プライマリインデックス
このページでは、ClickHouse のスパースプライマリインデックスについて、その構築方法、動作、およびクエリの実行をどのように高速化するかを説明します。
さらに高度なインデックス戦略や、より踏み込んだ技術的な詳細については、プライマリインデックスの詳細解説を参照してください。
ClickHouse におけるスパースプライマリインデックスの仕組み
ClickHouse のスパースプライマリインデックスは、テーブルの主キー列に対するクエリ条件に一致するデータを含んでいる可能性がある granules(行ブロック)を効率的に特定するのに役立ちます。次のセクションでは、このインデックスがそれらの列の値からどのように構築されるかを説明します。
疎なプライマリインデックスの作成
疎なプライマリインデックスがどのように構築されるかを説明するために、uk_price_paid_simple テーブルといくつかのアニメーションを使用します。
おさらいとして、① primary key (town, street) を持つ例のテーブルでは、② 挿入されたデータは ③ ディスク上に格納され、primary key の列値でソートされ、圧縮され、各列ごとに別々のファイルとして保存されます。
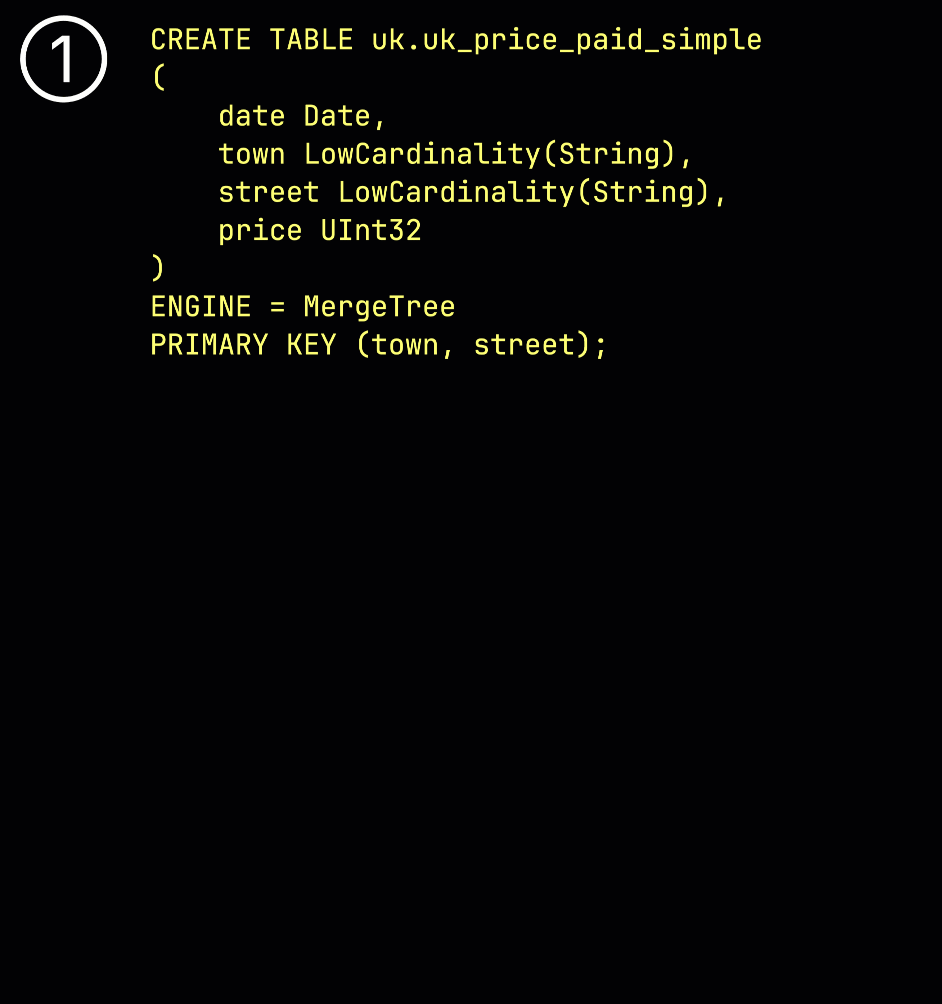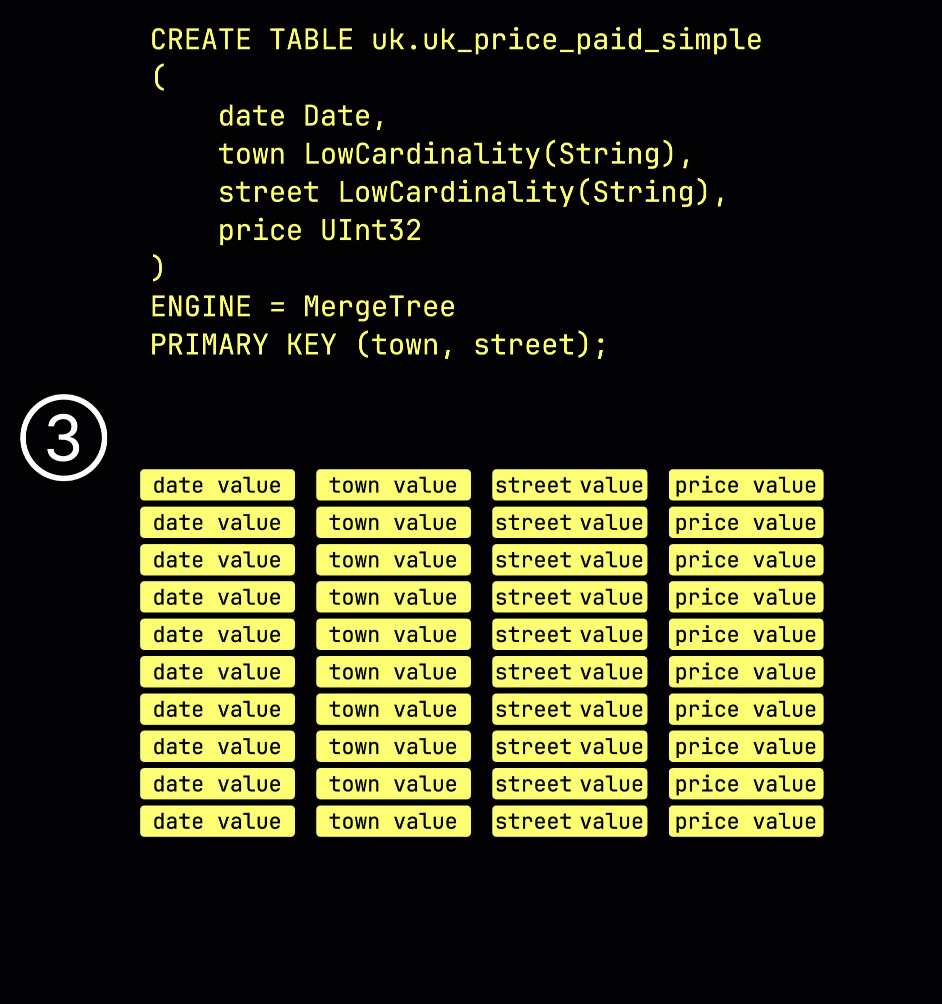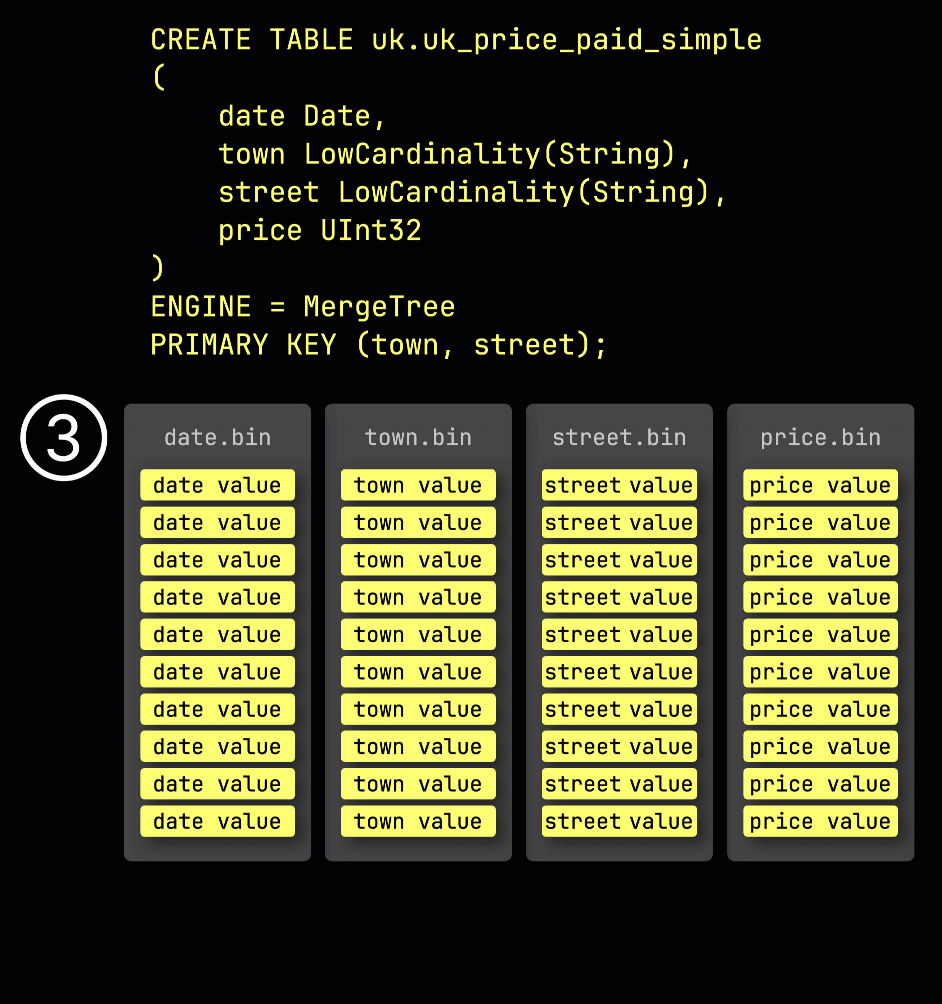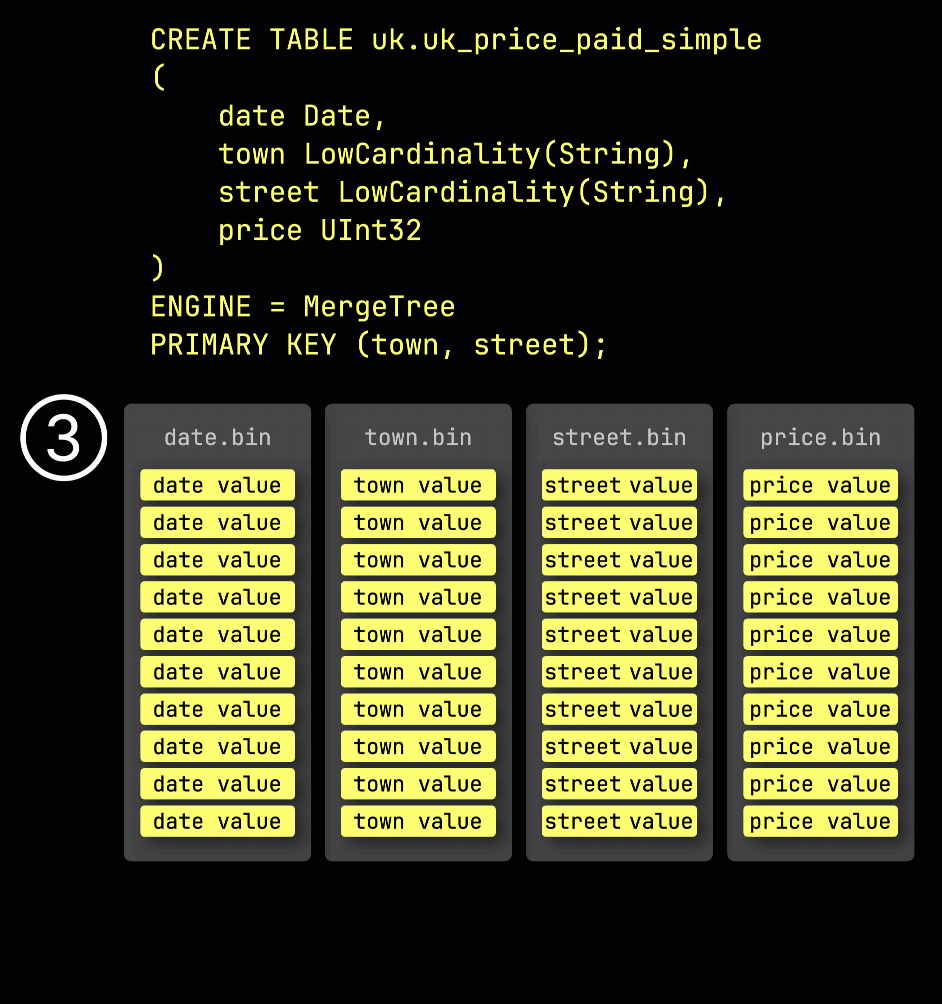
処理のために、各列のデータは ④ 論理的にグラニュールに分割されます。各グラニュールは 8,192 行を含み、ClickHouse のデータ処理メカニズムが扱う最小単位です。
この granule 構造こそが、プライマリインデックスが 疎 である理由です。すべての行をインデックスする代わりに、ClickHouse は ⑤ 各 granule について 1 行分、具体的には最初の行の primary key の値だけを保存します。これにより、granule ごとに 1 つのインデックスエントリが作成されます。
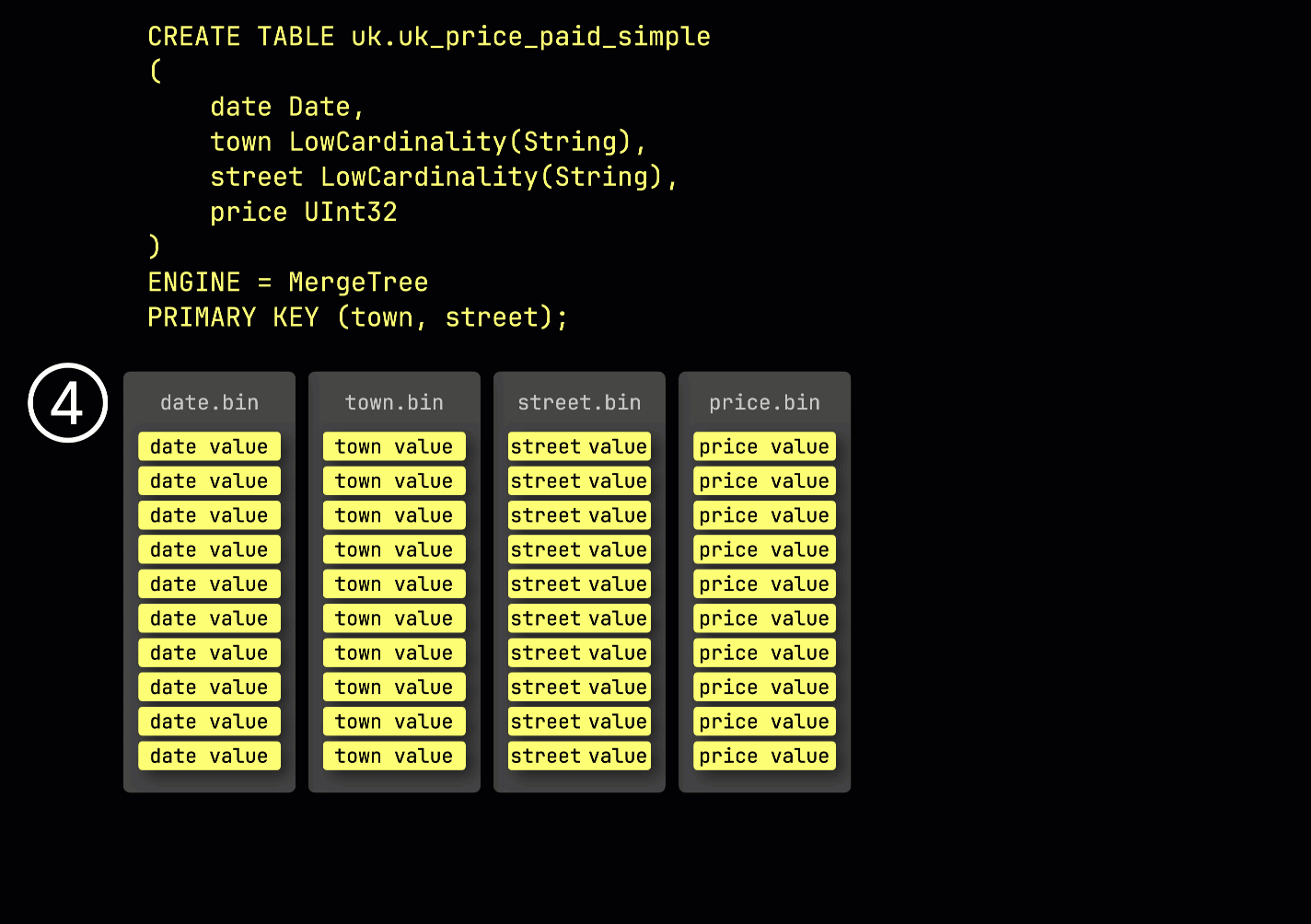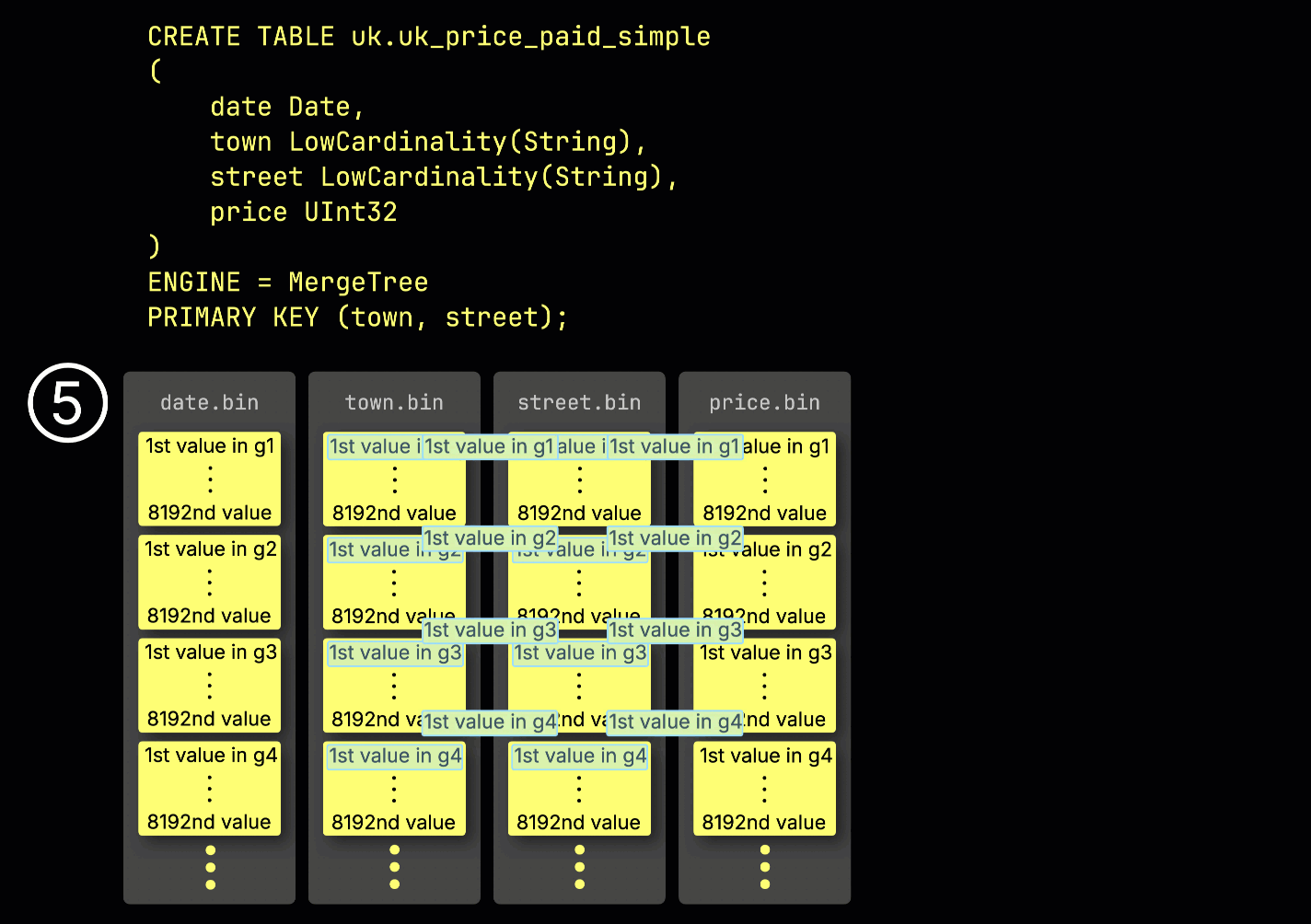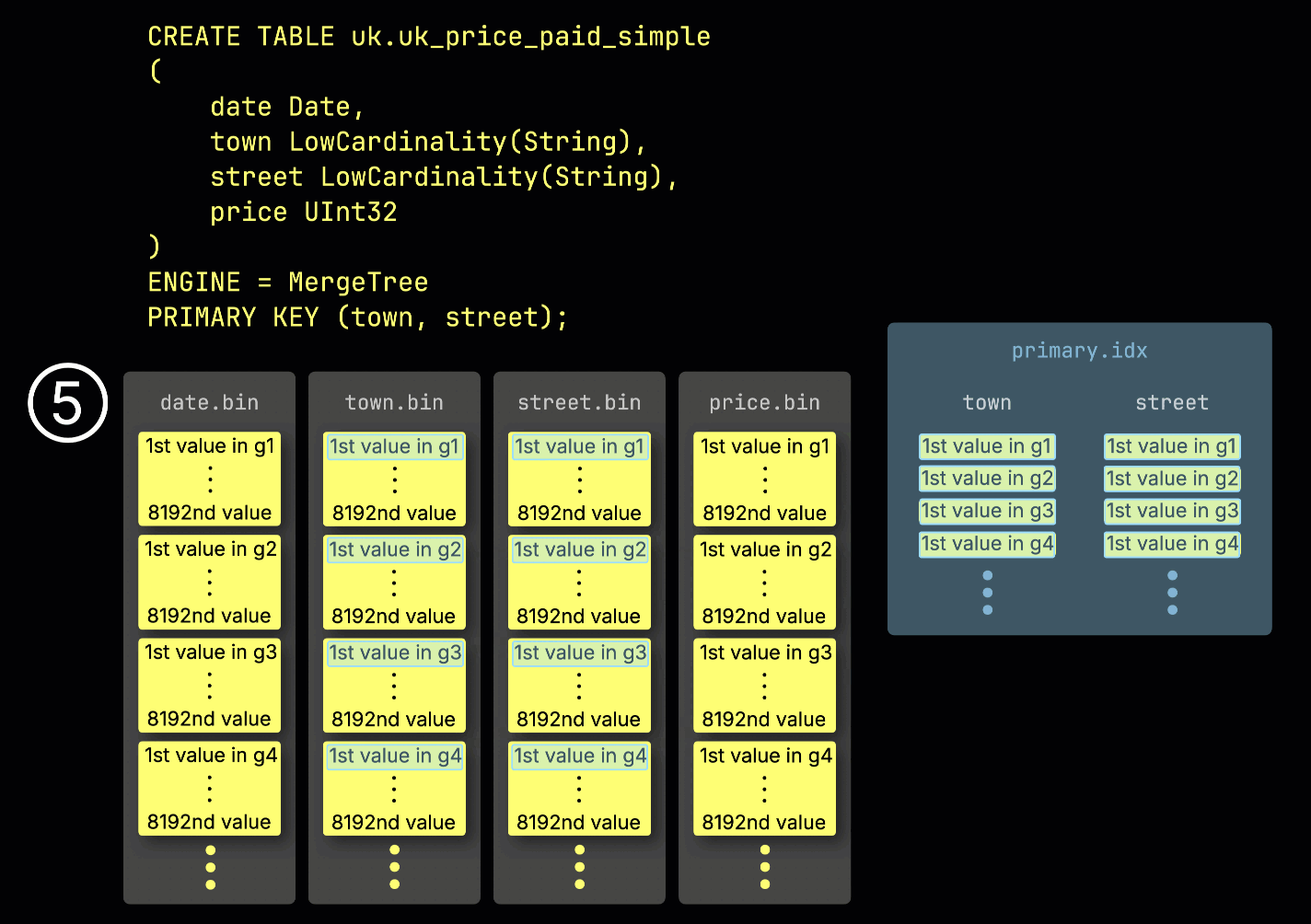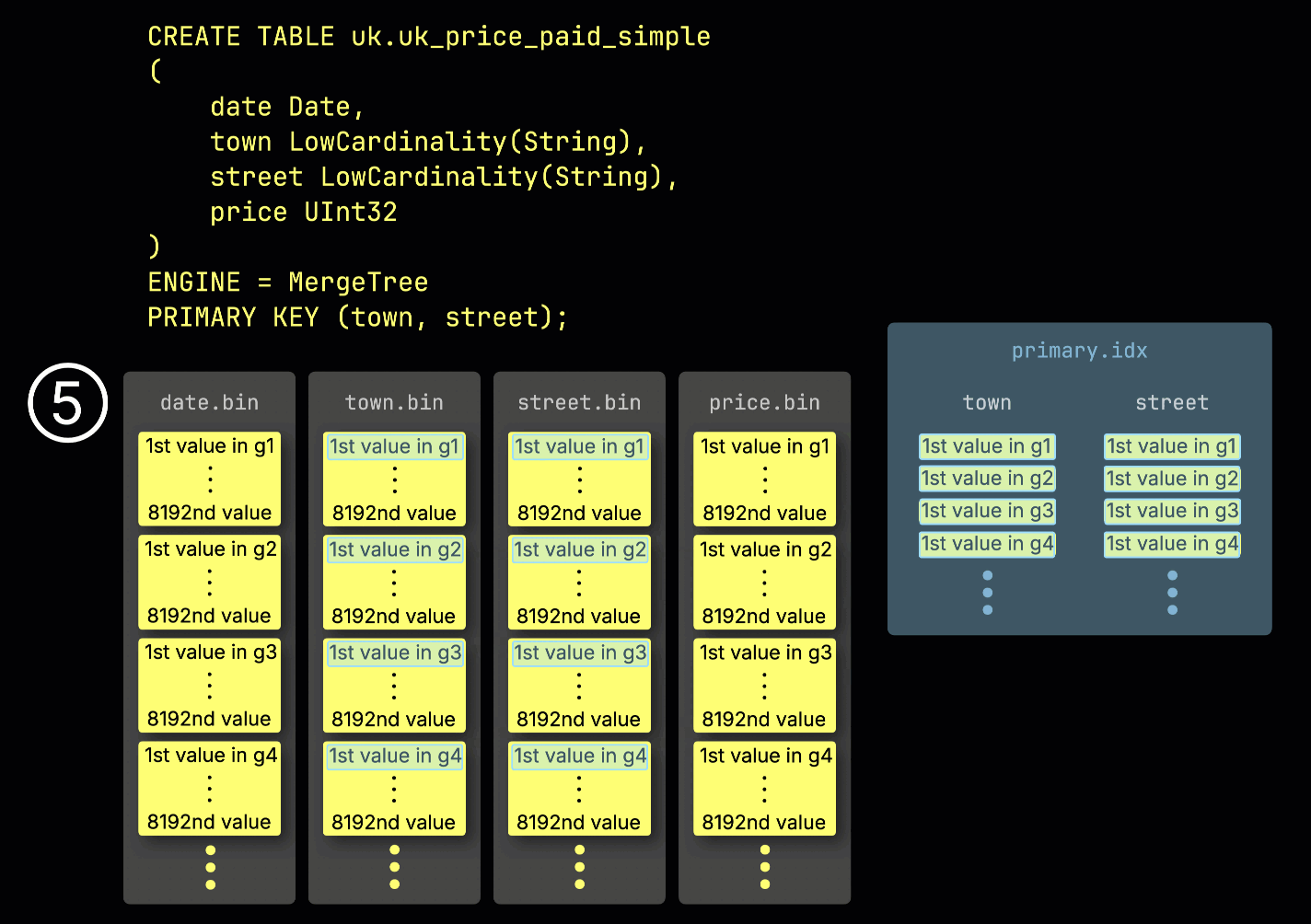
このように疎であるおかげで、プライマリインデックスはメモリに完全に収まるほど小さくなり、primary key 列に対して述語を持つクエリを高速にフィルタリングできます。次のセクションでは、このインデックスがそのようなクエリの高速化にどのように貢献するかを示します。
プライマリインデックスの利用方法
スパースプライマリインデックスがクエリ高速化にどのように利用されるかを、別のアニメーションで示します。
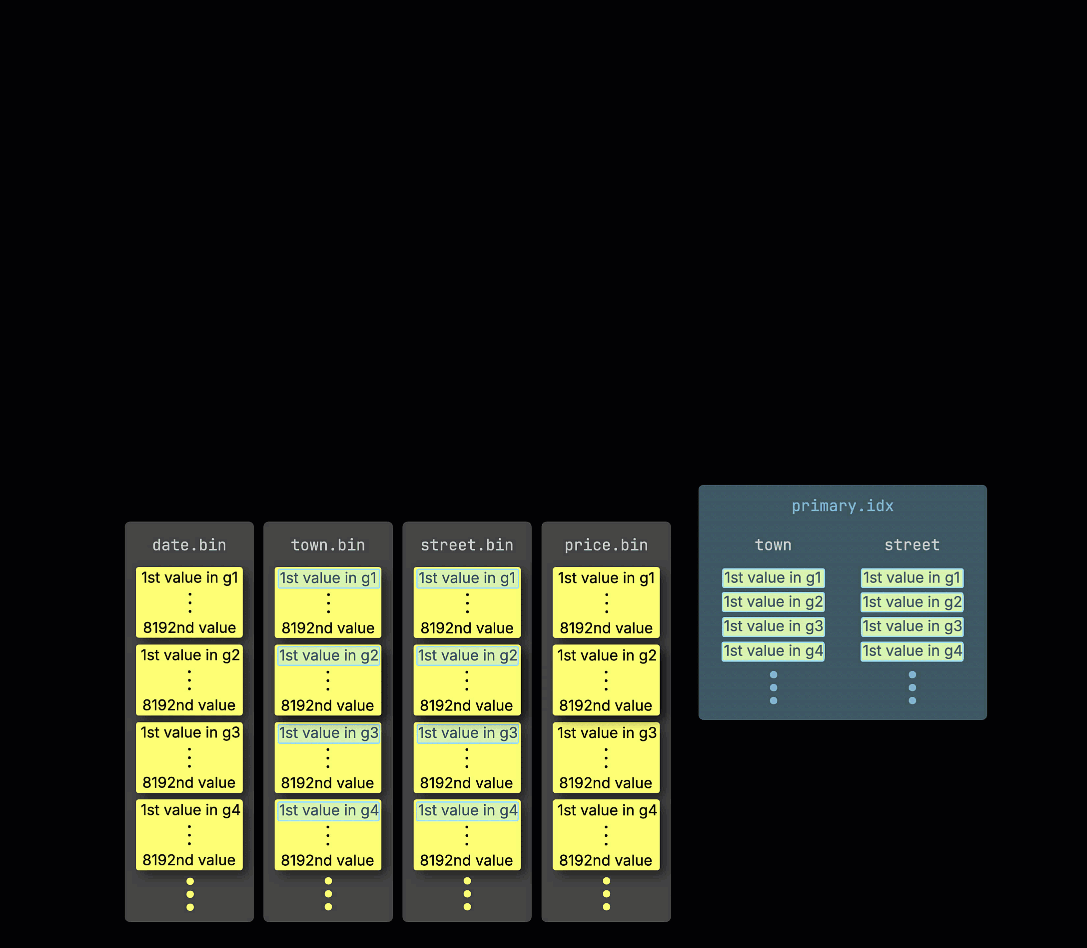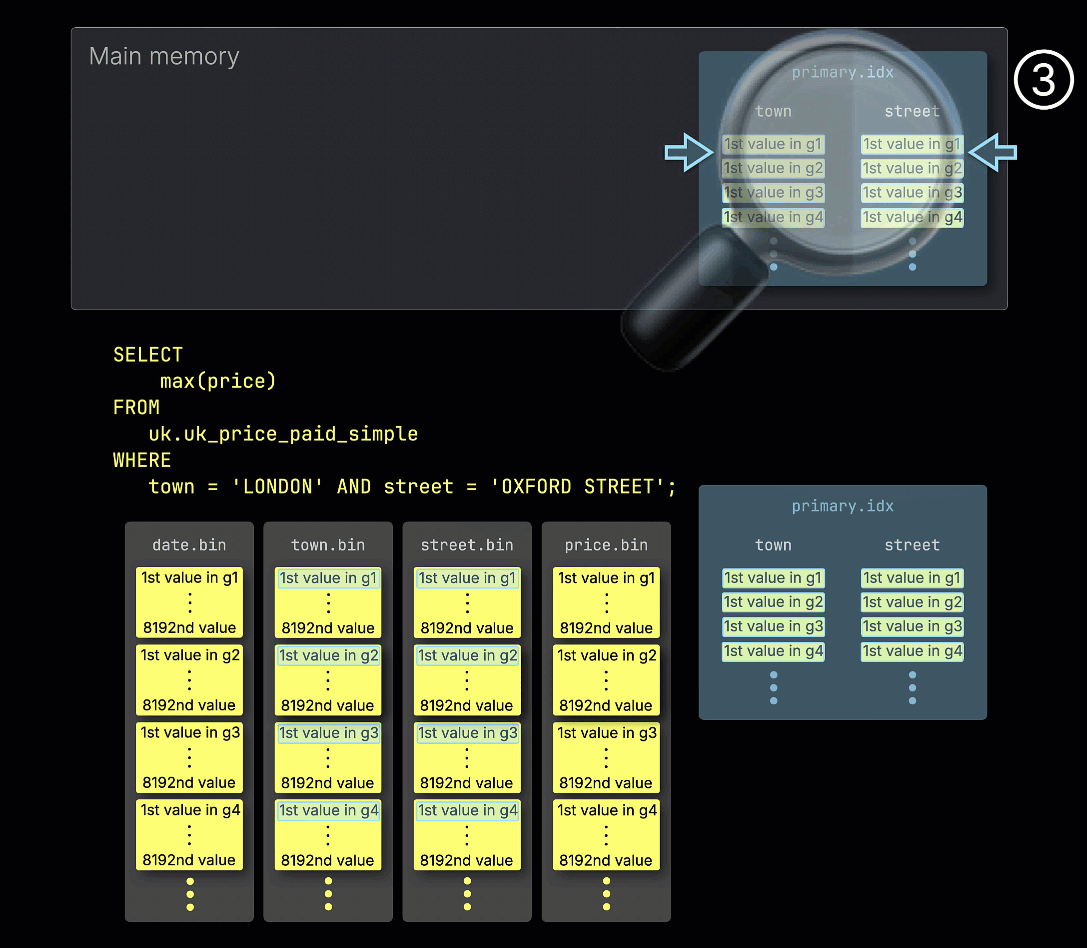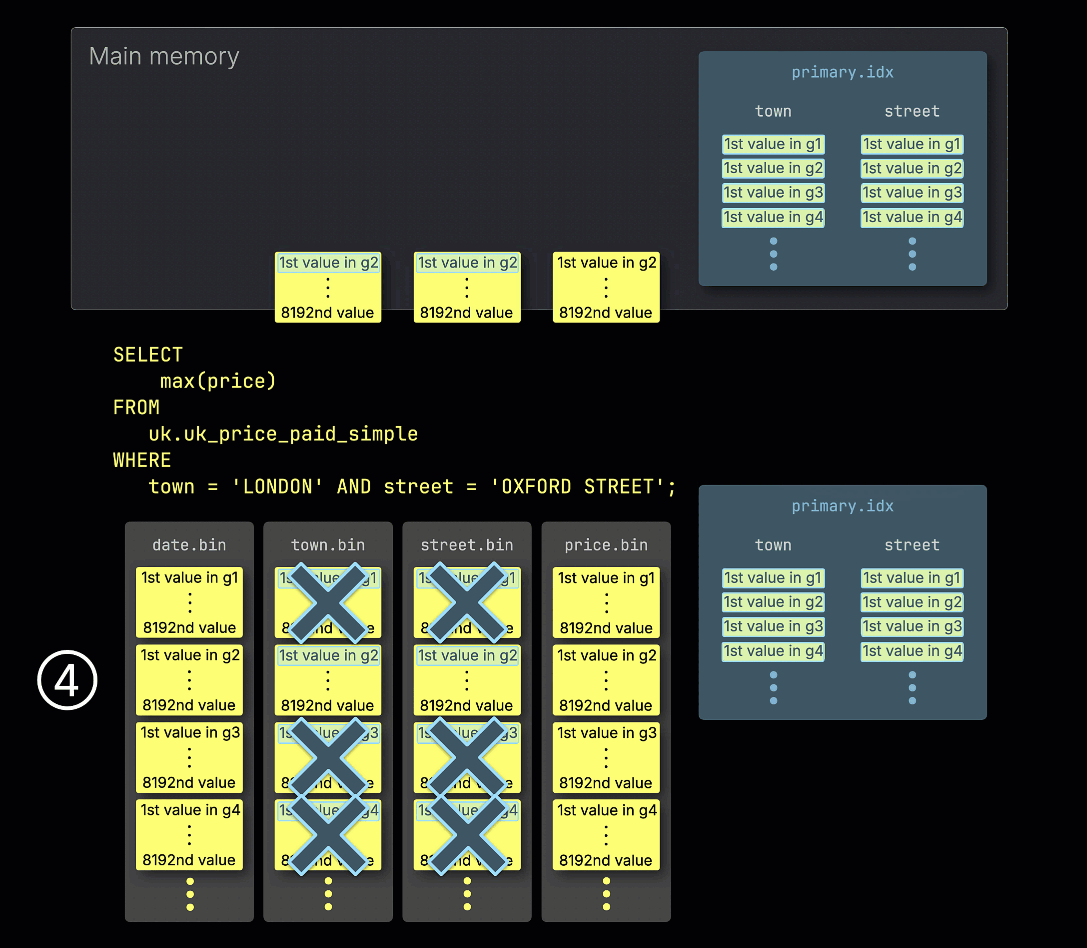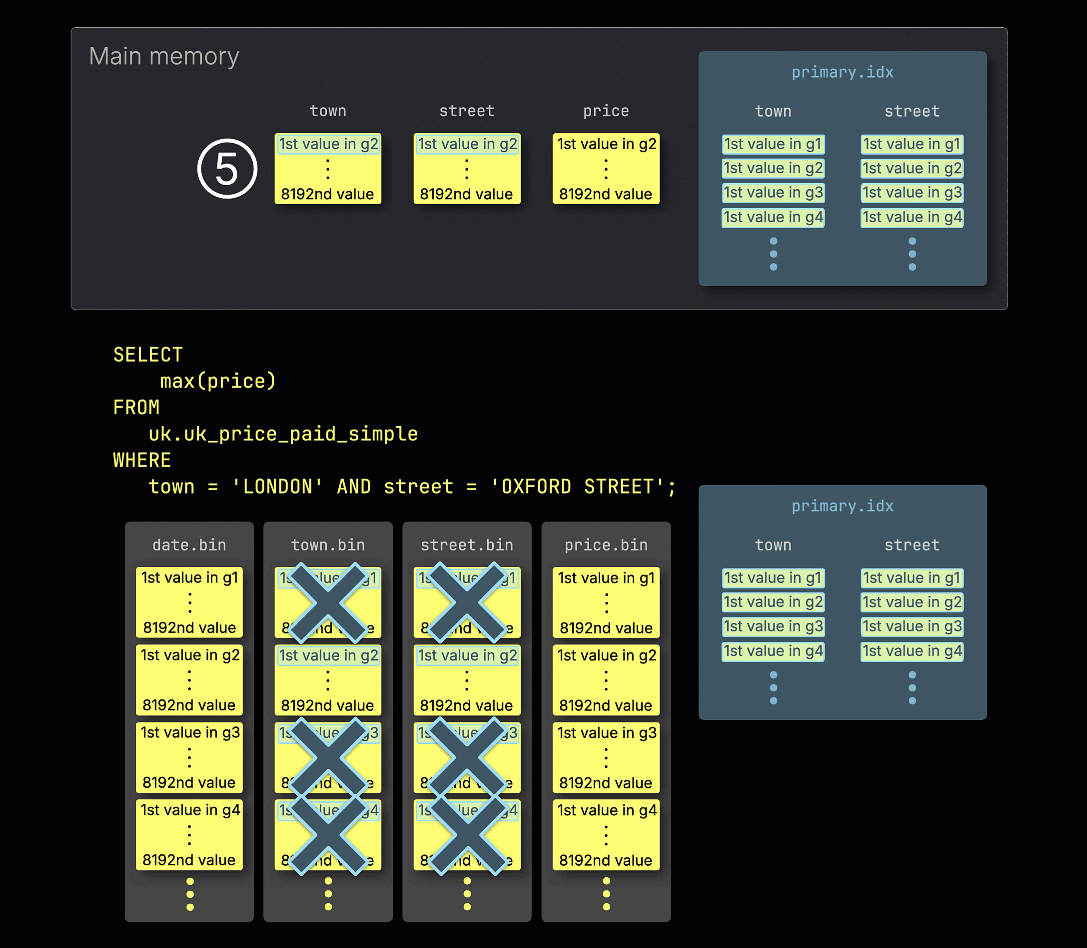
① この例のクエリには、主キーの両方の列に対する述語が含まれています: town = 'LONDON' AND street = 'OXFORD STREET'。
② クエリを高速化するために、ClickHouse はテーブルのプライマリインデックスをメモリにロードします。
③ その後、インデックスエントリを走査して、述語に一致する行を含んでいる可能性がある granule、言い換えるとスキップできない granule を特定します。
④ 次に、これらの関連する可能性がある granule が、クエリに必要な他の列の対応する granule とともにメモリにロードされて 処理 されます。
プライマリインデックスの監視
テーブル内の各データパーツは、それぞれ自身のプライマリインデックスを持ちます。mergeTreeIndex テーブル関数を使って、これらのインデックスの内容を確認できます。
次のクエリは、例のテーブルの各データパーツについて、プライマリインデックス内のエントリ数を一覧します。
このクエリは、現在のデータパートの 1 つにおけるプライマリインデックスの先頭 10 件を表示します。これらのパーツは、バックグラウンドで継続的に、より大きなパーツへとマージされていることに注意してください。
最後に、EXPLAIN 句を使用して、すべてのデータパーツのプライマリインデックスがどのように利用され、例のクエリの述語と一致する行を含み得ない granule をスキップしているかを確認します。これらの granule は、読み込みおよび処理の対象から除外されます。
上の EXPLAIN 出力の 13 行目を見ると、全データの^^parts^^にまたがる 3,609 個の granule のうち、処理のためにプライマリインデックス解析で選択されたのは 3 個だけであることが分かります。残りの granule はすべて完全にスキップされました。
また、クエリを実際に実行するだけでも、ほとんどのデータがスキップされていることを確認できます。
上記のとおり、例のテーブルでは約 3,000 万行のうち、処理されたのはおよそ 25,000 行だけでした。
Key takeaways
-
スパースプライマリインデックス により、ClickHouse は主キー列に対するクエリ条件に一致する行を含んでいる可能性がある granule を特定し、不要なデータをスキップできます。
-
各インデックスには、各 granule の先頭行の主キー値のみ が格納されます(granule はデフォルトで 8,192 行です)。そのため、メモリに収まるほどコンパクトです。
-
MergeTree テーブルの 各データパート は、それぞれ 独自のプライマリインデックス を持ち、クエリ実行時には個別に使用されます。
-
クエリ実行中、インデックスにより ClickHouse は granule をスキップ できるため、I/O とメモリ使用量を削減しながら性能を向上させます。
-
mergeTreeIndexテーブル関数を使用して インデックスの内容を確認 でき、EXPLAIN句でインデックスの使用状況を監視できます。
さらに詳しい情報を探すには
ClickHouse におけるスパースプライマリインデックスの動作について、従来型データベースのインデックスとの違いや利用時のベストプラクティスも含めてより深く知りたい場合は、インデックスに関する詳細な 解説 を参照してください。
プライマリインデックスのスキャンで選択されたデータを ClickHouse がどのように高い並列性で処理するかに興味がある場合は、クエリ並列処理に関するガイドをこちらで確認してください。
