将数据从 SQL Server 流式传输到 ClickHouse 实现快速分析:分步指南
在本文中,我们将通过一个教程,演示如何将数据从 SQL Server 流式传输到 ClickHouse。对于需要为内部或面向客户的仪表盘提供超高速分析的场景,ClickHouse 是理想选择。我们会一步一步讲解如何设置这两个数据库、如何将它们连接起来,以及最后如何使用 Streamkap 来流式传输数据。如果 SQL Server 负责你的日常业务处理,而你又需要借助 ClickHouse 的高性能来进行分析,那么你来对地方了。
为什么要将数据从 SQL Server 流式传输到 ClickHouse?
如果你在看这篇文档,很可能已经遇到了这样的痛点:SQL Server 在事务处理方面非常可靠,但并不是为运行高负载的实时分析查询而设计的。
这正是 ClickHouse 发挥优势的地方。ClickHouse 为分析而生,即使在超大数据集上也能提供极快的聚合和报表能力。因此,搭建一个将事务数据持续推送到 ClickHouse 的 CDC 流式管道,可以让你运行极其快速的报表——非常适合运营、产品团队或客户可视化看板。
典型用例:
- 内部报表,不会拖慢生产应用的性能
- 面向客户的仪表盘,需要快速响应并且始终保持最新
- 事件流处理,例如保持用户行为日志的实时更新,便于分析
开始前需要准备的内容
在深入细节之前,请先准备好以下内容:
先决条件
-
一个正在运行的 SQL Server 实例
-
在本教程中,我们使用 AWS RDS for SQL Server,但任何现代的 SQL Server 实例都可以。从零开始设置 AWS SQL Server。
-
一个 ClickHouse 实例
-
自托管或云环境均可。从零开始设置 ClickHouse。
-
Streamkap
-
该工具将作为数据流处理管道的核心组件。
连接信息
请确保已具备:
- SQL Server 的服务器地址、端口、用户名和密码。建议为 Streamkap 创建单独的用户和角色,以便访问你的 SQL Server 数据库。查看我们的文档以获取配置详情。
- ClickHouse 的服务器地址、端口、用户名和密码。ClickHouse 中的 IP 访问列表决定了哪些服务可以连接到你的 ClickHouse 数据库。请按照此处的说明进行配置。
- 你希望进行流式传输的表——目前先从一张表开始即可
将 SQL Server 设置为数据源
下面开始。
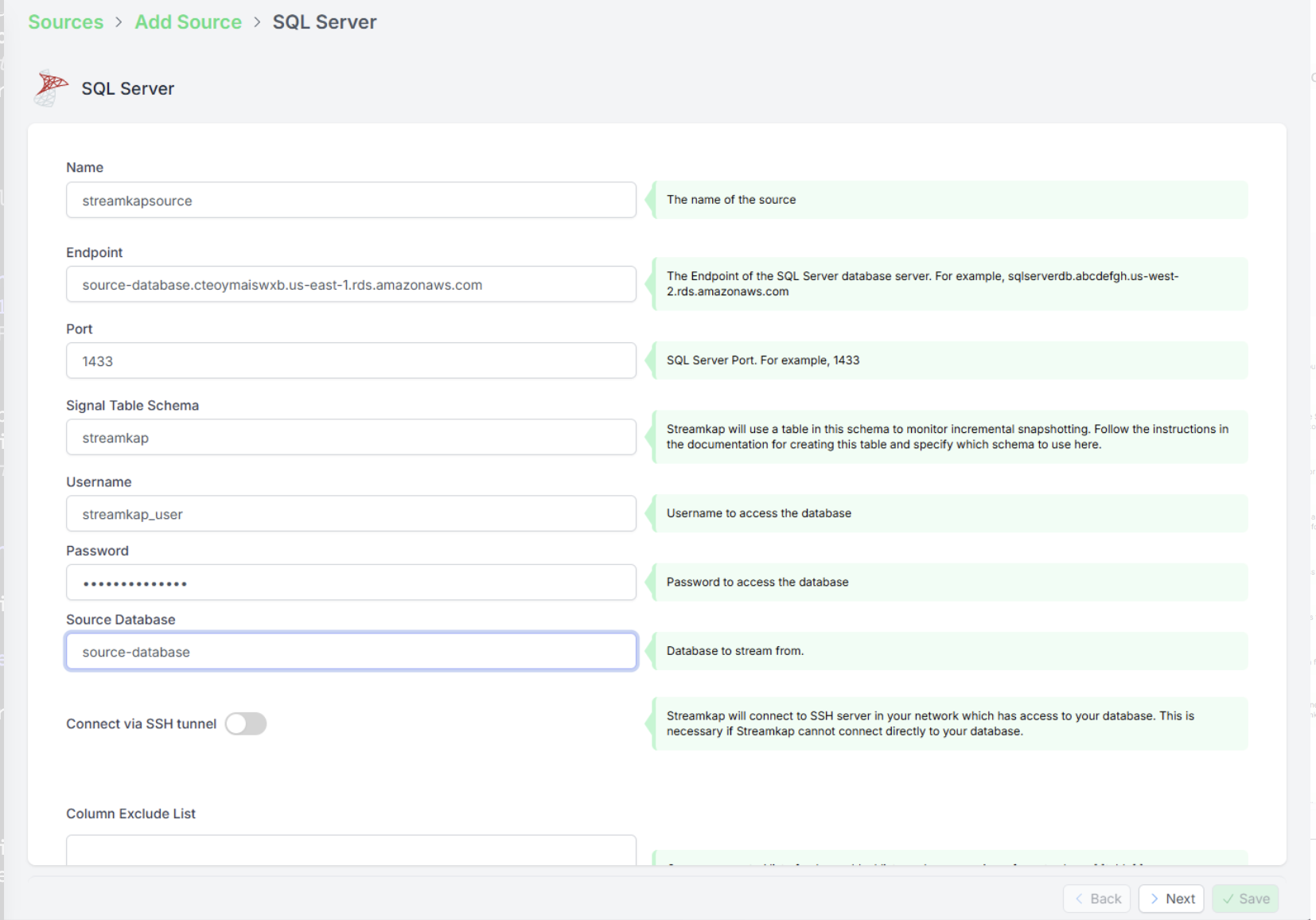
步骤 1:在 Streamkap 中创建 SQL Server Source
首先需要设置 source(数据源)连接。这样 Streamkap 才能知道应该从哪里获取变更数据。
按以下步骤操作:
- 打开 Streamkap,进入 Sources 部分。
- 创建一个新的 source(数据源)。
- 为它起一个易于识别的名称(例如:sqlserver-demo-source)。
- 填写 SQL Server 连接信息:
- Host(例如:your-db-instance.rds.amazonaws.com)
- Port(SQL Server 的默认端口是 3306)
- Username 和 Password
- Database 名称
幕后发生了什么
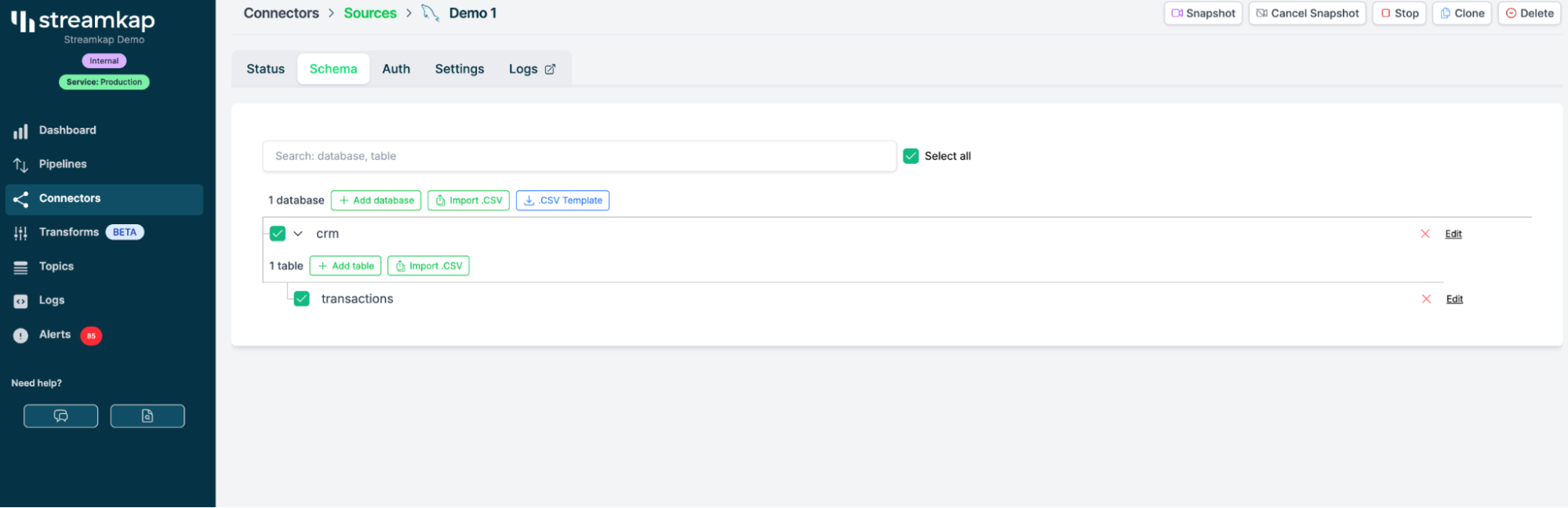
完成此配置后,Streamkap 会连接到 SQL Server 并自动发现其中的表。对于本次演示,我们将选择一张已经有数据持续流入的表,比如 events 或 transactions。
创建 ClickHouse 目标
现在我们来配置要发送所有这些数据的目标。
步骤 2:在 Streamkap 中添加 ClickHouse 目标端
与创建源类似,我们将使用 ClickHouse 连接信息创建一个目标端。
步骤:
- 在 Streamkap 中进入 Destinations 部分。
- 新建一个 Destination——选择 ClickHouse 作为 Destination 类型。
- 输入你的 ClickHouse 信息:
- Host
- Port(默认是 9000)
- Username 和 Password
- Database 名称
示例截图:在 Streamkap 仪表盘中添加新的 ClickHouse Destination。
Upsert 模式:是什么?
这是一个重要步骤:我们希望使用 ClickHouse 的 “upsert” 模式——其底层使用的是 ClickHouse 中的 ReplacingMergeTree 引擎。这样可以高效地合并新写入的记录,并在数据摄取之后处理更新,利用 ClickHouse 所谓的 “part merging”。
- 这可以确保当 SQL Server 端的数据发生变化时,目标表不会被重复数据填满。
处理 Schema 演进
当你的应用在运行中,开发人员不断按需添加新列时,ClickHouse 和 SQL Server 有时不会拥有完全相同的列。
- 好消息:Streamkap 可以处理基本的 schema 演进。这意味着如果你在 SQL Server 中添加了一个新列,它也会出现在 ClickHouse 端。
只需在目标端设置中选择“schema evolution”。如有需要,之后你随时可以再进行调整。
构建流式管道
在源和目标都配置完成后,就到了最有趣的环节——开始流式传输数据!
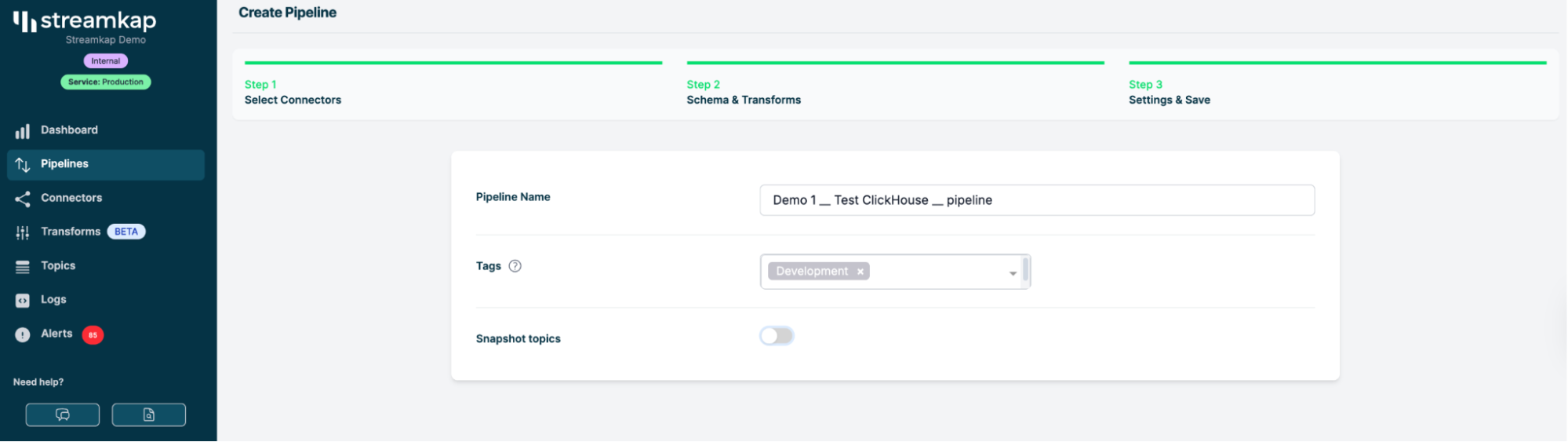
步骤 3:在 Streamkap 中配置 Pipeline
Pipeline 设置
-
在 Streamkap 中进入 Pipelines 选项卡。
-
创建一个新的 pipeline。
-
选择你的 SQL Server 源(sqlserver-demo-source)。
-
选择你的 ClickHouse 目标(clickhouse-tutorial-destination)。
-
选择你想要进行流式传输的表——比如 events。
-
配置为使用 Change Data Capture(CDC)。
- 对于这次运行,我们只会流式传输新数据(可以先跳过回填,先专注于 CDC 事件)。
Pipeline 设置截图——展示如何选择源、目标和表。
是否需要回填?
你可能会问:我是否应该回填历史数据?
在很多分析场景下,你可能只需要从现在开始以流式方式同步后续变更,但也可以随时再回去加载更早的数据。
除非你有明确需求,否则目前可以先选择“不回填(don’t backfill)”选项。
流式传输实战:预期效果
现在你的 pipeline 已经配置完成并开始运行!
步骤 4:观察数据流
将会发生如下过程:
- 当新数据写入 SQL Server 上的源表时,Streamkap 数据管道会捕获这些变更并发送到 ClickHouse。
- ClickHouse(借助 ReplacingMergeTree 和数据分片合并)摄取这些行并合并更新。
- 表结构会自动跟进 —— 在 SQL Server 中新增列,这些列也会在 ClickHouse 中显示出来。
通过实时仪表盘或日志,你可以看到 ClickHouse 和 SQL Server 中的行数在实时增长。
你可以直观地看到,随着 SQL Server 接收数据,ClickHouse 中的行数不断攀升。
在高负载场景下可能会出现一定延迟,但在大多数场景中都能实现近乎实时的流式传输。
幕后原理:Streamkap 实际在做什么?
先简单了解一下它在幕后做了什么:
- Streamkap 会监听 SQL Server 的二进制日志(与用于复制的日志相同)。
- 一旦在你的表中有行被插入、更新或删除,Streamkap 就会捕获该事件。
- 它会将事件转换成 ClickHouse 能理解的格式并发送过去——在你的分析数据库中即时应用这些变更。
这不仅仅是 ETL——而是完整的变更数据捕获(CDC),并以实时流的方式传输。
高级选项
Upsert 模式 vs. Insert 模式
单纯对每一行执行插入(Insert 模式),和同时确保更新与删除也被同步(Upsert 模式),两者有什么区别?
- Insert 模式:每一行新数据都会被添加——即使是更新操作,你也会得到重复的行。
- Upsert 模式:对已有行的更新会覆盖现有内容——在保持分析数据新鲜且干净方面要好得多。
处理 Schema 变更
应用会变化,你的 schema 也会随之变化。使用这个 pipeline:
- 给业务表新增一列?
Streamkap 会自动发现,并在 ClickHouse 端同样添加这一列。 - 移除一列?
取决于相关设置,你可能需要做一次迁移——但大多数新增列的处理都是顺畅无感的。
生产环境监控:持续监控数据管道
检查管道健康状况
Streamkap 提供了一个仪表板,可用于:
- 查看管道延迟(你的数据有多新?)
- 监控行数和吞吐量
- 在出现异常时接收告警通知
仪表板示例:延迟图表、行数、健康指标。
常见监控指标
- 延迟:ClickHouse 相比 SQL Server 滞后多久?
- 吞吐量:每秒处理的行数
- 错误率:应接近零
正式上线:在 ClickHouse 中执行查询
数据已经写入 ClickHouse,现在就可以使用各种高速分析工具来查询了。下面是一个基本示例:
将 ClickHouse 与 Grafana、Superset 或 Redash 等仪表盘工具结合使用,以构建功能全面的报表能力。
后续步骤与深入学习
本向导只是展示了你能做的事情的一小部分。在掌握基础之后,你可以继续探索:
- 设置过滤后的流(只同步部分表/列)
- 将多个数据源持续写入同一个分析型数据库
- 结合 S3/数据湖实现冷存储
- 在更改表结构时自动执行 schema 迁移
- 使用 SSL 和防火墙规则保障数据管道安全
请关注 Streamkap 博客,获取更多深入指南。
常见问题与故障排查
Q: 这能用于云数据库吗?
A: 可以!在本示例中我们使用的是 AWS RDS。只要确保放通了正确的端口即可。
Q: 性能方面怎么样?
A: ClickHouse 很快。瓶颈通常在于网络或源数据库的 binlog 写入速度,但在大多数情况下,你看到的延迟都会低于 1 秒。
Q: 也能处理删除操作吗?
A: 当然可以。在 upsert 模式下,删除操作同样会在 ClickHouse 中被标记并处理。
总结
以上就是使用 Streamkap 将 SQL Server 数据流式传输到 ClickHouse 的完整概览。该方案快速、灵活,非常适合既需要实时分析结果、又不希望影响生产数据库性能的团队。
准备好试一试了吗?
前往 注册页面,并告诉我们你是否希望我们进一步介绍以下主题:
- Upsert 与 Insert 的差异以及两者的实现细节
- 端到端延迟:多快能拿到最终分析视图?
- 性能调优与吞吐量
- 基于这套技术栈构建的真实生产环境看板
感谢阅读!祝你流式传输顺利。
