Exploring data with Jupyter notebooks and chDB
In this guide, you will learn how you can explore a dataset on ClickHouse Cloud data in Jupyter notebook with the help of chDB - a fast in-process SQL OLAP Engine powered by ClickHouse.
Prerequisites:
- a virtual environment
- a working ClickHouse Cloud service and your connection details
If you don't yet have a ClickHouse Cloud account, you can sign up for a trial and get $300 in free-credits to begin.
What you'll learn:
- Connect to ClickHouse Cloud from Jupyter notebooks using chDB
- Query remote datasets and convert results to Pandas DataFrames
- Combine cloud data with local CSV files for analysis
- Visualize data using matplotlib
We'll be using the UK Property Price dataset which is available on ClickHouse Cloud as one of the starter datasets. It contains data about the prices that houses were sold for in the United Kingdom from 1995 to 2024.
Setup
To add this dataset to an existing ClickHouse Cloud service, login to console.clickhouse.cloud with your account details.
In the left hand menu, click on Data sources. Then click Predefined sample data:

Select Get started in the UK property price paid data (4GB) card:

Then click Import dataset:

ClickHouse will automatically create the pp_complete table in the default database and fill the table with 28.92 million rows of price point data.
In order to reduce the likelihood of exposing your credentials, we recommend to add your Cloud username and password as environment variables on your local machine. From a terminal run the following command to add your username and password as environment variables:
The environment variables above persist only as long as your terminal session. To set them permanently, add them to your shell configuration file.
Now activate your virtual environment. From within your virtual environment, install Jupyter Notebook with the following command:
launch Jupyter Notebook with the following command:
A new browser window should open with the Jupyter interface on localhost:8888.
Click File > New > Notebook to create a new Notebook.
You will be prompted to select a kernel.
Select any Python kernel available to you, in this example we will select the ipykernel:

In a blank cell, you can type the following command to install chDB which we will be using connect to our remote ClickHouse Cloud instance:
You can now import chDB and run a simple query to check that everything is set up correctly:
Exploring the data
With the UK price paid data set up and chDB up and running in a Jupyter notebook, we can now get started exploring our data.
Let's imagine we're interested in checking how price has changed with time for a specific area in the UK such as the capital city, London.
ClickHouse's remoteSecure function allows you to easily retrieve the data from ClickHouse Cloud.
You can instruct chDB to return this data in process as a Pandas data frame - which is a convenient and familiar way of working with data.
Write the following query to fetch the UK price paid data from your ClickHouse Cloud service and turn it into a pandas.DataFrame:
In the snippet above, chdb.query(query, "DataFrame") runs the specified query and outputs the result to the terminal as a Pandas DataFrame.
In the query we're using the remoteSecure function to connect to ClickHouse Cloud.
The remoteSecure functions takes as parameters:
- a connection string
- the name of the database and table to use
- your username
- your password
As a security best practice, you should prefer using environment variables for the username and password parameters rather than specifying them directly in the function, although this is possible if you wish.
The remoteSecure function connects to the remote ClickHouse Cloud service, runs the query and returns the result.
Depending on the size of your data, this could take a few seconds.
In this case we return an average price point per year, and filter by town='LONDON'.
The result is then stored as a DataFrame in a variable called df.
df.head displays only the first few rows of the returned data:
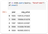
Run the following command in a new cell to check the types of the columns:
Notice that while date is of type Date in ClickHouse, in the resulting data frame it is of type uint16.
chDB automatically infers the most appropriate type when returning the DataFrame.
With the data now available to us in a familiar form, let's explore how prices of property in London have changed with time.
In a new cell, run the following command to build a simple chart of time vs price for London using matplotlib:

Perhaps unsurprisingly, property prices in London have increased substantially over time.
A fellow data scientist has sent us a .csv file with additional housing related variables and is curious how the number of houses sold in London has changed over time. Let's plot some of these against the housing prices and see if we can discover any correlation.
You can use the file table engine to read files directly on your local machine.
In a new cell, run the following command to make a new DataFrame from the local .csv file.
Details
Read from multiple sources in a single step
It's also possible to read from multiple sources in a single step. You could use the query below using aJOIN to do so: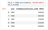
Although we're missing data from 2020 onwards, we can plot the two datasets against each other for the years 1995 to 2019. In a new cell run the following command:

From the plotted data, we see that sales started around 160,000 in the year 1995 and surged quickly, peaking at around 540,000 in 1999. After that, volumes declined sharply through the mid-2000s, dropping severely during the 2007-2008 financial crisis and falling to around 140,000. Prices on the other hand showed steady, consistent growth from about £150,000 in 1995 to around £300,000 by 2005. Growth accelerated significantly after 2012, rising steeply from roughly £400,000 to over £1,000,000 by 2019. Unlike sales volume, prices showed minimal impact from the 2008 crisis and maintained an upward trajectory. Yikes!
Summary
This guide demonstrated how chDB enables seamless data exploration in Jupyter notebooks by connecting ClickHouse Cloud with local data sources.
Using the UK Property Price dataset, we showed how to query remote ClickHouse Cloud data with the remoteSecure() function, read local CSV files with the file() table engine, and convert results directly to Pandas DataFrames for analysis and visualization.
Through chDB, data scientists can leverage ClickHouse's powerful SQL capabilities alongside familiar Python tools like Pandas and matplotlib, making it easy to combine multiple data sources for comprehensive analysis.
While many a London-based data scientist may not be able to afford their own home or apartment any time soon, at least they can analyze the market that priced them out!
