使用备份命令从自管理 ClickHouse 迁移到 ClickHouse Cloud 将数据从自管理 ClickHouse(OSS)迁移到 ClickHouse Cloud 主要有两种方法:
本迁移指南重点介绍 BACKUP/RESTORE 方法,并提供一个通过 S3 bucket 将开源 ClickHouse 中的数据库或完整服务迁移到 Cloud 的实用示例。
先决条件
为便于读者跟随并复现本指南中的步骤,我们将使用一个 Docker Compose 配置,
搭建一个包含两个分片、每个分片有两个副本的 ClickHouse 集群。
OSS 准备工作
我们首先会使用示例仓库中的一个 Docker Compose 配置来启动一个 ClickHouse 集群。
如果你已经有一个正在运行的 ClickHouse 集群,可以跳过这一步。
将 examples 仓库 克隆到本地环境。
在终端中 cd 到 examples/docker-compose-recipes/recipes/cluster_2S_2R。
确保 Docker 已在运行,然后启动 ClickHouse 集群:
你应该会看到:
[+] Running 7/7
✔ Container clickhouse-keeper-01 Created 0.1s
✔ Container clickhouse-keeper-02 Created 0.1s
✔ Container clickhouse-keeper-03 Created 0.1s
✔ Container clickhouse-01 Created 0.1s
✔ Container clickhouse-02 Created 0.1s
✔ Container clickhouse-04 Created 0.1s
✔ Container clickhouse-03 Created 0.1s
在该文件夹的根目录中打开一个新的终端窗口,并运行以下命令连接到集群的第一个节点:
docker exec -it clickhouse-01 clickhouse-client
从 MergeTree 表迁移到 ReplicatedMergeTree 表
ClickHouse Cloud 使用 SharedMergeTreeReplicatedMergeTree 的表转换为 SharedMergeTree 表。
如果您正在运行一个集群,您的表很可能已经在使用 ReplicatedMergeTree 引擎。
如果没有,则需要在备份之前将所有 MergeTree 表转换为 ReplicatedMergeTree。
为了演示如何将 MergeTree 表转换为 ReplicatedMergeTree,我们将从一个 MergeTree 表开始,并在稍后将其转换为 ReplicatedMergeTree。
我们将按照 New York taxi data guide 的前两步来创建一个示例表并向其中加载数据。
为方便起见,这些步骤在下方再次列出。
运行以下命令以创建一个新数据库,并从 S3 bucket 中向一个新表插入数据:
CREATE DATABASE nyc_taxi;
CREATE TABLE nyc_taxi.trips_small_adapted (
trip_id UInt32,
pickup_datetime DateTime,
dropoff_datetime DateTime,
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count UInt8,
trip_distance Float32,
fare_amount Float32,
extra Float32,
tip_amount Float32,
tolls_amount Float32,
total_amount Float32,
payment_type Enum('CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4, 'UNK' = 5),
pickup_ntaname LowCardinality(String),
dropoff_ntaname LowCardinality(String)
)
ENGINE = MergeTree
PRIMARY KEY (pickup_datetime, dropoff_datetime);
INSERT INTO nyc_taxi.trips_small_adapted
SELECT
trip_id,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
fare_amount,
extra,
tip_amount,
tolls_amount,
total_amount,
payment_type,
pickup_ntaname,
dropoff_ntaname
FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..2}.gz',
'TabSeparatedWithNames'
);
运行以下命令以 DETACH 该表。
DETACH TABLE nyc_taxi.trips_small_adapted;
然后将其附加为副本:
ATTACH TABLE nyc_taxi.trips_small_adapted AS REPLICATED;
最后,恢复副本的元数据:
SYSTEM RESTORE REPLICA nyc_taxi.trips_small_adapted;
检查是否已转换为 ReplicatedMergeTree:
SELECT engine
FROM system.tables
WHERE name = 'trips_small_adapted' AND database = 'nyc_taxi';
┌─engine──────────────┐
│ ReplicatedMergeTree │
└─────────────────────┘
现在,您已经可以继续配置 Cloud 服务,为稍后从 S3 bucket 中恢复备份做准备。
使用 ReplicatedMergeTree 的分布式表
如果您的部署使用跨多个分片的分布式表,则需要在每个节点上创建一个本地 ReplicatedMergeTree 表,并使用一个 Distributed 表作为查询入口。
运行以下命令,在集群的所有节点上创建本地复制表:
CREATE DATABASE IF NOT EXISTS nyc_taxi ON CLUSTER 'cluster_2S_2R';
CREATE TABLE nyc_taxi.trips_small_dist_local ON CLUSTER 'cluster_2S_2R'
(
trip_id UInt32,
pickup_datetime DateTime,
dropoff_datetime DateTime,
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count UInt8,
trip_distance Float32,
fare_amount Float32,
extra Float32,
tip_amount Float32,
tolls_amount Float32,
total_amount Float32,
payment_type Enum('CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4, 'UNK' = 5),
pickup_ntaname LowCardinality(String),
dropoff_ntaname LowCardinality(String)
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')
PRIMARY KEY (pickup_datetime, dropoff_datetime);
然后在其上创建 Distributed 表:
CREATE TABLE nyc_taxi.trips_small_dist ON CLUSTER 'cluster_2S_2R'
(
trip_id UInt32,
pickup_datetime DateTime,
dropoff_datetime DateTime,
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count UInt8,
trip_distance Float32,
fare_amount Float32,
extra Float32,
tip_amount Float32,
tolls_amount Float32,
total_amount Float32,
payment_type Enum('CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4, 'UNK' = 5),
pickup_ntaname LowCardinality(String),
dropoff_ntaname LowCardinality(String)
)
ENGINE = Distributed('cluster_2S_2R', 'nyc_taxi', 'trips_small_dist_local', rand());
通过分布式表插入数据:
INSERT INTO nyc_taxi.trips_small_dist
SELECT
trip_id,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
fare_amount,
extra,
tip_amount,
tolls_amount,
total_amount,
payment_type,
pickup_ntaname,
dropoff_ntaname
FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..2}.gz',
'TabSeparatedWithNames'
);
Cloud 准备工作
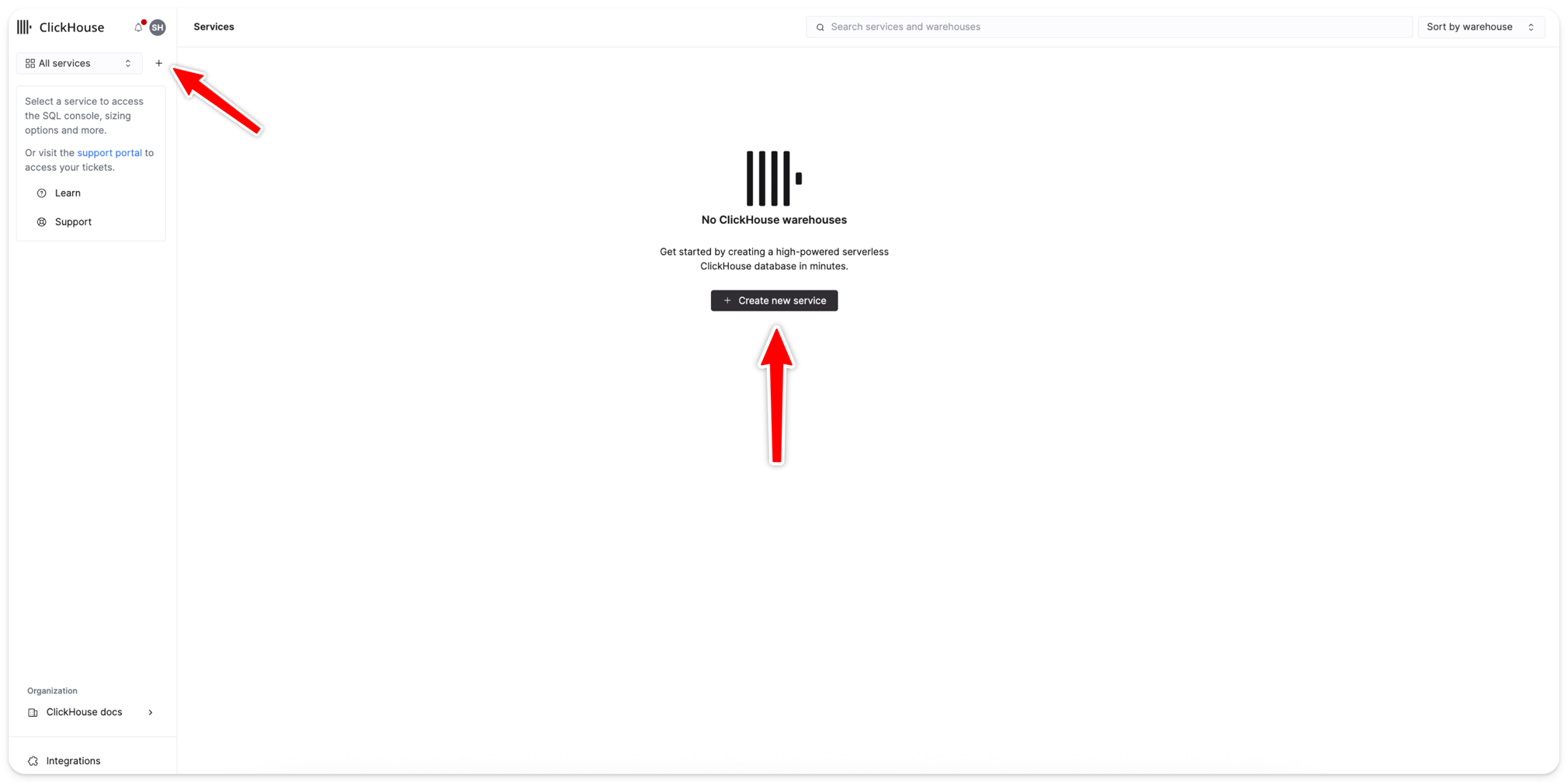
你将把数据恢复到一个新的 Cloud 服务中。
按照以下步骤创建一个新的 Cloud 服务。
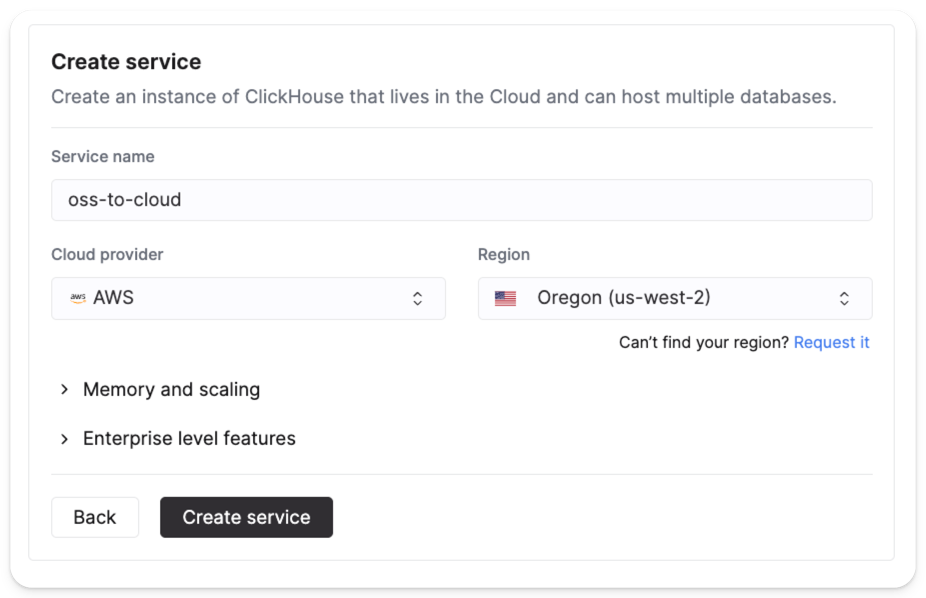
配置并创建服务
选择目标区域和配置,然后点击 Create service。
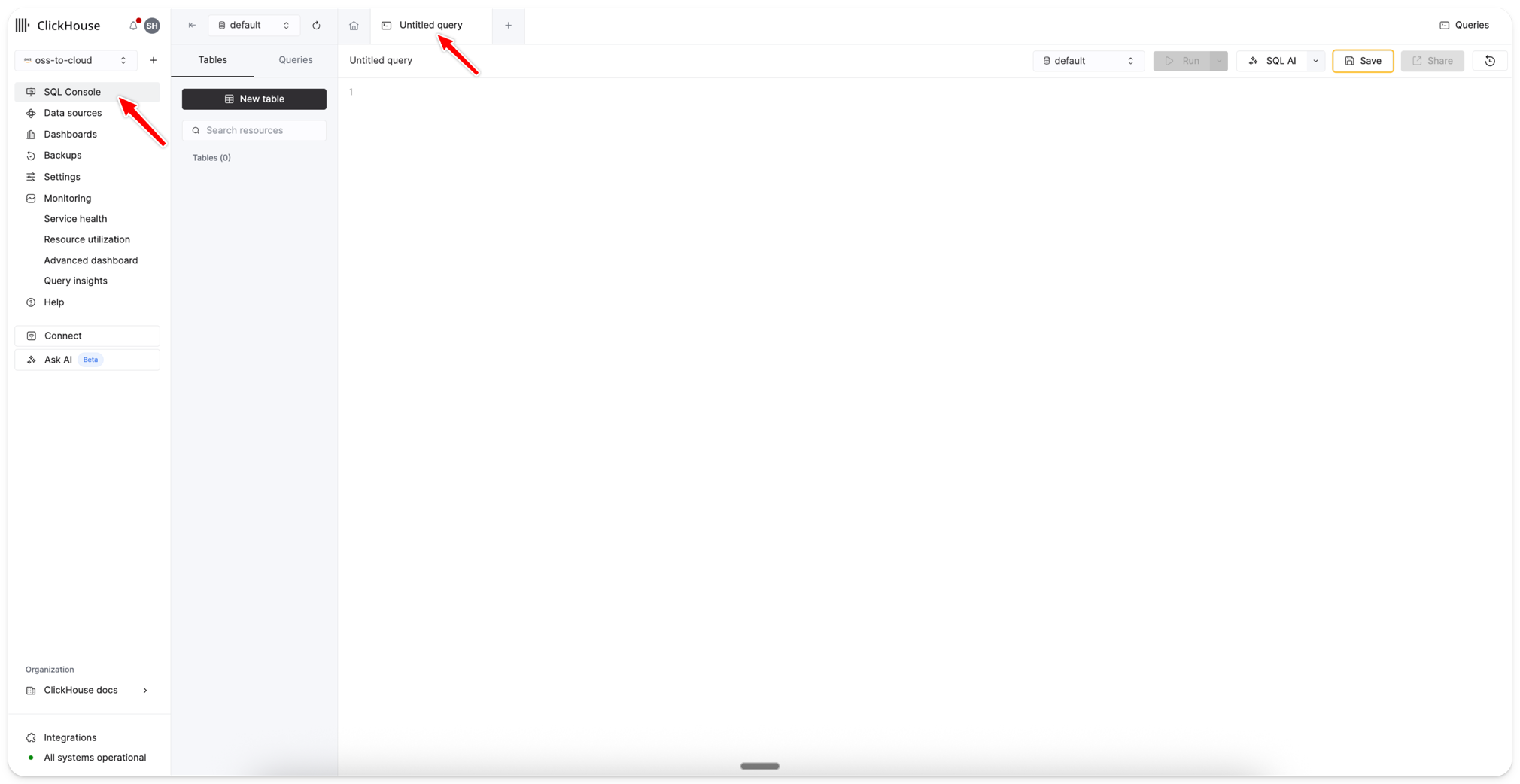
创建访问角色
创建访问角色 打开 SQL 控制台。
设置 S3 访问 要从 S3 恢复备份,需要在 ClickHouse Cloud 与 S3 bucket 之间配置安全访问。
按照 "安全访问 S3 数据" 中的步骤创建访问角色并获取该角色的 ARN。
在 "如何创建 S3 bucket 和 IAM 角色" 中创建的 S3 bucket 策略基础上,添加上一步获得的角色 ARN。
更新后的 S3 bucket 策略类似如下:
{
"Version": "2012-10-17",
"Id": "Policy123456",
"Statement": [
{
"Sid": "abc123",
"Effect": "Allow",
"Principal": {
"AWS": [
#highlight-start
"arn:aws:iam::123456789123:role/ClickHouseAccess-001",
"arn:aws:iam::123456789123:user/docs-s3-user"
#highlight-end
]
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::ch-docs-s3-bucket",
"arn:aws:s3:::ch-docs-s3-bucket/*"
]
}
]
}
该策略包含两个 ARN:
IAM user (docs-s3-user):允许自管理 ClickHouse 集群将数据备份到 S3ClickHouse Cloud role (ClickHouseAccess-001):允许 Cloud 服务从 S3 恢复数据 执行备份 (在自管理部署中)
必须分别备份每个分片。连接到每个分片上的一个节点,并为每个分片指定唯一的目标路径来运行
备份命令。
将 BUCKET_URL、KEY_ID 和 SECRET_KEY 替换为您自己的 AWS 凭证。
指南 "How to create an S3 bucket and IAM role"
介绍了在您尚未拥有这些凭证时如何获取它们。
分片 1:
BACKUP DATABASE nyc_taxi
TO S3(
'BUCKET_URL/backup_s1.zip',
'KEY_ID',
'SECRET_KEY'
)
分片 2:
BACKUP DATABASE nyc_taxi
TO S3(
'BUCKET_URL/backup_s2.zip',
'KEY_ID',
'SECRET_KEY'
)
如果一切配置正确,您会看到类似下面的响应,
其中包含分配给该备份的唯一 ID 以及备份的状态。
Query id: efcaf053-75ed-4924-aeb1-525547ea8d45
┌─id───────────────────────────────────┬─status─────────┐
│ e73b99ab-f2a9-443a-80b4-533efe2d40b3 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
单节点部署
如果您未使用分布式表,只需一条命令即可备份整个数据库:
BACKUP DATABASE nyc_taxi
TO S3(
'BUCKET_URL',
'KEY_ID',
'SECRET_KEY'
)
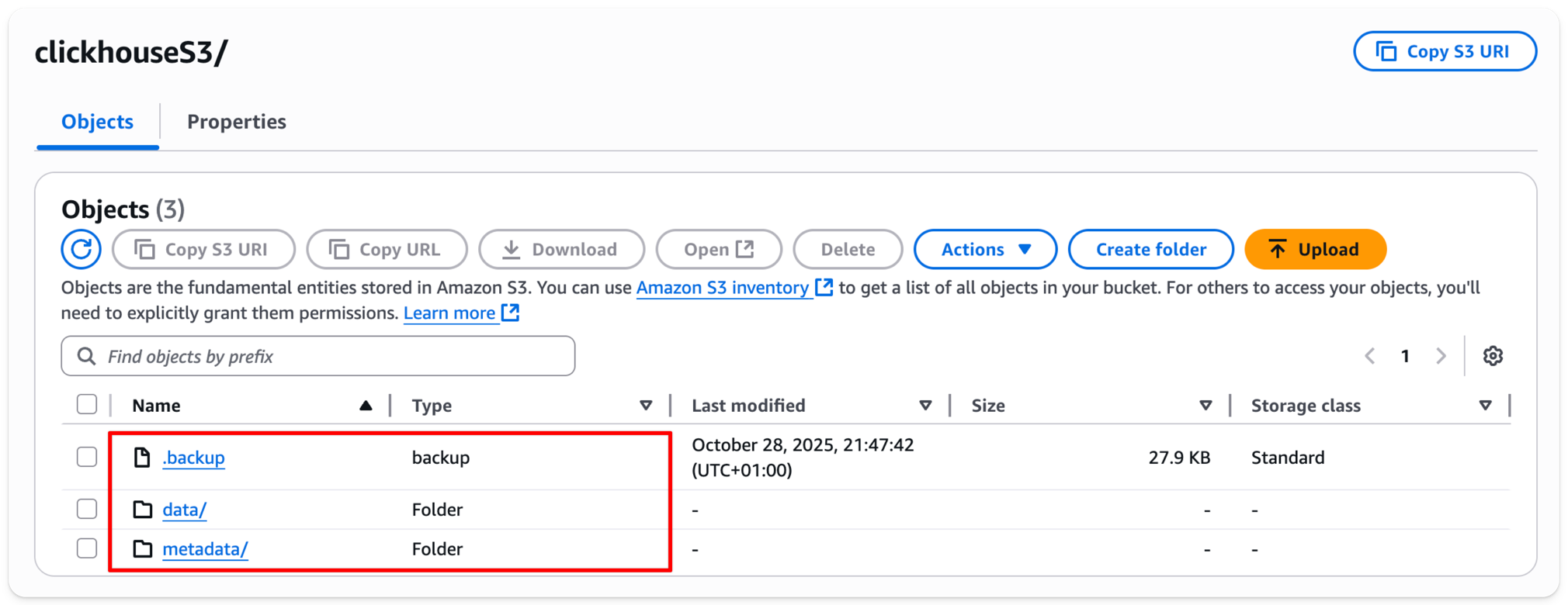
如果你检查之前空的 S3 存储桶,现在会看到其中已经出现了一些文件夹:
如果你正在执行完整迁移,则可以运行以下命令来备份整个服务器:
BACKUP
TABLE system.users,
TABLE system.roles,
TABLE system.settings_profiles,
TABLE system.row_policies,
TABLE system.quotas,
TABLE system.functions,
ALL EXCEPT DATABASES INFORMATION_SCHEMA, information_schema, system
TO S3(
'BUCKET_ID',
'KEY_ID',
'SECRET_ID'
)
SETTINGS
compression_method='lzma',
compression_level=3;
上述命令备份的内容包括:
所有用户数据库和表
用户账户和密码
角色和权限
设置配置文件
行级策略
配额
用户定义函数
如果你使用的是其他云服务提供商 (CSP) ,可以使用 TO S3() (适用于 AWS 和 GCP) 以及 TO AzureBlobStorage() 语法。
对于非常大的数据库,建议使用 ASYNC 在后台执行备份:
BACKUP DATABASE my_database
TO S3('https://your-bucket.s3.amazonaws.com/backup.zip', 'key', 'secret')
ASYNC;
-- Returns immediately with backup ID
-- Example result:
-- ┌─id──────────────────────────────────┬─status────────────┐
-- │ abc123-def456-789 │ CREATING_BACKUP │
-- └─────────────────────────────────────┴───────────────────┘
随后可以使用该备份 ID 来监控备份进度:
SELECT *
FROM system.backups
WHERE id = 'abc123-def456-789'
还可以执行增量备份。
有关备份的一般信息,请参阅备份与恢复 文档。
恢复到 ClickHouse Cloud
将各个分片的备份依次恢复到您的 Cloud 服务中。将 ROLE_ARN 设置为从“安全访问 S3 数据” 获取的值。
在第二次及后续每次恢复时,使用 SETTINGS allow_non_empty_tables=true,
这样会将分片数据追加到已恢复的表中,而不会因冲突而失败:
分片 1:
RESTORE DATABASE nyc_taxi
FROM S3(
'BUCKET_URL/backup_s1.zip',
extra_credentials(role_arn = 'ROLE_ARN')
)
分片 2:
RESTORE DATABASE nyc_taxi
FROM S3(
'BUCKET_URL/backup_s2.zip',
extra_credentials(role_arn = 'ROLE_ARN')
)
SETTINGS allow_non_empty_tables=true;
非分布式部署
如果您未使用分布式表,请使用单条命令恢复数据库:
RESTORE DATABASE nyc_taxi
FROM S3(
'BUCKET_URL',
extra_credentials(role_arn = 'ROLE_ARN')
)
您可以用类似的方式对整个服务执行恢复:
RESTORE
TABLE system.users,
TABLE system.roles,
TABLE system.settings_profiles,
TABLE system.row_policies,
TABLE system.quotas,
ALL EXCEPT DATABASES INFORMATION_SCHEMA, information_schema, system
FROM S3(
'BUCKET_URL',
extra_credentials(role_arn = 'ROLE_ARN')
)
恢复完成后,您可以验证数据是否已在 Cloud 中可用:
-- ClickHouse Cloud restores everything in your local table
SELECT count() from nyc_taxi.trips_small_dist_local;
3000317
由于 ClickHouse Cloud 内部使用 SharedMergeTree,因此旧的分布式表已不再需要。您可以将其删除,并替换为一个视图,以保留查询中使用的原始表名:
DROP TABLE drop table nyc_taxi.trips_small_dist;
CREATE VIEW nyc_taxi.trips_small_dist AS SELECT * FROM nyc_taxi.trips_small_dist_local;
SELECT count() from nyc_taxi.trips_small_dist;
3000317
非分布式 ReplicatedMergeTree 表将恢复为 SharedMergeTree:
SELECT count() FROM nyc_taxi.trips_small_adapted;
3000317