时自动更新,一个简单但并不理想的思路是尝试使用前面的 UNION 查询来创建一个 materialized view:
CREATE MATERIALIZED VIEW user_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(description, event_time) AS last_description,
argMaxState(activity_type, event_time) AS activity_type,
max(event_time) AS last_activity
FROM
(
SELECT
UserId,
CreationDate AS event_time,
Text AS description,
'comment' AS activity_type
FROM stackoverflow.comments
UNION ALL
SELECT
UserId,
Date AS event_time,
Name AS description,
'badge' AS activity_type
FROM stackoverflow.badges
)
GROUP BY UserId
ORDER BY last_activity DESC
虽然这在语法上是正确的,但会产生非预期的结果——该视图只会在向 comments 表插入数据时被触发。例如:
INSERT INTO comments VALUES (99999999, 23121, 1, 'The answer is 42', now(), 2936484, 'gingerwizard');
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 09:56:19.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.005 sec.
向 badges 表插入数据不会触发该 VIEW,从而使 user_activity 表无法获得更新:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId;
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 09:56:19.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.005 sec.
为了解决这个问题,我们只需为每个 SELECT 语句创建一个 materialized view 即可:
DROP TABLE user_activity_mv;
TRUNCATE TABLE user_activity;
CREATE MATERIALIZED VIEW comment_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(Text, CreationDate) AS last_description,
argMaxState('comment', CreationDate) AS activity_type,
max(CreationDate) AS last_activity
FROM stackoverflow.comments
GROUP BY UserId;
CREATE MATERIALIZED VIEW badges_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(Name, Date) AS last_description,
argMaxState('badge', Date) AS activity_type,
max(Date) AS last_activity
FROM stackoverflow.badges
GROUP BY UserId;
现在向任一张表插入数据都会得到正确的结果。例如,如果我们向 comments 表插入数据:
INSERT INTO comments VALUES (99999999, 23121, 1, 'The answer is 42', now(), 2936484, 'gingerwizard');
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId;
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 10:18:47.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.006 sec.
同样,对 badges 表的插入操作也会反映在 user_activity 表中:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId
┌─UserId──┬─description──┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ gingerwizard │ badge │ 2025-04-15 10:20:18.000 │
└─────────┴──────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.006 sec.
并行处理 vs 顺序处理
如前面的示例所示,一张表可以作为多个 Materialized View 的源表。这些视图的执行顺序取决于 parallel_view_processing 这一设置项。
默认情况下,该设置项的值为 0(false),这意味着 Materialized View 会按 uuid 顺序依次执行。
例如,考虑下面的 source 表和 3 个 Materialized View,它们各自将行发送到同一个 target 表中:
CREATE TABLE source
(
`message` String
)
ENGINE = MergeTree
ORDER BY tuple();
CREATE TABLE target
(
`message` String,
`from` String,
`now` DateTime64(9),
`sleep` UInt8
)
ENGINE = MergeTree
ORDER BY tuple();
CREATE MATERIALIZED VIEW mv_2 TO target
AS SELECT
message,
'mv2' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
CREATE MATERIALIZED VIEW mv_3 TO target
AS SELECT
message,
'mv3' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
CREATE MATERIALIZED VIEW mv_1 TO target
AS SELECT
message,
'mv1' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
请注意,每个视图在将其行插入到 target 表之前都会暂停 1 秒,并在插入的数据中包含其名称和插入时间。
向表 source 插入一行大约需要 3 秒,且各个视图会依次顺序执行:
INSERT INTO source VALUES ('test')
1 row in set. Elapsed: 3.786 sec.
我们可以通过执行一条 SELECT 查询来确认每一行是否已经到达:
SELECT
message,
from,
now
FROM target
ORDER BY now ASC
┌─message─┬─from─┬───────────────────────────now─┐
│ test │ mv3 │ 2025-04-15 14:52:01.306162309 │
│ test │ mv1 │ 2025-04-15 14:52:02.307693521 │
│ test │ mv2 │ 2025-04-15 14:52:03.309250283 │
└─────────┴──────┴───────────────────────────────┘
3 rows in set. Elapsed: 0.015 sec.
这与各视图的 uuid 保持一致:
SELECT
name,
uuid
FROM system.tables
WHERE name IN ('mv_1', 'mv_2', 'mv_3')
ORDER BY uuid ASC
┌─name─┬─uuid─────────────────────────────────┐
│ mv_3 │ ba5e36d0-fa9e-4fe8-8f8c-bc4f72324111 │
│ mv_1 │ b961c3ac-5a0e-4117-ab71-baa585824d43 │
│ mv_2 │ e611cc31-70e5-499b-adcc-53fb12b109f5 │
└──────┴──────────────────────────────────────┘
3 rows in set. Elapsed: 0.004 sec.
另一方面,来看一下在启用 parallel_view_processing=1 时插入一行会发生什么。启用该设置后,视图将被并行执行,行写入目标表的顺序无法得到保证:
TRUNCATE target;
SET parallel_view_processing = 1;
INSERT INTO source VALUES ('test');
1 row in set. Elapsed: 1.588 sec.
SELECT
message,
from,
now
FROM target
ORDER BY now ASC
┌─message─┬─from─┬───────────────────────────now─┐
│ test │ mv3 │ 2025-04-15 19:47:32.242937372 │
│ test │ mv1 │ 2025-04-15 19:47:32.243058183 │
│ test │ mv2 │ 2025-04-15 19:47:32.337921800 │
└─────────┴──────┴───────────────────────────────┘
3 rows in set. Elapsed: 0.004 sec.
尽管在本例中各视图的行到达顺序相同,但这并不能得到保证——从各行插入时间的相近程度就可以看出这一点。同时请注意插入性能的提升。
何时使用并行处理
启用 parallel_view_processing=1 可以显著提升插入吞吐量,如前所示,尤其是在单个表上挂载了多个 materialized view 的情况下。不过,需要理解其中的权衡:
- 写入压力增加:所有 materialized view 会同时执行,从而提高 CPU 和内存占用。如果每个 view 都执行较重的计算或 JOIN,可能会导致系统过载。
- 需要严格的执行顺序:在少见的工作流中,如果 view 的执行顺序很重要(例如存在链式依赖),并行执行可能导致状态不一致或竞争条件。虽然可以通过设计进行规避,但此类架构非常脆弱,并可能在未来版本中出现问题。
历史默认行为与稳定性
顺序执行在很长一段时间内是默认行为,部分原因在于错误处理的复杂性。从历史上看,一个 materialized view 的失败可能会阻止其他 view 的执行。较新的版本通过按数据块隔离失败进行了改进,但顺序执行仍然提供更清晰的失败语义。
通常,在以下情况下建议启用 parallel_view_processing=1:
- 存在多个彼此独立的 materialized view
- 需要最大化插入性能
- 已充分评估系统处理并发 view 执行的能力
在以下情况下建议保持关闭:
- materialized view 之间存在依赖关系
- 需要可预测、有序的执行
- 正在调试或审计插入行为,并需要确定性的重放
materialized view 与公用表表达式(CTE)
在 materialized view 中支持 非递归 公用表表达式(CTE)。
注意
公用表表达式不会被物化ClickHouse 不会对 CTE 进行物化;相反,它会将 CTE 的定义直接内联到查询中,如果同一个 CTE 被多次使用,则可能导致同一表达式被重复计算。
请看下面的示例,用于按帖子类型统计每天的活动情况。
CREATE TABLE daily_post_activity
(
Day Date,
PostType String,
PostsCreated SimpleAggregateFunction(sum, UInt64),
AvgScore AggregateFunction(avg, Int32),
TotalViews SimpleAggregateFunction(sum, UInt64)
)
ENGINE = AggregatingMergeTree
ORDER BY (Day, PostType);
CREATE MATERIALIZED VIEW daily_post_activity_mv TO daily_post_activity AS
WITH filtered_posts AS (
SELECT
toDate(CreationDate) AS Day,
PostTypeId,
Score,
ViewCount
FROM posts
WHERE Score > 0 AND PostTypeId IN (1, 2) -- Question or Answer
)
SELECT
Day,
CASE PostTypeId
WHEN 1 THEN 'Question'
WHEN 2 THEN 'Answer'
END AS PostType,
count() AS PostsCreated,
avgState(Score) AS AvgScore,
sum(ViewCount) AS TotalViews
FROM filtered_posts
GROUP BY Day, PostTypeId;
在本例中其实没必要使用 CTE,但为了演示,视图依然会按预期工作:
INSERT INTO posts
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
SELECT
Day,
PostType,
avgMerge(AvgScore) AS AvgScore,
sum(PostsCreated) AS PostsCreated,
sum(TotalViews) AS TotalViews
FROM daily_post_activity
GROUP BY
Day,
PostType
ORDER BY Day DESC
LIMIT 10
┌────────Day─┬─PostType─┬───────────AvgScore─┬─PostsCreated─┬─TotalViews─┐
│ 2024-03-31 │ Question │ 1.3317757009345794 │ 214 │ 9728 │
│ 2024-03-31 │ Answer │ 1.4747191011235956 │ 356 │ 0 │
│ 2024-03-30 │ Answer │ 1.4587912087912087 │ 364 │ 0 │
│ 2024-03-30 │ Question │ 1.2748815165876777 │ 211 │ 9606 │
│ 2024-03-29 │ Question │ 1.2641509433962264 │ 318 │ 14552 │
│ 2024-03-29 │ Answer │ 1.4706927175843694 │ 563 │ 0 │
│ 2024-03-28 │ Answer │ 1.601637107776262 │ 733 │ 0 │
│ 2024-03-28 │ Question │ 1.3530864197530865 │ 405 │ 24564 │
│ 2024-03-27 │ Question │ 1.3225806451612903 │ 434 │ 21346 │
│ 2024-03-27 │ Answer │ 1.4907539118065434 │ 703 │ 0 │
└────────────┴──────────┴────────────────────┴──────────────┴────────────┘
10 rows in set. Elapsed: 0.013 sec. Processed 11.45 thousand rows, 663.87 KB (866.53 thousand rows/s., 50.26 MB/s.)
Peak memory usage: 989.53 KiB.
在 ClickHouse 中,CTE 会被内联,这意味着它们在优化阶段会被实际“复制粘贴”到查询中,并且不会被物化。这意味着:
- 如果你的 CTE 引用的表不同于源表(即 materialized view 所附加的那张表),并且被用于
JOIN 或 IN 子句中,那么它的行为会像一个子查询或 JOIN,而不是触发器。
- materialized view 仍然只会在向主源表插入数据时被触发,但 CTE 会在每次插入时被重新执行,这可能导致不必要的开销,特别是当被引用的表很大时。
例如,
WITH recent_users AS (
SELECT Id FROM stackoverflow.users WHERE CreationDate > now() - INTERVAL 7 DAY
)
SELECT * FROM stackoverflow.posts WHERE OwnerUserId IN (SELECT Id FROM recent_users)
在这种情况下,每次向 posts 插入数据时,都会重新计算 users CTE,而当插入新的用户时,materialized view 不会更新——只有在插入新的 posts 时才会更新。
通常,应将 CTE 用于对与 materialized view 关联的同一源表进行操作的逻辑,或者确保被引用的表足够小,不太可能造成性能瓶颈。或者,可以考虑对 Materialized Views 中的 JOIN 使用相同的优化方法。