Потоковая передача данных из SQL Server в ClickHouse для быстрой аналитики: пошаговое руководство
В этой статье мы пошагово покажем, как организовать потоковую передачу данных из SQL Server в ClickHouse. ClickHouse идеально подходит, если вам нужна сверхбыстрая аналитика для внутренних отчётных панелей или клиентских панелей мониторинга. Мы по шагам пройдём подготовку обеих баз данных, настройку соединения между ними и, наконец, покажем, как использовать Streamkap для потоковой передачи ваших данных. Если SQL Server обслуживает ваши повседневные операции, а для аналитики вам нужна скорость и мощь ClickHouse, вы обратились по адресу.
Зачем передавать потоковые данные из SQL Server в ClickHouse?
Если вы читаете это, значит, вы, вероятно, уже столкнулись с проблемой: SQL Server отлично подходит для транзакций, но он просто не рассчитан на выполнение тяжёлых аналитических запросов в режиме реального времени.
Здесь и раскрываются сильные стороны ClickHouse. ClickHouse создан для аналитики с сверхбыстрыми агрегациями и построением отчётов даже на очень больших наборах данных. Поэтому, если вы настроите потоковый конвейер CDC, который будет передавать ваши транзакционные данные в ClickHouse, вы сможете выполнять молниеносную отчётность — это идеально для операционной аналитики, продуктовых команд или клиентских дашбордов.
Типичные варианты использования:
- Внутренняя отчётность, которая не замедляет production‑приложения
- Клиентские дашборды, которым важны высокая скорость и актуальность данных
- Потоковая обработка событий, например постоянное обновление логов активности пользователей для аналитики
Что вам понадобится, чтобы начать работу
Прежде чем углубляться в подробности, подготовьте следующее:
Предварительные требования
-
Запущенный экземпляр SQL Server
-
В этом руководстве мы используем AWS RDS для SQL Server, но подойдёт любой современный экземпляр SQL Server. Настройка AWS SQL Server с нуля.
-
Экземпляр ClickHouse
-
Самостоятельно развернутый или облачный. Настройка ClickHouse с нуля.
-
Streamkap
-
Этот инструмент будет основой вашего конвейера потоковой обработки данных.
Информация о подключении
Убедитесь, что у вас есть:
- Адрес сервера SQL Server, порт, имя пользователя и пароль. Рекомендуется создать для Streamkap отдельного пользователя и роль для доступа к вашей базе данных SQL Server. Ознакомьтесь с нашей документацией по конфигурации.
- Адрес сервера ClickHouse, порт, имя пользователя и пароль. Списки доступа по IP в ClickHouse определяют, какие сервисы могут подключаться к вашей базе данных ClickHouse. Следуйте инструкциям здесь.
- Таблицы, из которых вы хотите передавать данные в поток — пока начните с одной
Настройка SQL Server в качестве источника
Давайте приступим!
Шаг 1: Создание источника SQL Server в Streamkap
Начнём с настройки подключения к источнику. Так Streamkap узнаёт, откуда забирать изменения.
Сделайте следующее:
- Откройте Streamkap и перейдите в раздел источников.
- Создайте новый источник.
- Дайте ему понятное имя (например, sqlserver-demo-source).
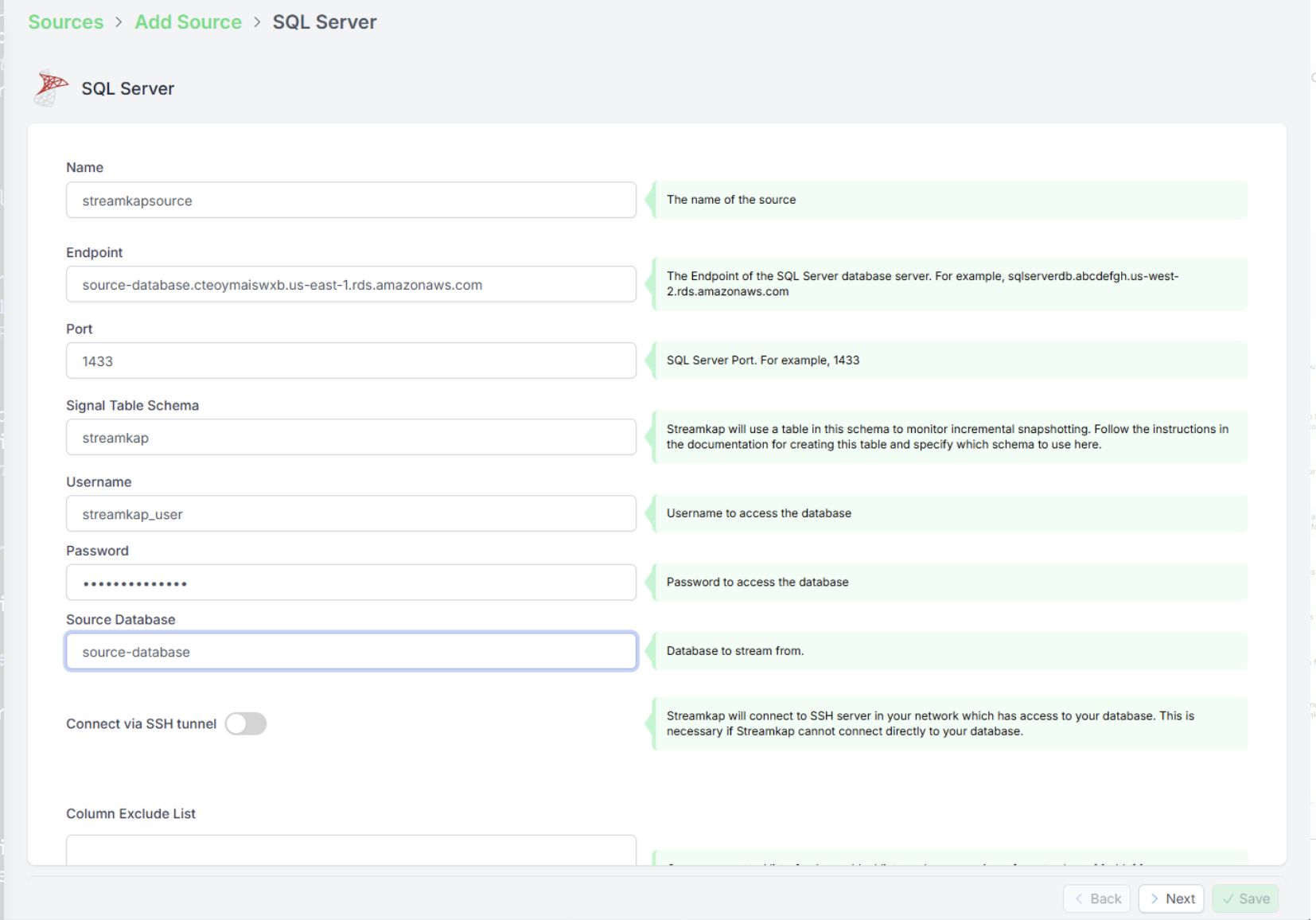
- Заполните параметры подключения к SQL Server:
- Host (например, your-db-instance.rds.amazonaws.com)
- Port (порт по умолчанию для SQL Server — 3306)
- Username и Password
- Database name
Что происходит за кулисами
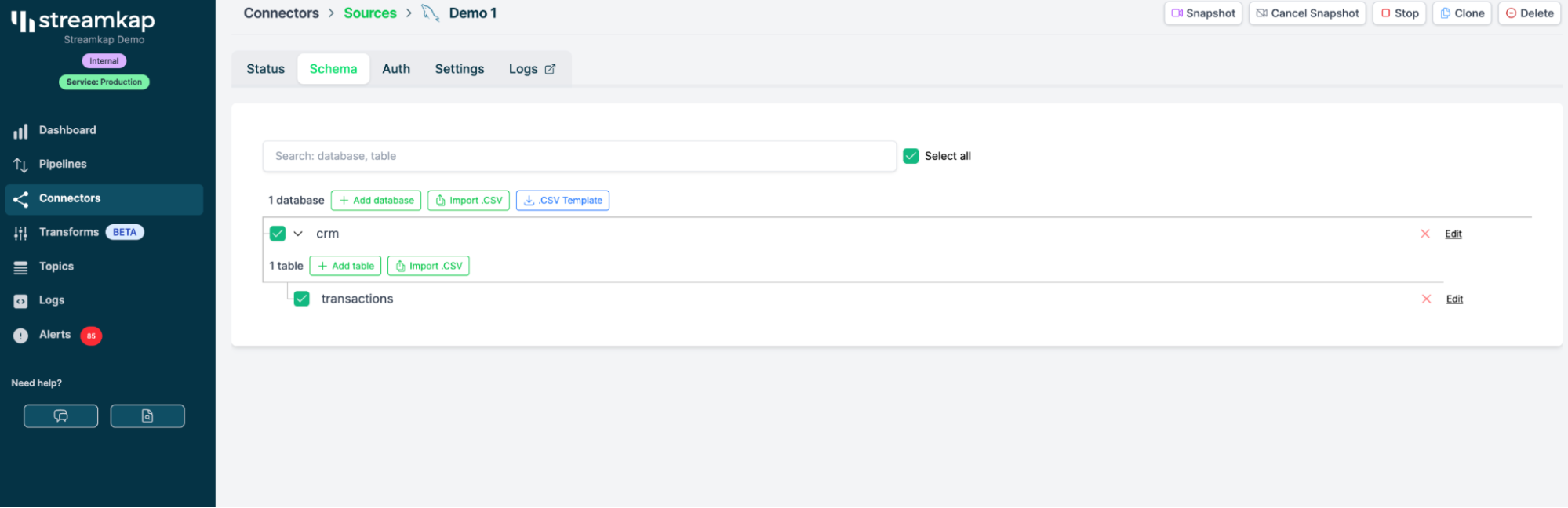
Когда вы всё это настроите, Streamkap подключится к вашему SQL Server и обнаружит таблицы. В этом примере мы выберем таблицу, в которую уже поступают потоковые данные, например события или транзакции.
Создание назначения ClickHouse
Теперь настроим назначение, в которое будем отправлять все эти данные.
Шаг 2. Добавьте назначение ClickHouse в Streamkap
Аналогично источнику данных, создадим назначение, используя наши параметры подключения к ClickHouse.
Шаги:
- Перейдите в раздел Destinations в Streamkap.
- Добавьте новое назначение — выберите ClickHouse в качестве типа назначения.
- Введите данные подключения к ClickHouse:
- Host
- Port (по умолчанию 9000)
- Username и Password
- Имя базы данных
Пример скриншота: добавление нового назначения ClickHouse в панели управления Streamkap.
Режим upsert: что это такое?
Это важный шаг: мы хотим использовать в ClickHouse режим «upsert», который внутренне использует движок ReplacingMergeTree в ClickHouse. Это позволяет эффективно объединять входящие записи и обрабатывать обновления после приёма, используя то, что в ClickHouse называется «слиянием частей данных» (part merging).
- Это гарантирует, что ваша целевая таблица не заполнится дубликатами, когда на стороне SQL Server происходят изменения.
Обработка изменений схемы
У ClickHouse и SQL Server иногда отличаются наборы столбцов — особенно когда приложение уже работает в продакшене, а разработчики продолжают «на лету» добавлять новые столбцы.
- Хорошая новость: Streamkap умеет обрабатывать базовые изменения схемы. Это значит, что если вы добавите новый столбец в SQL Server, он появится и в ClickHouse.
Просто выберите «schema evolution» в настройках назначения. Позже вы всегда сможете при необходимости это изменить.
Создание конвейера потоковой обработки данных
Когда источник и получатель данных настроены, пора перейти к самой интересной части — потоковой передаче данных!
Шаг 3: Настройка конвейера в Streamkap
Настройка конвейера
-
Перейдите на вкладку Pipelines в Streamkap.
-
Создайте новый конвейер.
-
Выберите ваш источник SQL Server (sqlserver-demo-source).
-
Выберите ваш приёмник ClickHouse (clickhouse-tutorial-destination).
-
Выберите таблицу, данные из которой нужно передавать в потоковом режиме — допустим, это events.
-
Настройте фиксацию изменений данных (CDC).
- В этом запуске мы будем передавать только новые данные (на первых порах можно пропустить заполнение исторических данных, backfilling, и сосредоточиться на CDC-событиях).
Скриншот настроек конвейера — выбор источника, приёмника и таблицы.
Нужно ли выполнять бэкфилл?
Вы можете спросить: нужно ли мне догружать старые данные?
Во многих аналитических сценариях можно просто начать транслировать изменения с текущего момента, но при необходимости вы всегда сможете позже загрузить и исторические данные.
Просто выберите вариант «Don’t backfill» на данном этапе, если у вас нет какой‑то конкретной потребности.
Стриминг в действии: чего ожидать
Теперь ваш конвейер данных настроен и работает!
Шаг 4. Наблюдайте за потоком данных
Вот что происходит:
- Когда новые данные попадают в исходную таблицу в SQL Server, конвейер данных Streamkap фиксирует изменения и отправляет их в ClickHouse.
- ClickHouse (благодаря ReplacingMergeTree и слиянию частей) принимает эти строки и объединяет обновления.
- Схема не отстаёт — добавьте столбцы в SQL Server, и они появятся в ClickHouse тоже.
Онлайн‑дашборд или логи показывают, как в реальном времени растёт количество строк в ClickHouse и SQL Server.
Вы буквально видите, как число строк в ClickHouse растёт по мере того, как SQL Server получает данные.
В сценариях с высокой нагрузкой возможна некоторая задержка, но в большинстве случаев данные поступают практически в режиме реального времени.
Под капотом: что на самом деле делает Streamkap?
Чтобы немного прояснить, как это работает:
- Streamkap отслеживает бинарный лог SQL Server (тот же лог, который используется для репликации).
- Как только в вашей таблице вставляется, обновляется или удаляется строка, Streamkap фиксирует это событие.
- Он преобразует событие в формат, понятный ClickHouse, и отправляет его — мгновенно применяя изменения в вашей аналитической базе данных.
Это не просто ETL — это полноценная CDC (фиксация изменений данных) в режиме реального времени.
Дополнительные параметры
Режимы Upsert и Insert
В чём разница между простым добавлением каждой строки (режим Insert) и режимом, в котором обновления и удаления тоже корректно отражаются (режим Upsert)?
- Режим Insert: Каждая новая строка добавляется — даже если это обновление, вы получите дубликаты.
- Режим Upsert: Обновления существующих строк перезаписывают уже имеющиеся данные — значительно лучше для поддержания аналитики актуальной и чистой.
Обработка изменений схемы
Приложения меняются — и схемы тоже. В этом пайплайне:
- Добавили новый столбец в операционную таблицу?
Streamkap автоматически обнаружит его и добавит на стороне ClickHouse. - Убрали столбец?
В зависимости от настроек может понадобиться миграция, но большинство добавлений проходят без проблем.
Мониторинг в реальной эксплуатации: отслеживание состояния конвейера данных
Проверка состояния конвейера
Streamkap предоставляет панель мониторинга, на которой вы можете:
- Смотреть задержку конвейера (насколько свежие ваши данные?)
- Отслеживать количество строк и пропускную способность
- Получать оповещения, если что-то пошло не так
Пример панели мониторинга: график задержки, количество строк, индикаторы состояния.
Основные метрики, за которыми следует наблюдать
- Задержка (Lag): насколько сильно ClickHouse отстает от SQL Server?
- Пропускная способность (Throughput): строк в секунду
- Уровень ошибок (Error Rate): должен быть близок к нулю
Переход к боевой эксплуатации: выполнение запросов в ClickHouse
Теперь, когда ваши данные находятся в ClickHouse, вы можете выполнять по ним запросы с помощью всех доступных инструментов для быстрой аналитики. Ниже приведён простой пример:
Используйте ClickHouse совместно с инструментами для построения дашбордов, такими как Grafana, Superset или Redash, чтобы создать полноценную систему отчетности.
Следующие шаги и углублённое изучение
Этот пошаговый пример лишь слегка приоткрывает ваши возможности. Освоив базу, вы можете изучить следующее:
- Настройку потоков с фильтрацией (синхронизировать только отдельные таблицы/столбцы)
- Потоковую передачу данных из нескольких источников в одну аналитическую БД
- Совместное использование с S3/озёрами данных для холодного хранения
- Автоматизацию миграций схемы при изменении таблиц
- Повышение безопасности конвейера с помощью SSL и правил брандмауэра
Следите за блогом Streamkap для более подробных руководств.
FAQ и устранение неполадок
Q: Работает ли это с облачными базами данных?
A: Да! В этом примере мы использовали AWS RDS. Просто убедитесь, что открыты нужные порты.
Q: Что насчёт производительности?
A: ClickHouse очень быстр. Узким местом обычно является сеть или скорость binlog исходной БД, но в большинстве случаев задержка будет меньше секунды.
Q: Можно ли обрабатывать и операции удаления?
A: Конечно. В режиме upsert операции удаления также помечаются и обрабатываются в ClickHouse.
Подводим итоги
Теперь у вас есть полное представление о том, как стримить данные из SQL Server в ClickHouse с помощью Streamkap. Это быстро, гибко и идеально подходит для команд, которым нужна аналитика почти в реальном времени без излишней нагрузки на продуктивные базы данных.
Готовы попробовать?
Перейдите на страницу регистрации и дайте нам знать, если вы хотите, чтобы мы осветили такие темы, как:
- Upsert vs. Insert и все технические детали каждого подхода
- Сквозная задержка: насколько быстро вы можете получить финальное аналитическое представление данных?
- Оптимизация производительности и пропускная способность
- Реальные дашборды на основе этого стека
Спасибо, что дочитали! Удачного стриминга.
