ClickStack - パフォーマンスチューニング
はじめに
このガイドでは、ClickStack 向けの、最も一般的かつ効果的なパフォーマンス最適化手法に焦点を当てます。これらは、実運用環境における大半のオブザーバビリティワークロードに対して十分な最適化を提供し、通常は 1 日あたり数十テラバイト規模のデータまでを対象とします。
ClickHouse の概念
このガイドで説明する最適化を適用する前に、いくつかの中核となる ClickHouse の概念に慣れておくことが重要です。
ClickStack では、各 データソースは 1 つ以上の ClickHouse テーブルに直接対応 します。OpenTelemetry を使用している場合、ClickStack はログ、トレース、メトリクスデータを保存するための既定テーブル群を作成および管理します。カスタムスキーマを使用している場合や、自分でテーブルを管理している場合は、すでにこれらの概念に慣れている可能性があります。一方、単に OpenTelemetry Collector 経由でデータを送信しているだけであれば、これらのテーブルは自動的に作成され、以下で説明するすべての最適化はこれらのテーブルに対して適用されます。
| Data type | Table |
|---|---|
| Logs | otel_logs |
| Traces | otel_traces |
| Metrics (gauges) | otel_metrics_gauge |
| Metrics (sums) | otel_metrics_sum |
| Metrics (histogram) | otel_metrics_histogram |
| Metrics (Exponential histograms) | otel_metrics_exponentialhistogram |
| Metrics (summary) | otel_metrics_summary |
| Sessions | hyperdx_sessions |
テーブルは ClickHouse 内の データベース に割り当てられます。デフォルトでは default データベースが使用されますが、これは OpenTelemetry Collector 側で変更可能 です。
多くの場合、パフォーマンスチューニングの中心はログおよびトレースのテーブルになります。メトリクステーブルはフィルタリング向けに最適化することもできますが、スキーマは Prometheus スタイルのワークロード向けにあらかじめ意図的に設計されており、標準的なチャート用途では通常変更の必要はありません。これに対してログおよびトレースは、より広範なアクセスパターンをサポートしているため、チューニングによる恩恵が最も大きくなります。セッションデータについてはユーザー体験が固定されており、スキーマを変更する必要が生じることはほとんどありません。
最低限、次の ClickHouse の基本事項を理解しておく必要があります。
| Concept | Description |
|---|---|
| Tables | ClickStack のデータソースが、どのように基盤となる ClickHouse テーブルに対応しているか。ClickHouse のテーブルは主に MergeTree エンジンを使用します。 |
| Parts | データがどのようにイミュータブルなパーツとして書き込まれ、その後時間とともにマージされるか。 |
| Partitions | パーティションは、テーブルのデータパーツを整理された論理単位にまとめます。これらの単位は管理やクエリ、最適化がしやすくなります。 |
| Merges | クエリ対象となるパーツ数を減らすために、パーツ同士をマージする内部プロセス。クエリパフォーマンスを維持するうえで不可欠です。 |
| Granules | ClickHouse がクエリ実行時に読み取りおよびプルーニングを行う最小単位のデータです。 |
| Primary (ordering) keys | ORDER BY キーがディスク上でのデータレイアウト、圧縮、およびクエリのプルーニングをどのように決定するか。 |
これらの概念は ClickHouse のパフォーマンスの中核をなすものです。データがどのように書き込まれるか、ディスク上でどのように構造化されるか、そしてクエリ実行時に ClickHouse がどれだけ効率的にデータ読み取りをスキップできるかが、これらによって決まります。このガイドに登場するすべての最適化、たとえば materialized カラム、スキップ索引、プライマリキー、PROJECTION、materialized view などは、すべてこれらのコアメカニズムの上に成り立っています。
チューニングに着手する前に、次の ClickHouse ドキュメントに目を通しておくことを推奨します。
-
Creating tables in ClickHouse - テーブルの簡潔な入門。
-
How ClickHouse stores data: parts and granules - ClickHouse におけるデータ構造とクエリ方法について、granules やプライマリキーを含めて詳しく解説した上級ガイド。
-
MergeTree- コマンドや内部仕様の理解に役立つ、MergeTree の上級リファレンスガイド。
-
How ClickHouse stores data: parts and granules - ClickHouse でデータがどのように構造化され、クエリされるかを、granule とプライマリキーの詳細を含めて解説する上級ガイド。
-
MergeTree- コマンドおよび内部仕様の理解に有用な、MergeTree の高度なリファレンスガイド。
以下で説明するすべての最適化は、標準的な ClickHouse SQL を使用して、ClickHouse Cloud SQL console または ClickHouse client から元となるテーブルに直接適用できます。
最適化 1. よくクエリされる属性をマテリアライズする
ClickStack ユーザー向けの最初かつ最も簡単な最適化は、LogAttributes、ScopeAttributes、ResourceAttributes 内で頻繁にクエリされる属性を特定し、マテリアライズドカラムを使ってそれらをトップレベルのカラムとして昇格させることです。
この最適化だけで、ClickStack のデプロイメントを 1 日あたり数十テラバイト規模までスケールさせられることも多く、より高度なチューニング手法を検討する前に適用すべきです。
属性をマテリアライズする理由
ClickStack は Kubernetes のラベル、サービスのメタデータ、カスタム属性などのメタデータを Map(String, String) カラムに保存します。これは柔軟ですが、Map のサブキーをクエリする場合に重要なパフォーマンス上の影響があります。
Map カラムから単一のキーをクエリする際、ClickHouse はディスクから Map カラム全体を読み込む必要があります。Map に多くのキーが含まれていると、専用カラムを読む場合と比べて不要な IO が発生し、クエリが遅くなります。
頻繁に参照される属性をマテリアライズすると、挿入時に値を抽出して通常のカラムとして保存することで、このオーバーヘッドを回避できます。
マテリアライズドカラム:
-
挿入時に自動的に計算される
-
INSERT 文で明示的に設定することはできない
-
任意の ClickHouse 式をサポートする
-
String から、より効率的な数値型や日付型への型変換を可能にする
-
スキップ索引とプライマリキーの利用を可能にする
-
Map 全体へのアクセスを回避してディスク読み取りを削減する
ClickStack は Map から抽出されたマテリアライズドカラムを自動的に検出し、ユーザーが元の属性パスでクエリし続ける場合でも、クエリ実行時にそれらを透過的に利用します。
例
Kubernetes のメタデータが ResourceAttributes に保存されている、トレース用のデフォルトの ClickStack スキーマを考えてみましょう。
ユーザーは、たとえば ResourceAttributes.k8s.pod.name:"checkout-675775c4cc-f2p9c" のような Lucene 構文を使用してトレースを絞り込むことができます。
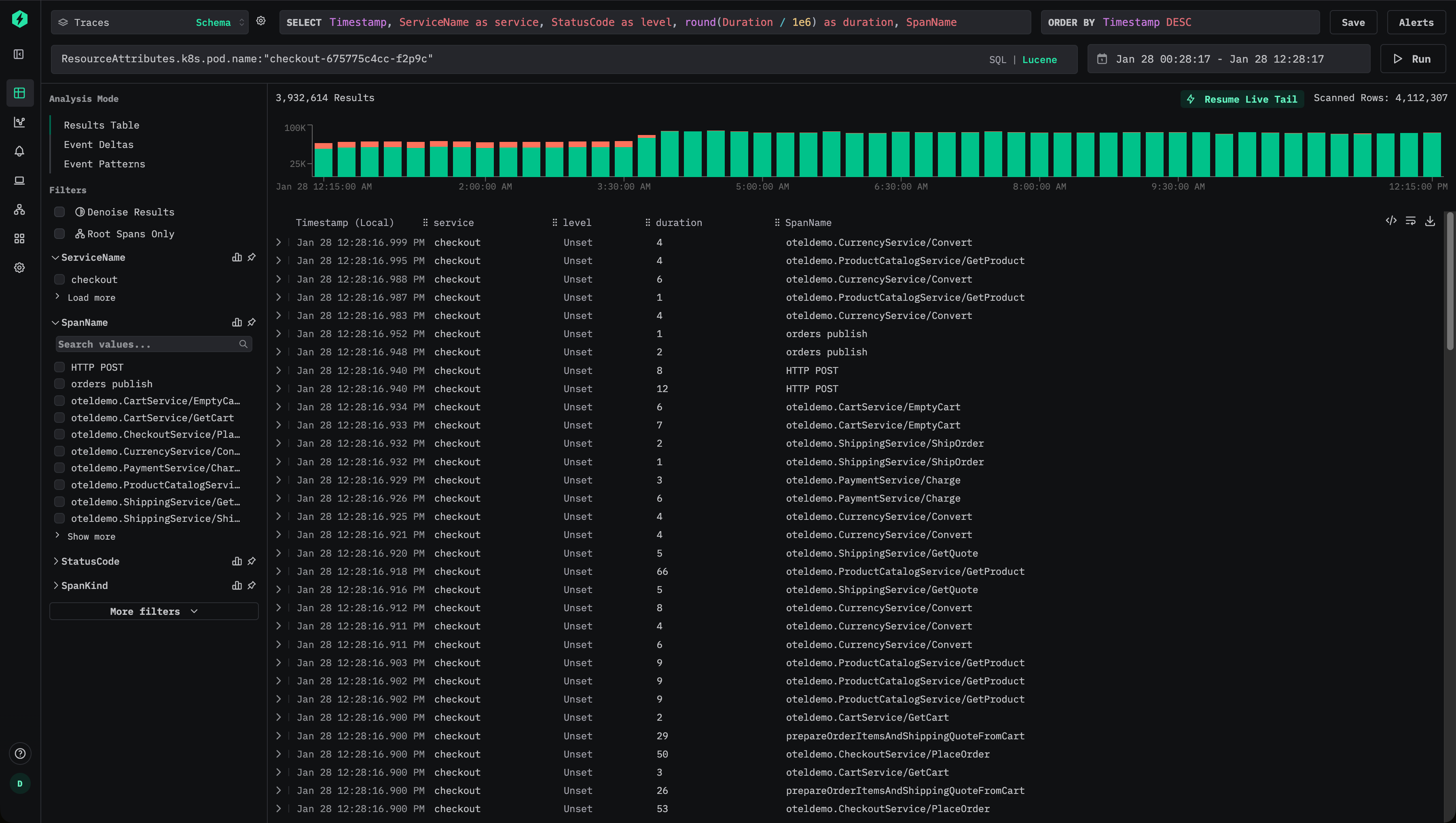
これにより、次のような SQL の述語が生成されます。
これは Map のキーにアクセスするため、ClickHouse は一致する各行に対して ResourceAttributes カラム全体を読み出す必要があります。Map に多くのキーが含まれている場合、データ量が非常に大きくなる可能性があります。
この属性が頻繁にクエリされる場合は、トップレベルのカラムとしてマテリアライズしておくべきです。
挿入時にポッド名を抽出するには、マテリアライズドカラムを追加します。
この時点以降、新規に挿入されるデータでは、ポッド名が専用のカラム PodName に保存されます。
ユーザーは Lucene 構文を使って、PodName:"checkout-675775c4cc-f2p9c" のようにポッド名を効率的にクエリできます。
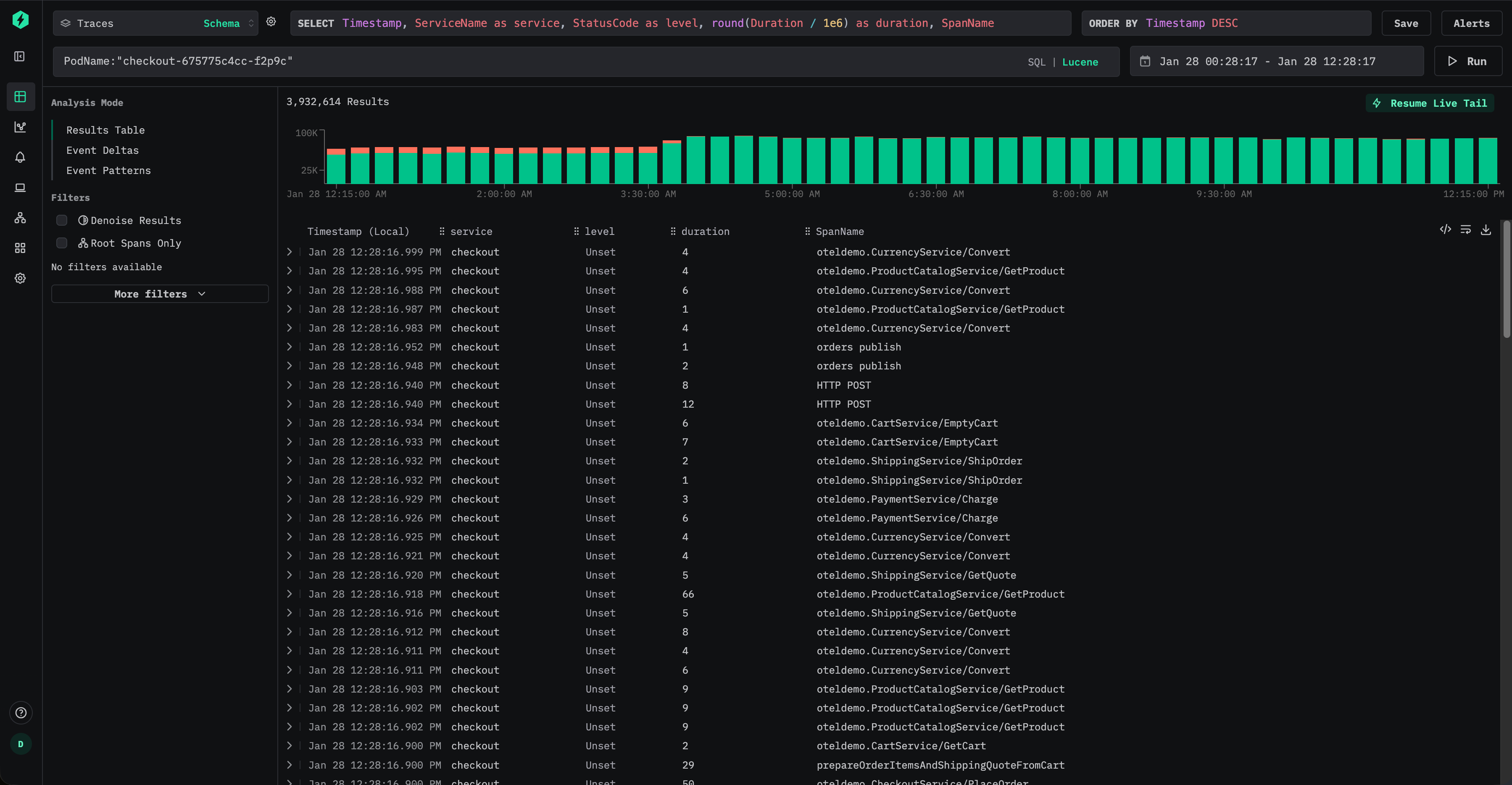
新たに挿入されるデータについては、これによりマップへのアクセスを完全に回避でき、I/O を大幅に削減できます。
ただし、ユーザーが元の属性パス(例: ResourceAttributes.k8s.pod.name:"checkout-675775c4cc-f2p9c")でクエリを発行し続けたとしても、ClickStack は内部的にクエリを書き換えて、マテリアライズされた PodName カラムを使用します。つまり、次の述語を用いる形になります:
これにより、ダッシュボード、アラート、保存済みクエリを変更することなく、ユーザーは最適化の恩恵を受けられます。
デフォルトでは、マテリアライズドカラムは SELECT * クエリから除外されます。これにより、クエリ結果を常にテーブルに再挿入できるという性質が保たれます。
履歴データのマテリアライズ
マテリアライズドカラムは、そのカラムが作成された後に挿入されたデータにのみ自動的に適用されます。既存のデータに対しては、マテリアライズドカラムへのクエリは透過的に元のマップの読み取りへフォールバックします。
履歴データに対するパフォーマンスが重要な場合は、次のように mutation を使用してカラムをバックフィルできます。
これは既存のパーツを書き換えてカラムを埋めます。ミューテーションはパーツごとにシングルスレッドで実行されるため、大規模なデータセットでは時間がかかる可能性があります。影響を抑えるために、ミューテーションの対象を特定のパーティションに限定できます。
ミューテーションの進行状況は、たとえば system.mutations テーブルを使用して監視できます。
対応するミューテーションについて is_done = 1 になるまで待ちます。
ミューテーションは追加の I/O および CPU オーバーヘッドを発生させるため、必要最小限に留めるべきです。多くの場合、古いデータは自然に削除されるに任せ、新たに取り込まれるデータに対するパフォーマンス改善だけで十分です。
最適化 2. スキップインデックスの追加
頻繁にクエリされる属性をマテリアライズしたら、次の最適化としてデータスキッピングインデックスを追加し、クエリ実行中に ClickHouse が読み取る必要のあるデータ量をさらに削減します。
スキップインデックスを使用すると、一致する値が存在しないと判断できる場合に、ClickHouse はデータブロック全体のスキャンを回避できます。従来のセカンダリ索引と異なり、スキップインデックスはグラニュール単位で動作し、クエリのフィルター条件によってデータセットの大部分が除外される場合に最も効果的です。適切に使用すれば、クエリの意味論を変えることなく、高カーディナリティな属性に対するフィルタリングを大幅に高速化できます。
スキップインデックスを含む ClickStack のデフォルトのトレーススキーマを次に示します。
これらの索引は、次の 2 つの一般的なパターンに焦点を当てています。
- TraceId、セッション識別子、属性キーや値などの、高カーディナリティな文字列に対するフィルタリング
- スパンの継続時間などの数値範囲に対するフィルタリング
ブルームフィルター
ブルームフィルター索引は、ClickStack で最も一般的に使用されるスキップ索引の種類です。これは高カーディナリティ(通常は少なくとも数万件程度の異なる値)を持つ文字列カラムに適しています。偽陽性率 0.01、粒度 1 は、ストレージのオーバーヘッドと効果的なプルーニングとのバランスが取れた、良いデフォルトの出発点です。
Optimization 1 の例を引き続き用いて、Kubernetes のポッド名が ResourceAttributes からマテリアライズされていると仮定します:
その後、Bloom filter を用いたスキップ索引を追加して、このカラムに対するフィルタ処理を高速化できます。
追加したら、skip index はマテリアライズする必要があります。詳細は "Materialize skip index." を参照してください。
作成してマテリアライズすると、ClickHouse は、要求されたポッド名を含まないことが保証されているグラニュール全体をスキップできるようになり、PodName:"checkout-675775c4cc-f2p9c" のようなクエリで読み取るデータ量を削減できる可能性があります。
Bloom filter は、ある値が相対的に少数のパーツにしか出現しないような値の分布で最も効果的です。これは、多くの場合、オブザーバビリティのワークロードでは自然に発生します。このようなワークロードでは、ポッド名、トレース ID、セッション識別子といったメタデータが時間と相関付けられており、その結果、テーブルの ORDER BY キーによってクラスタ化されることが多いためです。
すべての skip index と同様に、Bloom filter も選択的に追加し、実際のクエリパターンに対して検証して、測定可能なメリットを提供していることを確認する必要があります。詳細は "Evaluating skip index effectiveness." を参照してください。
Min-max 索引
Minmax 索引は、各 granule ごとに最小値と最大値を保存する、非常に軽量な索引です。特に数値カラムおよび範囲クエリに対して高い効果を発揮します。すべてのクエリが高速化されるとは限りませんが、コストが低く、数値フィールドにはほぼ常に追加する価値があります。
Minmax 索引は、数値が自然な順序で並んでいる場合や、各 part 内で狭い範囲に収まっている場合に最も効果的です。
SpanAttributes の Kafka オフセットを頻繁にクエリするとします。
この値はマテリアライズして数値型にキャストできます。
次に、minmax 索引を追加します:
これにより、ClickHouse は、たとえばコンシューマーラグやリプレイ動作のデバッグ時に、Kafka のオフセット範囲でフィルタリングする際、パーツを効率的にスキップできるようになります。
あらためてになりますが、索引が利用可能になる前にマテリアライズされている必要があります。
スキップ索引をマテリアライズする
スキップ索引を追加すると、その効果が適用されるのは新たに取り込まれたデータに対してのみです。明示的にマテリアライズするまで、過去のデータはその索引の効果を受けません。
すでにスキップ索引を追加している場合、たとえば次のように追加している場合は:
既存データに対しては、索引を明示的に作成する必要があります。
スキップ索引をマテリアライズする処理は、特に minmax 索引の場合、通常は軽量であり、安全に実行できます。大規模なデータセットに対する Bloom filter 索引については、リソース使用量をより適切に制御するために、パーティション単位でマテリアライズすることを選択する場合があります。
スキップ索引のマテリアライズは mutation として実行されます。その進行状況は system テーブルで監視できます。
対応する mutation が is_done = 1 になるまで待ちます。
完了したら、索引データが作成されたことを確認します。
ゼロ以外の値は、索引が正常にマテリアライズされていることを示します。
スキップ索引のサイズはクエリ性能に直接影響することを理解しておくことが重要です。数十〜数百 GB オーダーの非常に大きなスキップ索引は、クエリ実行中の評価に時間を要し、その利点を減少させたり、場合によっては相殺してしまうことがあります。
実際には、minmax 索引は通常非常に小さく評価コストも低いため、ほぼ常に安全にマテリアライズできます。一方で Bloom filter 索引は、カーディナリティ、granularity、偽陽性率によって大きく増加する可能性があります。
Bloom filter のサイズは、許容される偽陽性率を高くすることで削減できます。例えば、0.01 から 0.05 へと probability パラメータを増加させると、絞り込みの厳しさを犠牲にする代わりに、より小さく評価が速い索引が生成されます。スキップされる granule の数は少なくなるかもしれませんが、索引評価が高速になることで、クエリ全体のレイテンシが改善される場合があります。
したがって、Bloom filter のパラメータ調整はワークロード依存の最適化であり、実際のクエリパターンと本番相当のデータボリュームを用いて検証する必要があります。
スキップ索引の詳細については、ガイド「Understanding ClickHouse data skipping indexes.」を参照してください。
Skip index の有効性を評価する
Skip index のプルーニング効果を評価する最も確実な方法は EXPLAIN indexes = 1 を使うことです。これにより、クエリプランニングの各段階で、何個のパーツとgranuleが除外されたかを確認できます。多くの場合、Skip ステージで granule が大きく削減されていることが望ましく、理想的にはプライマリキーによって検索空間がすでに縮小された後に起こるのがベストです。Skip index はパーティション pruning とプライマリキープルーニングの後に評価されるため、その効果は、残っているパーツと granule に対する相対的な削減として測定するのが最適です。
EXPLAIN によってプルーニングが発生しているかどうかは確認できますが、それだけでトータルとしての高速化が保証されるわけではありません。特に index が大きい場合、Skip index の評価にはコストがかかります。実際のパフォーマンス向上を確認するために、索引を追加してマテリアライズする前後で必ずクエリをベンチマークしてください。
たとえば、デフォルトの Traces スキーマに含まれる TraceId 用のデフォルト Bloom filter skip index を考えてみます。
EXPLAIN indexes = 1 を使用すると、選択性の高いクエリに対してどの程度効果的かを確認できます。
このケースでは、まず主キーのフィルタによってデータセットが大幅に削減され(35,898 個の granule から 255 個へ)、その後 Bloom フィルタがさらにそれを 1 個の granule(1/255)まで絞り込みます。これは skip index の理想的なパターンであり、主キーによる絞り込みで検索範囲を狭め、その後 skip index が残りの大部分を除外します。
実際の効果を検証するには、安定した設定でクエリをベンチマークし、実行時間を比較します。結果のシリアライズによるオーバーヘッドを避けるために FORMAT Null を使用し、実行の再現性を確保するためにクエリ条件キャッシュを無効にします。
次に、スキップインデックスを無効にして同じクエリを実行します:
use_query_condition_cache を無効化すると、キャッシュされたフィルタリング判定によって結果が影響を受けなくなり、use_skip_indexes = 0 を設定することで比較用のクリーンなベースラインが得られます。プルーニングが有効で、索引評価コストが低い場合は、上記の例のように、索引付きクエリの方が体感できるほど高速になるはずです。
EXPLAIN の出力で granule のプルーニングがほとんど行われていない場合や、skip index が非常に大きい場合は、索引の評価コストが利点を相殺してしまうことがあります。EXPLAIN indexes = 1 を使用してプルーニングを確認し、その後ベンチマークを実施してエンドツーエンドのパフォーマンス改善を検証してください。
スキップ索引を追加するタイミング
スキップ索引は、ユーザーが最も頻繁に実行するフィルタの種類と、パーツおよびグラニュール内のデータの分布や特性に基づいて、選択的に追加する必要があります。目的は、索引自体を評価するコストを相殺できるだけのグラニュールを十分に間引くことです。そのため、本番相当のデータでベンチマークを行うことが不可欠です。
フィルタに使用される数値カラムには、minmax スキップ索引がほぼ常に有力な選択肢です。 軽量で評価コストが低く、範囲述語に対して効果的になり得ます。特に、値がゆるく順序付けられている場合や、パーツ内で狭い範囲に収まっている場合です。特定のクエリパターンに対して minmax が効果を発揮しない場合でも、そのオーバーヘッドは通常十分に小さいため、そのまま保持しておいても問題ない場合がほとんどです。
文字列カラム。カーディナリティが高く値がスパースな場合は Bloom フィルタを使用します。
Bloom フィルタは、高カーディナリティな文字列カラムで各値の出現頻度が比較的低い、つまりほとんどのパーツおよびグラニュールに検索対象の値が含まれていないようなケースで最も効果的です。経験則として、カラムに 10,000 個以上の異なる値が存在する場合に Bloom フィルタは有望となり、100,000 個以上の異なる値がある場合に最高の性能を発揮することが多いです。また、一致する値が少数の連続したパーツに集中している場合、すなわちカラムが並び替えキーと相関しているときに、より効果的になります。とはいえ、結果は環境によって異なり得るため、実運用に近い条件でのテストに勝るものはありません。
Optimization 3. Modifying the primary key
ほとんどのワークロードにおいて、プライマリキーは ClickHouse のパフォーマンスチューニングにおける最も重要な構成要素の 1 つです。これを効果的にチューニングするには、その動作とクエリパターンとの相互作用を理解する必要があります。最終的には、プライマリキーはユーザーがデータへアクセスする方法、特にどのカラムで最も頻繁にフィルタリングされるかに揃えるべきです。
プライマリキーは圧縮やストレージレイアウトにも影響しますが、その主な目的はクエリ性能です。ClickStack では、標準で提供されるプライマリキーは、最も一般的なオブザーバビリティのアクセスパターンと高い圧縮効率の両方に対して、すでに最適化されています。ログ、トレース、メトリクステーブルのデフォルトキーは、代表的なワークフローで高い性能を発揮するよう設計されています。
プライマリキーの先頭のほうにあるカラムでフィルタリングするほうが、後ろのカラムでフィルタリングするよりも効率的です。デフォルト構成はほとんどのユーザーにとって十分ですが、特定のワークロードに対しては、プライマリキーを変更することでパフォーマンスが向上する場合があります。
本ドキュメント全体を通して、用語「ordering key」は「primary key」と同じ意味で使われています。厳密には、ClickHouse において両者は異なる概念ですが、ClickStack の場合、通常はテーブルの ORDER BY 句に指定された同じカラム群を指します。詳細については、ソートキーと異なるプライマリキーを選択する方法についての ClickHouse ドキュメント を参照してください。
プライマリキーを変更する前に、ClickHouse におけるプライマリ索引の仕組みを理解するガイドに目を通すことを強く推奨します。
プライマリキーのチューニングは、テーブルおよびデータ種別ごとに固有です。あるテーブルやデータ種別に有効な変更が、他には当てはまらない場合があります。目標は常に、特定のデータ種別(例: ログ)に対して最適化することです。
一般的には、ログおよびトレースのテーブルを最適化することになります。その他のデータ種別について、プライマリキーを変更する必要があるケースはまれです。
以下に、ClickStack におけるログおよびメトリクステーブルのデフォルトのプライマリキーを示します。
- Logs (
otel_logs) -(ServiceName, TimestampTime, Timestamp) - Traces ('otel_traces) -
(ServiceName, SpanName, toDateTime(Timestamp))
他のデータ種別のテーブルで使用されるプライマリキーについては、"Tables and schemas used by ClickStack" を参照してください。たとえば、トレーステーブルは、サービス名とスパン名、その後にタイムスタンプおよびトレース ID でフィルタリングする用途に最適化されています。対照的に、ログテーブルはサービス名、次に日付、次にタイムスタンプによるフィルタリングに最適化されています。理想的には、ユーザーがプライマリキーの順序に従ってフィルタを適用することが望ましいですが、これらのカラムのいずれかで任意の順序でフィルタリングした場合でも、ClickHouse が読み取り前にデータをスキップ(プルーニング)するため、クエリは大きな恩恵を受けます。
プライマリキーを選択する際には、カラムの並び順を最適化するために考慮すべき他の点もあります。"Choosing a primary key." を参照してください。
プライマリキーの変更はテーブルごとに個別に行う必要があります。ログで意味のあることが、トレースやメトリクスでも意味があるとは限りません。
プライマリキーの選択
まず、特定のテーブルについて、アクセスパターンがデフォルト設定と大きく異なっているかどうかを確認します。たとえば、Kubernetes ノードでフィルタしてからサービス名でフィルタする、という形でログを参照することが最も一般的であり、これが主要なワークフローである場合は、プライマリキーを変更する十分な理由になりえます。
デフォルトのプライマリキーは、多くのケースで十分です。変更は慎重に行い、クエリパターンを明確に理解している場合にのみ実施してください。プライマリキーを変更すると、他のワークフローにおけるパフォーマンスが低下する可能性があるため、テストは不可欠です。
必要なカラムを洗い出せたら、ORDER BY/プライマリキーの最適化を開始できます。
ORDER BY キーを選択する際には、いくつかの簡潔なルールを適用できます。以下のルール同士が競合することもあるため、記載順に検討してください。このプロセスから選択するキーは最大 4~5 個を目安とします。
よく使うフィルタやアクセスパターンに合致するカラムを選択します。典型的に、特定のカラム(例: ポッド名)でフィルタしてからオブザーバビリティの調査を開始する場合、そのカラムは WHERE 句で頻繁に使用されます。このようなカラムを、使用頻度の低いカラムよりも優先してキーに含めてください。
フィルタ時に総行数の大部分を除外できるカラムを優先します。これにより、読み取る必要のあるデータ量を削減できます。サービス名やステータスコードは、多くの場合で良い候補になります。ただし後者については、ほとんどの行を除外できる値でフィルタする場合に限ります。たとえば、多くのシステムでは 200 コードでフィルタすると大半の行に一致しますが、500 エラーは行全体のごく一部にしか対応しません。
テーブル内の他のカラムと高い相関が見込まれるカラムを優先します。これにより、これらの値が連続して格納されやすくなり、圧縮効率が向上します。
ORDER BY キーに含まれるカラムに対する GROUP BY(チャート向けの集約)や ORDER BY(ソート)の処理は、よりメモリ効率良く実行できます。
ORDER BY キーとして選択したカラムの部分集合が決まったら、それらを特定の順序で定義する必要があります。この順序は、クエリでキーの後続カラムを対象とするフィルタリング効率と、テーブルのデータファイルにおける圧縮率の両方に大きく影響します。一般的には、カーディナリティが低いものから高いものへと昇順に並べるのが最適です。ただし、ORDER BY キーのタプル内で後ろに位置するカラムに対するフィルタは、前に位置するカラムに対するフィルタよりも非効率になることとのバランスを取る必要があります。これらの挙動を考慮しつつ、アクセスパターンを踏まえて判断してください。何よりも、いくつかのバリエーションをテストすることが重要です。ORDER BY キーの理解と最適化方法について、さらに詳細な解説が必要な場合は、"Choosing a Primary Key." を参照してください。プライマリキーのチューニングおよび内部データ構造について、より深い洞察が必要な場合は、"A practical introduction to primary indexes in ClickHouse." を参照することを推奨します。
プライマリキーの変更
データの取り込み前にアクセスパターンが明確であれば、対象のデータ型についてテーブルを削除して再作成するだけでかまいません。
以下の例は、既存のスキーマはそのままに、新しいプライマリキーとして ServiceName の前に SeverityText を含めたログテーブルを作成する簡単な方法を示しています。
新しいテーブルを作成する
上記の例では、PRIMARY KEY と ORDER BY を指定する必要があります。
ClickStack では、これらはほとんど常に同一です。
ORDER BY は物理的なデータレイアウトを制御し、PRIMARY KEY はスパースな索引を定義します。
まれな大規模ワークロードでは両者が異なる場合もありますが、ほとんどのユーザーは両者を揃えておくべきです。
ただし、既存テーブルのプライマリキーは変更できません。変更するには新しいテーブルを作成する必要があります。
以下の手順により、古いデータを保持しつつ透過的にクエリできるようにできます(必要に応じて HyperDX では既存のキーを引き続き使用しつつ、新しいデータはユーザーのアクセスパターンに最適化された新しいテーブル経由で公開します)。この方法により、インジェストパイプラインを変更する必要はなく、データは引き続きデフォルトのテーブル名に送信され、すべての変更はユーザーからは透過的です。
既存データを新しいテーブルにバックフィルすることは、大規模環境では有益であることはまれです。コンピュートおよび IO コストが高くつくことが多く、そのパフォーマンス上の利点に見合いません。代わりに、古いデータは 有効期限 (TTL) によって期限切れになるようにし、新しいデータのみが改善されたキーの恩恵を受けるようにします。
Merge テーブルを作成する
Merge エンジン(MergeTree と混同しないでください)は自分自身ではデータを保持せず、複数のテーブルから同時に読み取ることを可能にします。
currentDatabase() は、コマンドが正しいデータベース上で実行されることを前提としています。そうでない場合は、データベース名を明示的に指定してください。
このテーブルをクエリすることで、otel_logs からデータが返されることを確認できます。
HyperDX を更新して Merge テーブルから読み取る
HyperDX を構成し、ログのデータソース用テーブルとして otel_logs_merge を使用するようにします。
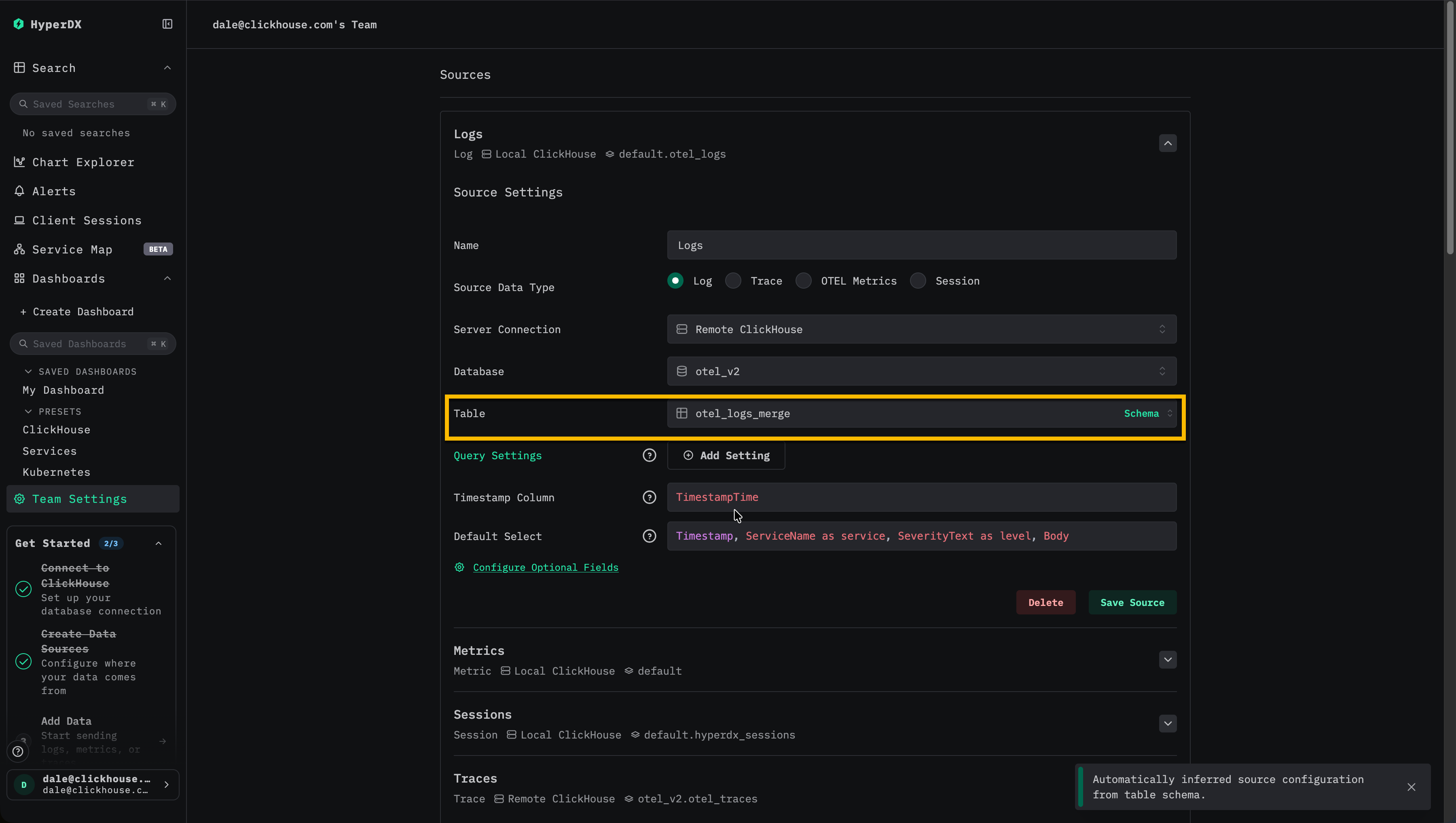
この時点では、書き込みは引き続き元のプライマリキーを持つ otel_logs に対して行われ、読み取りは Merge テーブルを経由します。ユーザーから見える変更はなく、インジェストへの影響もありません。
テーブルを入れ替える
ここで、EXCHANGE ステートメントを使用して、otel_logs と otel_logs_23_01_2025 テーブルの名前をアトミックに入れ替えます。
これ以降、書き込みは更新されたプライマリキーを持つ新しい otel_logs テーブルに送られます。既存データは otel_logs_23_01_2025 に残り、Merge テーブル経由で引き続きアクセス可能です。このサフィックスは変更を適用した日付を表し、そのテーブルに含まれる最新のタイムスタンプを示します。
このプロセスにより、インジェストを中断することなく、かつユーザーから見て影響がない形でプライマリキーを変更できます。
このプロセスは、プライマリキーに対してさらに変更が必要になった場合にも再利用できます。たとえば、1週間後に、SeverityText ではなく SeverityNumber をプライマリキーの一部にすることにした場合などです。以下のプロセスは、プライマリキーの変更が必要になるたびに、何度でも繰り返し適用できます。
テーブルを入れ替える
EXCHANGE ステートメントを使用して、otel_logs テーブルと otel_logs_30_01_2025 テーブルの名前をアトミックに入れ替えます。
これ以降の書き込みは、更新されたプライマリキーを持つ新しい otel_logs テーブルに対して行われます。古いデータは otel_logs_30_01_2025 に残り、マージテーブル経由で引き続きアクセスできます。
有効期限 (TTL) ポリシーが設定されている場合 (推奨)、もはや書き込みを受け取らない、古いプライマリキーを持つテーブルは、データの有効期限が切れるにつれて徐々に空になっていきます。これらのテーブルを監視し、データが含まれなくなった時点で定期的にクリーンアップする必要があります。現時点では、このクリーンアッププロセスは手動で行います。
Optimization 4. materialized view の活用
ClickStack は、集約処理が重いクエリ(例: 時系列での 1 分あたりの平均リクエスト時間の算出など)に依存する可視化を高速化するために、Incremental Materialized Views を活用できます。この機能によりクエリパフォーマンスを大幅に向上でき、1 日あたり約 10 TB 以上の大規模なデプロイメントで特に効果を発揮しつつ、1 日あたり PB レベルまでのスケーリングを可能にします。Incremental Materialized Views はベータ機能であり、慎重に使用する必要があります。
ClickStack でこの機能を使用する方法の詳細については、専用ガイド "ClickStack - Materialized Views." を参照してください。
Optimization 5. Exploiting Projections
PROJECTION は、materialized columns、skip indexes、primary keys、および materialized views を検討し終えた後に考慮できる、最終段階かつ高度な最適化手法です。PROJECTION と materialized view は見かけ上は似ていますが、ClickStack においては異なる目的を持ち、異なるシナリオで使うのが最適です。
プロジェクションの例
traces テーブルがデフォルトの ClickStack のアクセスパターンに合わせて最適化されているとします。
TraceId でフィルタリングすることが多い主要なワークフロー(あるいは TraceId を軸に頻繁にグルーピングやフィルタリングを行うワークフロー)がある場合は、TraceId と時刻でソートされた行を格納する PROJECTION を追加できます。
上記のプロジェクションの例では、ワイルドカード(SELECT *)が使用されています。カラムの一部だけを選択すると書き込み時のオーバーヘッドを減らすことはできますが、そのカラムだけでクエリを完全に満たせる場合にしかプロジェクションを利用できないため、利用可能な場面が制限されます。ClickStack では、この制約によりプロジェクションの利用がごく限られたケースにとどまってしまうことがよくあります。このため、一般的には適用可能性を最大化するためにワイルドカードを使用することを推奨します。
他のデータレイアウトの変更と同様に、プロジェクションは新しく書き込まれたパーツにのみ影響します。既存データに対しても構築するには、マテリアライズします。
projection のマテリアライズには長時間を要し、多くのリソースを消費する可能性があります。オブザーバビリティデータには通常 有効期限 (TTL) が設定されているため、これは本当に必要な場合にのみ実施すべきです。ほとんどのケースでは、新たに取り込むデータに対してのみ projection を適用し、直近24時間など、最も頻繁にクエリされる時間範囲を最適化させるだけで十分です。
ClickHouse は、projection のほうがベースレイアウトよりも少ない granule を走査すると推定した場合、自動的にその projection を選択することがあります。projection は、完全な行セット(SELECT *)の単純な並べ替えを表しており、かつクエリフィルタが projection の ORDER BY と強く整合している場合に最も信頼性が高くなります。
TraceId でフィルタ(特に等価条件)し、かつ時間範囲を含むクエリは、上記の projection の恩恵を受けます。例えば次のようになります。
TraceId を制約しないクエリや、projection の並び替えキーの先頭ではない別のディメンションを主にフィルタ条件とするクエリは、通常は恩恵を受けません(代わりにベースレイアウト経由で読み込まれる可能性があります)。
projection には、集計結果を格納することもできます(materialized view に近いイメージです)。しかし ClickStack では、どのレイアウトが選択されるかが ClickHouse のアナライザに依存し、利用状況の制御や挙動の把握が難しくなるため、projection ベースの集計は一般的には推奨されません。代わりに、ClickStack がアプリケーション層で明示的に登録・選択できる materialized view を利用することを推奨します。
実務上、projection は、広い検索結果からトレース中心のドリルダウンに頻繁にピボットするようなワークフロー(たとえば、特定の TraceId に属するすべての span を取得する処理)に最も適しています。
ORDER BY Timestamp;
-- Trace-scoped aggregation SELECT toStartOfMinute(Timestamp) AS t, count() AS spans FROM otel_traces WHERE TraceId = 'aeea7f401feb75fc5af8eb25ebc8e974' AND Timestamp >= now() - INTERVAL 1 DAY GROUP BY t
_part_offset を用いた軽量 projection
_part_offset ベースの軽量 projection は、ClickStack のワークロードには推奨されません。ストレージと書き込み I/O を削減できる一方で、クエリ実行時のランダムアクセスを増加させる可能性があり、オブザーバビリティ規模での本番環境での挙動については、まだ評価中です。この推奨事項は、機能の成熟と運用データの蓄積に伴い、将来的に変更される可能性があります。
新しい ClickHouse のバージョンでは、projection のソートキーと、ベーステーブルへの _part_offset ポインタだけを保持し、完全な行を複製しない、より軽量な projection もサポートされています。これによりストレージのオーバーヘッドを大幅に削減でき、最近の改善により granule レベルでのプルーニングが可能になったことで、実質的なセカンダリ索引に近い挙動をするようになっています。詳細は次を参照してください。
コストと指針
- 挿入時のオーバーヘッド: 異なる並び替えキーを持つ
SELECT *の projection は、実質的にデータを 2 回書き込むことになり、書き込み I/O が増加し、インジェストを維持するために追加の CPU およびディスクスループットが必要になる場合があります。 - 慎重に利用する: projection は、2 つ目の物理的な並び順によって多くのクエリに対して有意なプルーニングが可能になるような、実際に多様なアクセスパターンが存在する場合に限定して利用するのが最適です。例えば、2 つのチームが同じデータセットに対して本質的に異なる方法でクエリを実行するようなケースです。
- ベンチマークで検証する: すべてのチューニングと同様に、projection を追加してマテリアライズする前後で、実際のクエリレイテンシーとリソース使用量を比較してください。
