虽然可以使用schema 推断为 JSON 数据建立初始 schema,并直接查询原地存储的 JSON 数据文件 (例如 S3 中的文件) ,但你应当尽力为数据建立经过优化且带版本的 schema。下面我们将讨论对 JSON 结构进行建模的推荐方法。
静态 JSON 与动态 JSON
为 JSON 定义 schema 的首要任务是为每个键的值确定合适的类型。我们建议在 JSON 层级结构中的每一层、每个键上递归地应用以下规则,以确定每个键的合适类型。
- 基本类型(Primitive types) - 如果键的值是基本类型(primitive type),无论它位于子对象中还是根对象上,都应根据通用 schema 设计最佳实践和类型优化规则来选择其类型。基本类型数组(例如下面的
phone_numbers)可以建模为 Array(<type>),如 Array(String)。
- 静态 vs 动态 - 如果键的值是复杂对象,即对象或对象数组,需要先判断它是否会发生变化。对于很少新增键的对象,如果可以预期新键的出现,并能通过
ALTER TABLE ADD COLUMN 进行 schema 变更来处理,则可以视为静态。这也包括那些在部分 JSON 文档中只提供部分键的对象。那些频繁新增新键且/或新增键不可预测的对象应视为动态。唯一的例外是包含数百或数千个子键的结构,为了使用上的便利,这类结构可以直接视为动态。
要判断某个值是静态还是动态,请参阅下文相关章节:处理静态对象和处理动态对象。
重要说明: 上述规则应递归应用。如果某个键的值被判定为动态,则无需进一步评估,可直接遵循处理动态对象中的指南。如果该对象为静态,则继续评估其子键,直到键值为基本类型或遇到动态键为止。
为说明这些规则,我们使用下面这个表示某个用户的 JSON 示例:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics",
"labels": {
"type": "database systems",
"founded": "2021"
}
},
"dob": "2007-03-31",
"tags": {
"hobby": "Databases",
"holidays": [
{
"year": 2024,
"location": "Azores, Portugal"
}
],
"car": {
"model": "Tesla",
"year": 2023
}
}
}
应用这些规则:
- 根键
name、username、email、website 可以用类型 String 表示。列 phone_numbers 是一个基础列,类型为 Array(String),其中 dob 和 id 的类型分别为 Date 和 UInt32。
- 不会向
address 对象中添加新的键(只会新增 address 对象),因此可以将其视为静态。如果向下递归展开,除 geo 之外,所有子列都可以视为基础类型(并使用类型 String),而 geo 也是一个静态结构,包含两个 Float32 列:lat 和 lon。
- 列
tags 是动态的。我们假设可以向该对象中添加任意类型和结构的新标签。
- 对象
company 是静态的,并且始终最多只包含这 3 个指定的键。子键 name 和 catchPhrase 类型为 String。键 labels 是动态的。我们假设可以向该对象中添加任意标签,其值始终为字符串类型的键值对。
注意
具有数百或数千个静态键的结构也可以被视为动态结构,因为几乎不可能为这些键静态声明所有列。不过,在可能的情况下,请尽量跳过那些不需要的路径,以同时节省存储和推断开销。
处理静态结构
我们建议对静态结构使用命名元组(即 Tuple)来表示。对象数组可以使用元组数组来表示,即 Array(Tuple)。在元组内部,列及其对应的类型也应按照相同的规则进行定义。这样一来,为了表示嵌套对象,就可能会出现嵌套的 Tuple,如下所示。
为便于说明,我们沿用前文的 JSON person 示例,但省略其中的动态对象:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics"
},
"dob": "2007-03-31"
}
该表的表结构如下:
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String),
`dob` Date
)
ENGINE = MergeTree
ORDER BY username
请注意,company 列被定义为 Tuple(catchPhrase String, name String)。address 键使用 Array(Tuple),并通过嵌套的 Tuple 来表示 geo 列。
可以按照当前结构将 JSON 插入到此表中:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
在上面的示例中,虽然数据量很小,但如下所示,我们仍然可以通过其以句点分隔的名称来查询这些元组列。
SELECT
address.street,
company.name
FROM people
┌─address.street────┬─company.name─┐
│ ['Victor Plains'] │ ClickHouse │
└───────────────────┴──────────────┘
请注意,address.street 列是以 Array 形式返回的。要按位置查询数组中的特定对象,需要在列名后指定数组的偏移量。例如,要访问第一个地址中的街道名称:
SELECT address.street[1] AS street
FROM people
┌─street────────┐
│ Victor Plains │
└───────────────┘
1 row in set. Elapsed: 0.001 sec.
从 24.12 版本开始,子列也可以用作排序键:
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String),
`dob` Date
)
ENGINE = MergeTree
ORDER BY company.name
处理默认值
即使 JSON 对象是结构化的,它们通常也是稀疏的,只提供已知键中的一部分。幸运的是,Tuple 类型并不要求 JSON 载荷中必须包含所有列。如果未提供,将会使用默认值。
回顾我们之前的 people 表,以及下面这个稀疏的 JSON,其中缺少键 suite、geo、phone_numbers 和 catchPhrase。
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"city": "Wisokyburgh",
"zipcode": "90566-7771"
}
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse"
},
"dob": "2007-03-31"
}
可以看到下面这一行数据已成功插入:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","city":"Wisokyburgh","zipcode":"90566-7771"}],"website":"clickhouse.com","company":{"name":"ClickHouse"},"dob":"2007-03-31"}
Ok.
1 row in set. Elapsed: 0.002 sec.
查询这一行时,我们可以看到,省略的列(包括子对象)都使用了默认值:
SELECT *
FROM people
FORMAT PrettyJSONEachRow
{
"id": "1",
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"city": "Wisokyburgh",
"geo": {
"lat": 0,
"lng": 0
},
"street": "Victor Plains",
"suite": "",
"zipcode": "90566-7771"
}
],
"phone_numbers": [],
"website": "clickhouse.com",
"company": {
"catchPhrase": "",
"name": "ClickHouse"
},
"dob": "2007-03-31"
}
1 row in set. Elapsed: 0.001 sec.
区分空值和 null
如果需要区分“值为空”和“值未提供”这两种情况,可以使用 Nullable 类型。除非确有必要,否则应尽量避免使用 Nullable 类型,因为这会对这些列的存储和查询性能产生负面影响。
处理新增列
当 JSON 键是固定不变时,采用结构化方式是最简单的。但即使如此,只要可以事先规划模式的变更(即预先知道会新增哪些键,并可以相应修改模式),仍然可以使用这种方法。
请注意,ClickHouse 默认会忽略那些在负载中提供但在模式中不存在的 JSON 键。请看下面这个经过修改的 JSON 负载,其中新增了一个 nickname 键:
{
"id": 1,
"name": "Clicky McCliickHouse",
"nickname": "Clicky",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics"
},
"dob": "2007-03-31"
}
在忽略 nickname 键的情况下,可以成功插入该 JSON:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
Ok.
1 row in set. Elapsed: 0.002 sec.
可以使用 ALTER TABLE ADD COLUMN 命令向表结构中添加列。可以通过 DEFAULT 子句指定默认值,在后续插入时如果未显式指定该列,将会使用该默认值。在创建该列之前插入的、因此不包含该值的行,也会返回此默认值。如果未指定 DEFAULT 值,则会使用该数据类型的默认值。
例如:
-- insert initial row (nickname will be ignored)
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
-- add column
ALTER TABLE people
(ADD COLUMN `nickname` String DEFAULT 'no_nickname')
-- insert new row (same data different id)
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
-- select 2 rows
SELECT id, nickname FROM people
┌─id─┬─nickname────┐
│ 2 │ Clicky │
│ 1 │ no_nickname │
└────┴─────────────┘
2 rows in set. Elapsed: 0.001 sec.
处理半结构化/动态结构
如果 JSON 数据是半结构化的,其中的键可以动态添加和/或具有多种类型,则推荐使用 JSON 类型。
更具体地说,在以下情况中应使用 JSON 类型:
- 具有不可预测的键,这些键会随时间变化。
- 包含类型各异的值(例如,同一路径下有时是字符串,有时是数字)。
- 需要在模式(schema)上保持灵活,无法采用严格类型定义。
- 你有数百甚至上千个路径,这些路径本身是静态的,但数量过多,不现实逐一显式声明。这种情况相对少见。
回顾我们前面的人物 JSON 示例,其中 company.labels 对象被判断为动态。
假设 company.labels 包含任意键。此外,该结构中任意键的类型在不同行之间可能并不一致。例如:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics",
"labels": {
"type": "database systems",
"founded": "2021",
"employees": 250
}
},
"dob": "2007-03-31",
"tags": {
"hobby": "Databases",
"holidays": [
{
"year": 2024,
"location": "Azores, Portugal"
}
],
"car": {
"model": "Tesla",
"year": 2023
}
}
}
{
"id": 2,
"name": "Analytica Rowe",
"username": "Analytica",
"address": [
{
"street": "Maple Avenue",
"suite": "Apt. 402",
"city": "Dataford",
"zipcode": "11223-4567",
"geo": {
"lat": 40.7128,
"lng": -74.006
}
}
],
"phone_numbers": [
"123-456-7890",
"555-867-5309"
],
"website": "fastdata.io",
"company": {
"name": "FastData Inc.",
"catchPhrase": "Streamlined analytics at scale",
"labels": {
"type": [
"real-time processing"
],
"founded": 2019,
"dissolved": 2023,
"employees": 10
}
},
"dob": "1992-07-15",
"tags": {
"hobby": "Running simulations",
"holidays": [
{
"year": 2023,
"location": "Kyoto, Japan"
}
],
"car": {
"model": "Audi e-tron",
"year": 2022
}
}
}
鉴于不同对象之间 company.labels 列在键和值类型方面具有动态特性,我们有多种方案来对这些数据建模:
- 单个 JSON 列 - 将整个 schema 表示为一个
JSON 列,允许其内部的所有结构都是动态的。
- 针对性 JSON 列 - 仅对
company.labels 列使用 JSON 类型,对其他所有列保留上文使用的结构化 schema。
尽管第一种方法与之前的方法论不一致,但单个 JSON 列的方法对于原型设计和数据工程任务非常有用。
对于大规模生产环境中的 ClickHouse 部署,我们建议尽可能明确定义结构,并在可行的情况下仅对特定的动态子结构使用 JSON 类型。
严格的 schema 具有多项优势:
- 数据验证 – 强制使用严格的 schema 可以避免(除特定结构外的)列爆炸风险。
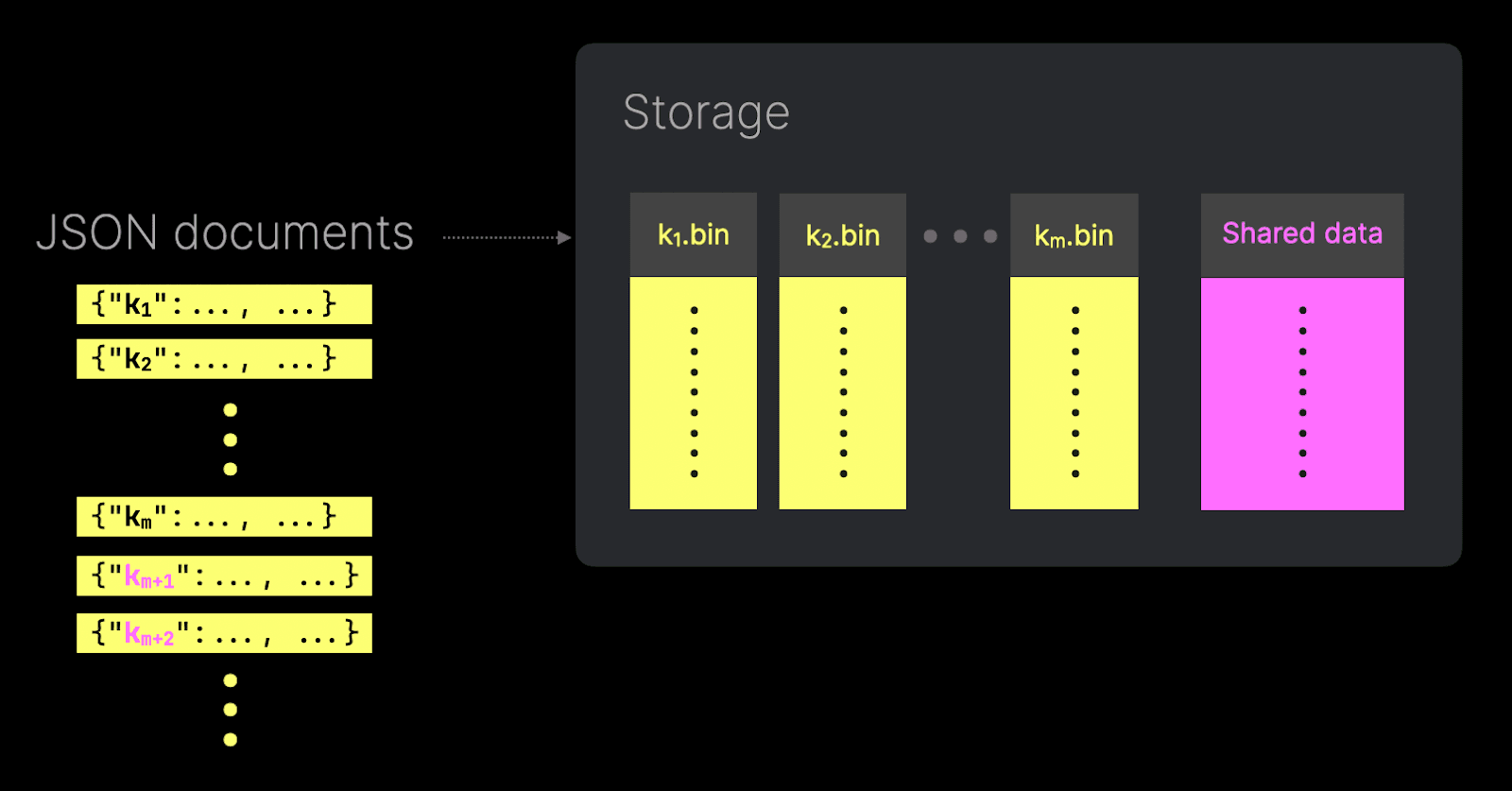
- 避免列爆炸风险 - 虽然 JSON 类型可以扩展到潜在数千个列(其中子列作为独立列存储),但这可能导致列文件数量爆炸式增长,即创建过多列文件,从而影响性能。为缓解这一问题,JSON 底层使用的 Dynamic type 提供了一个
max_dynamic_paths 参数,用于限制以独立列文件形式存储的唯一路径数量。一旦达到该阈值,额外的路径会存储在一个共享列文件中,并使用紧凑的编码格式,从而在支持灵活数据摄取的同时,保持性能和存储效率。然而,访问这个共享列文件的性能不如独立列文件。需要注意的是,JSON 列可以与类型提示一起使用。带有类型提示的列将提供与独立列相同的性能。
- 更简单的路径和类型自省 - 尽管 JSON 类型支持自省函数来确定已推断的类型和路径,但静态结构在探索时(例如使用
DESCRIBE)可能更简单。
单个 JSON 列
这种方法对原型设计和数据工程任务很有用。在生产环境中,仅在必要时将 JSON 用于动态子结构。
此处单个 JSON 列的 schema 很简单:
SET enable_json_type = 1;
CREATE TABLE people
(
`json` JSON(username String)
)
ENGINE = MergeTree
ORDER BY json.username;
注意
我们在 JSON 定义中为 username 列提供了一个类型提示,因为我们在排序/主键中使用它。这样可以帮助 ClickHouse 确认该列一定不会为 null,并确保它能确定应使用哪个 username 子列(对于每种类型可能存在多个子列,否则就会产生歧义)。
可以使用 JSONAsObject 格式向上述表中插入行:
INSERT INTO people FORMAT JSONAsObject
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.028 sec.
INSERT INTO people FORMAT JSONAsObject
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.004 sec.
SELECT *
FROM people
FORMAT Vertical
Row 1:
──────
json: {"address":[{"city":"Dataford","geo":{"lat":40.7128,"lng":-74.006},"street":"Maple Avenue","suite":"Apt. 402","zipcode":"11223-4567"}],"company":{"catchPhrase":"Streamlined analytics at scale","labels":{"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]},"name":"FastData Inc."},"dob":"1992-07-15","id":"2","name":"Analytica Rowe","phone_numbers":["123-456-7890","555-867-5309"],"tags":{"car":{"model":"Audi e-tron","year":"2022"},"hobby":"Running simulations","holidays":[{"location":"Kyoto, Japan","year":"2023"}]},"username":"Analytica","website":"fastdata.io"}
Row 2:
──────
json: {"address":[{"city":"Wisokyburgh","geo":{"lat":-43.9509,"lng":-34.4618},"street":"Victor Plains","suite":"Suite 879","zipcode":"90566-7771"}],"company":{"catchPhrase":"The real-time data warehouse for analytics","labels":{"employees":"250","founded":"2021","type":"database systems"},"name":"ClickHouse"},"dob":"2007-03-31","email":"clicky@clickhouse.com","id":"1","name":"Clicky McCliickHouse","phone_numbers":["010-692-6593","020-192-3333"],"tags":{"car":{"model":"Tesla","year":"2023"},"hobby":"Databases","holidays":[{"location":"Azores, Portugal","year":"2024"}]},"username":"Clicky","website":"clickhouse.com"}
2 rows in set. Elapsed: 0.005 sec.
我们可以使用自省函数来确定推断出的子列及其数据类型。例如:
SELECT JSONDynamicPathsWithTypes(json) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"address": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"company.catchPhrase": "String",
"company.labels.employees": "Int64",
"company.labels.founded": "String",
"company.labels.type": "String",
"company.name": "String",
"dob": "Date",
"email": "String",
"id": "Int64",
"name": "String",
"phone_numbers": "Array(Nullable(String))",
"tags.car.model": "String",
"tags.car.year": "Int64",
"tags.hobby": "String",
"tags.holidays": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"website": "String"
}
}
{
"paths": {
"address": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"company.catchPhrase": "String",
"company.labels.dissolved": "Int64",
"company.labels.employees": "Int64",
"company.labels.founded": "Int64",
"company.labels.type": "Array(Nullable(String))",
"company.name": "String",
"dob": "Date",
"id": "Int64",
"name": "String",
"phone_numbers": "Array(Nullable(String))",
"tags.car.model": "String",
"tags.car.year": "Int64",
"tags.hobby": "String",
"tags.holidays": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"website": "String"
}
}
2 rows in set. Elapsed: 0.009 sec.
有关自省函数的完整列表,请参阅「自省函数」
可以访问子路径,使用 . 语法,例如:
SELECT json.name, json.email FROM people
┌─json.name────────────┬─json.email────────────┐
│ Analytica Rowe │ ᴺᵁᴸᴸ │
│ Clicky McCliickHouse │ clicky@clickhouse.com │
└──────────────────────┴───────────────────────┘
2 rows in set. Elapsed: 0.006 sec.
请注意,在某些行中缺失的列会以 NULL 返回。
另外,对于具有相同类型的路径,会为其分别创建独立的子列。例如,company.labels.type 会分别对应类型为 String 和 Array(Nullable(String)) 的子列。在可能的情况下,这两种子列都会被返回,但我们可以使用 .: 语法来仅针对特定的子列进行查询:
SELECT json.company.labels.type
FROM people
┌─json.company.labels.type─┐
│ database systems │
│ ['real-time processing'] │
└──────────────────────────┘
2 rows in set. Elapsed: 0.007 sec.
SELECT json.company.labels.type.:String
FROM people
┌─json.company⋯e.:`String`─┐
│ ᴺᵁᴸᴸ │
│ database systems │
└──────────────────────────┘
2 rows in set. Elapsed: 0.009 sec.
为了返回嵌套子对象,需要使用 ^。这是一个设计决策,用于避免在未显式请求的情况下读取大量的列。未使用 ^ 访问的对象将返回 NULL,如下所示:
-- sub objects will not be returned by default
SELECT json.company.labels
FROM people
┌─json.company.labels─┐
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
└─────────────────────┘
2 rows in set. Elapsed: 0.002 sec.
-- return sub objects using ^ notation
SELECT json.^company.labels
FROM people
┌─json.^`company`.labels─────────────────────────────────────────────────────────────────┐
│ {"employees":"250","founded":"2021","type":"database systems"} │
│ {"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]} │
└────────────────────────────────────────────────────────────────────────────────────────┘
2 rows in set. Elapsed: 0.004 sec.
针对性 JSON 列
虽然在原型设计和数据工程场景中很有用,但在生产环境中,我们建议在可能的情况下使用显式 schema 定义。
我们之前的示例可以使用单个 JSON 列来表示 company.labels 列。
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String, labels JSON),
`dob` Date,
`tags` String
)
ENGINE = MergeTree
ORDER BY username
我们可以使用 JSONEachRow 格式向该表插入数据:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
SELECT *
FROM people
FORMAT Vertical
Row 1:
──────
id: 2
name: Analytica Rowe
username: Analytica
email:
address: [('Dataford',(40.7128,-74.006),'Maple Avenue','Apt. 402','11223-4567')]
phone_numbers: ['123-456-7890','555-867-5309']
website: fastdata.io
company: ('Streamlined analytics at scale','FastData Inc.','{"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]}')
dob: 1992-07-15
tags: {"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}
Row 2:
──────
id: 1
name: Clicky McCliickHouse
username: Clicky
email: clicky@clickhouse.com
address: [('Wisokyburgh',(-43.9509,-34.4618),'Victor Plains','Suite 879','90566-7771')]
phone_numbers: ['010-692-6593','020-192-3333']
website: clickhouse.com
company: ('The real-time data warehouse for analytics','ClickHouse','{"employees":"250","founded":"2021","type":"database systems"}')
dob: 2007-03-31
tags: {"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}
2 rows in set. Elapsed: 0.005 sec.
自省函数 可用于确定为 company.labels 列推断出的路径和类型。
SELECT JSONDynamicPathsWithTypes(company.labels) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"dissolved": "Int64",
"employees": "Int64",
"founded": "Int64",
"type": "Array(Nullable(String))"
}
}
{
"paths": {
"employees": "Int64",
"founded": "String",
"type": "String"
}
}
2 rows in set. Elapsed: 0.003 sec.
使用类型提示和跳过路径
类型提示允许我们为某个路径及其子列指定类型,从而避免不必要的类型推断。请看下面的示例,我们为 JSON 列 company.labels 中的 JSON 键 dissolved、employees 和 founded 明确指定了类型。
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(
city String,
geo Tuple(
lat Float32,
lng Float32),
street String,
suite String,
zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(
catchPhrase String,
name String,
labels JSON(dissolved UInt16, employees UInt16, founded UInt16)),
`dob` Date,
`tags` String
)
ENGINE = MergeTree
ORDER BY username
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
请注意,这些列现在都具有我们显式指定的类型:
SELECT JSONAllPathsWithTypes(company.labels) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"dissolved": "UInt16",
"employees": "UInt16",
"founded": "UInt16",
"type": "String"
}
}
{
"paths": {
"dissolved": "UInt16",
"employees": "UInt16",
"founded": "UInt16",
"type": "Array(Nullable(String))"
}
}
2 rows in set. Elapsed: 0.003 sec.
此外,我们可以使用 SKIP 和 SKIP REGEXP 参数跳过 JSON 中不想存储的路径,以尽量减少存储占用,并避免对不需要的路径进行不必要的自动推断。例如,假设我们对上述数据使用单个 JSON 列,则可以跳过 address 和 company 这两个路径:
CREATE TABLE people
(
`json` JSON(username String, SKIP address, SKIP company)
)
ENGINE = MergeTree
ORDER BY json.username
INSERT INTO people FORMAT JSONAsObject
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONAsObject
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
请注意,这些列已经从数据中被排除:
SELECT *
FROM people
FORMAT PrettyJSONEachRow
{
"json": {
"dob" : "1992-07-15",
"id" : "2",
"name" : "Analytica Rowe",
"phone_numbers" : [
"123-456-7890",
"555-867-5309"
],
"tags" : {
"car" : {
"model" : "Audi e-tron",
"year" : "2022"
},
"hobby" : "Running simulations",
"holidays" : [
{
"location" : "Kyoto, Japan",
"year" : "2023"
}
]
},
"username" : "Analytica",
"website" : "fastdata.io"
}
}
{
"json": {
"dob" : "2007-03-31",
"email" : "clicky@clickhouse.com",
"id" : "1",
"name" : "Clicky McCliickHouse",
"phone_numbers" : [
"010-692-6593",
"020-192-3333"
],
"tags" : {
"car" : {
"model" : "Tesla",
"year" : "2023"
},
"hobby" : "Databases",
"holidays" : [
{
"location" : "Azores, Portugal",
"year" : "2024"
}
]
},
"username" : "Clicky",
"website" : "clickhouse.com"
}
}
2 rows in set. Elapsed: 0.004 sec.
类型提示不仅仅是避免不必要类型推断的一种方式——它还能完全消除存储和处理过程中的间接访问开销,并且允许指定最优的原始类型。带有类型提示的 JSON 路径始终与传统列一样存储,从而无需使用判别列(discriminator columns) 或在查询时进行动态解析。
这意味着在类型提示定义良好的情况下,嵌套 JSON 键可以获得与从一开始就被建模为顶层列时相同的性能和效率。
因此,对于大体结构一致但仍希望利用 JSON 灵活性的数据集,类型提示提供了一种便捷方式,无需重构模式(schema)或摄取管道即可保持性能。
配置动态路径
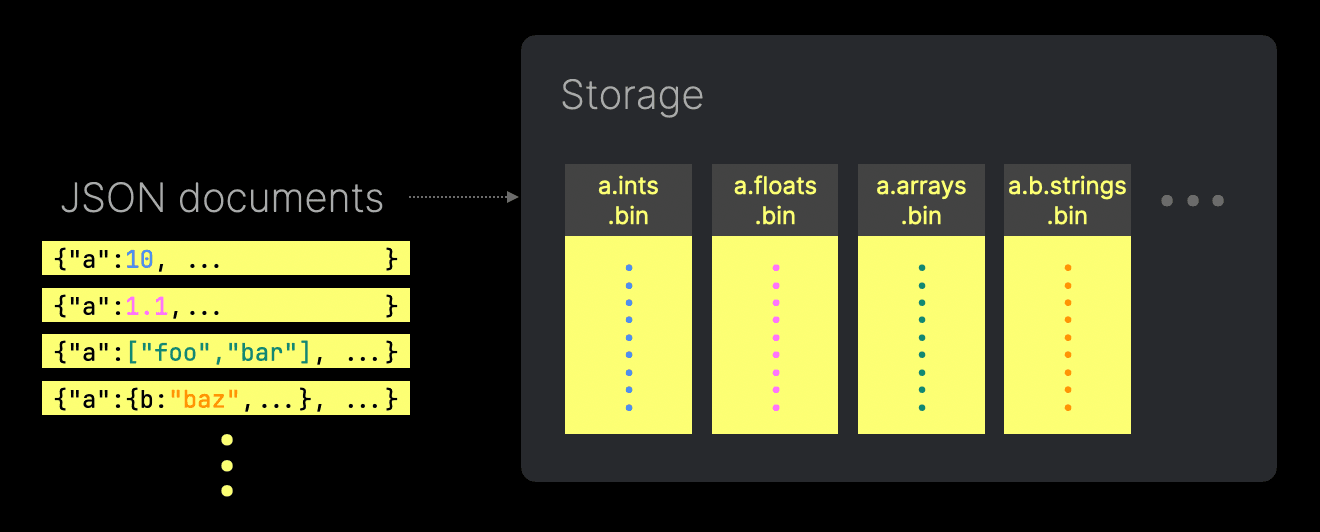
ClickHouse 将每个 JSON 路径作为子列存储在真正的列式存储布局中,从而获得与传统列相同的性能优势——例如压缩、SIMD 加速处理以及最小化磁盘 I/O。JSON 数据中每个唯一的路径与类型组合都可以在磁盘上对应自己的列文件。
例如,当两个 JSON 路径以不同的类型插入时,ClickHouse 会将每种具体类型的值存储在不同的子列中。这些子列可以被独立访问,从而减少不必要的 I/O。需要注意的是,当查询包含多种类型的列时,其值仍会以单个列式结果返回。
此外,通过利用偏移量,ClickHouse 确保这些子列保持稠密,对缺失的 JSON 路径不会存储默认值。此方式最大化了压缩效果并进一步降低 I/O。
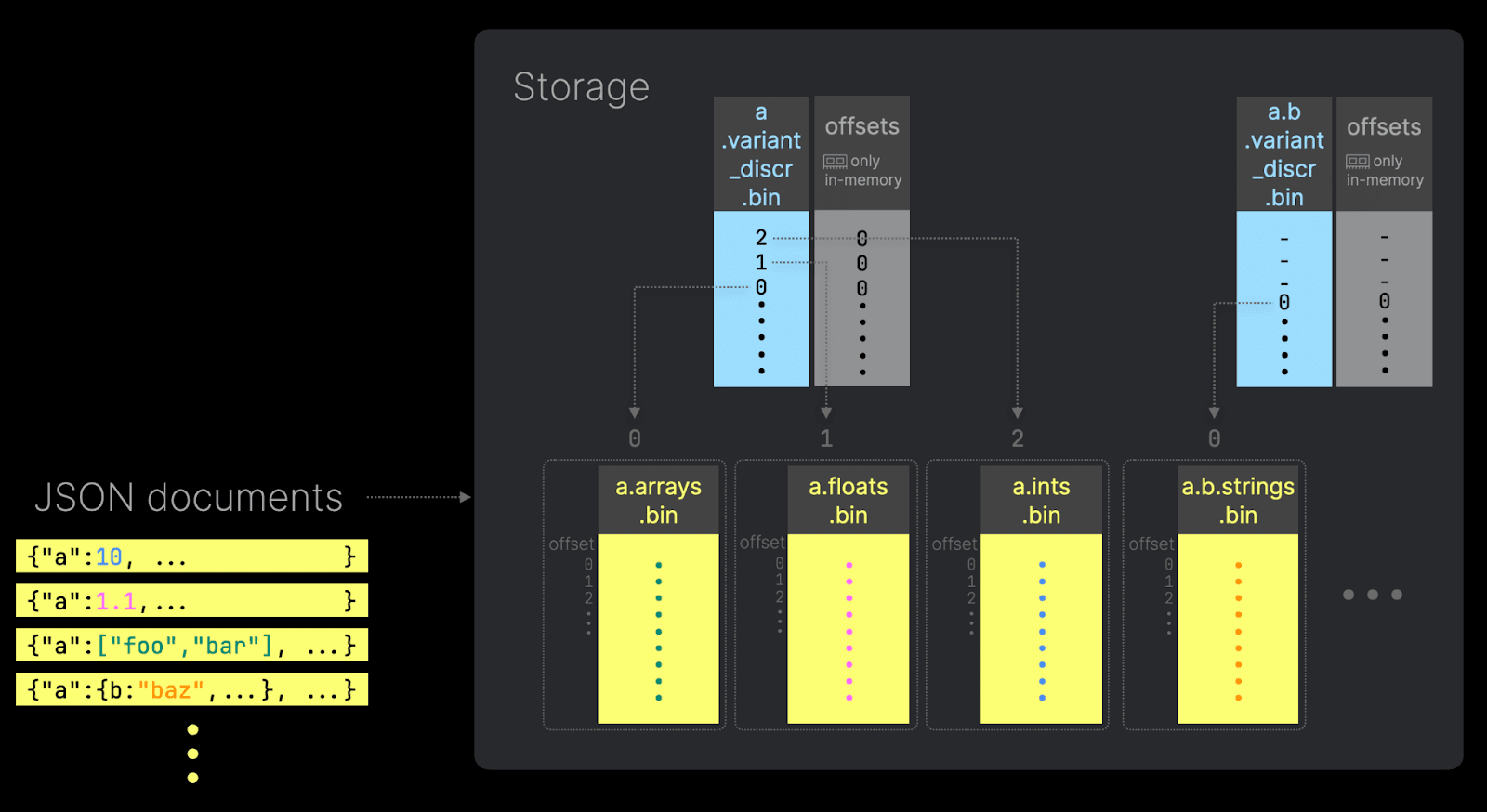
然而,在高基数或结构高度可变的 JSON 场景中——例如遥测管道、日志或机器学习特征存储——这种行为可能会导致列文件数量爆炸。每个新的唯一 JSON 路径都会生成一个新的列文件,而该路径下的每种类型变体都会再生成一个额外的列文件。虽然这对读取性能是最优的,但也会带来运维挑战:文件描述符耗尽、内存使用增加,以及由于大量小文件导致的合并变慢。
为缓解这一问题,ClickHouse 引入了「溢出子列」的概念:一旦不同 JSON 路径的个数超过某个阈值,额外的路径会被存储到一个共享文件中,并使用紧凑的编码格式。该文件仍然可以被查询,但无法享受到与专用子列相同的性能特性。
该阈值由 JSON 类型声明中的 max_dynamic_paths 参数控制。
CREATE TABLE logs
(
payload JSON(max_dynamic_paths = 500)
)
ENGINE = MergeTree
ORDER BY tuple();
避免将此参数设置得过高 —— 过大的数值会增加资源消耗并降低效率。一般经验是将其保持在 10,000 以下。对于结构高度动态的工作负载,使用类型提示(type hints)和 SKIP 参数来限制存储的内容。
对于对这种新列类型实现方式感兴趣的用户,我们建议阅读我们的详细博客文章 “A New Powerful JSON Data Type for ClickHouse”。