SnowflakeからClickHouseへの移行
本ガイドでは、SnowflakeからClickHouseへデータを移行する方法について説明します。
SnowflakeとClickHouse間でデータを移行するには、転送用の中間ストレージとしてS3などのオブジェクトストアを使用する必要があります。移行プロセスでは、SnowflakeのCOPY INTOコマンドとClickHouseのINSERT INTO SELECTコマンドを使用します。
Snowflake からのデータエクスポート
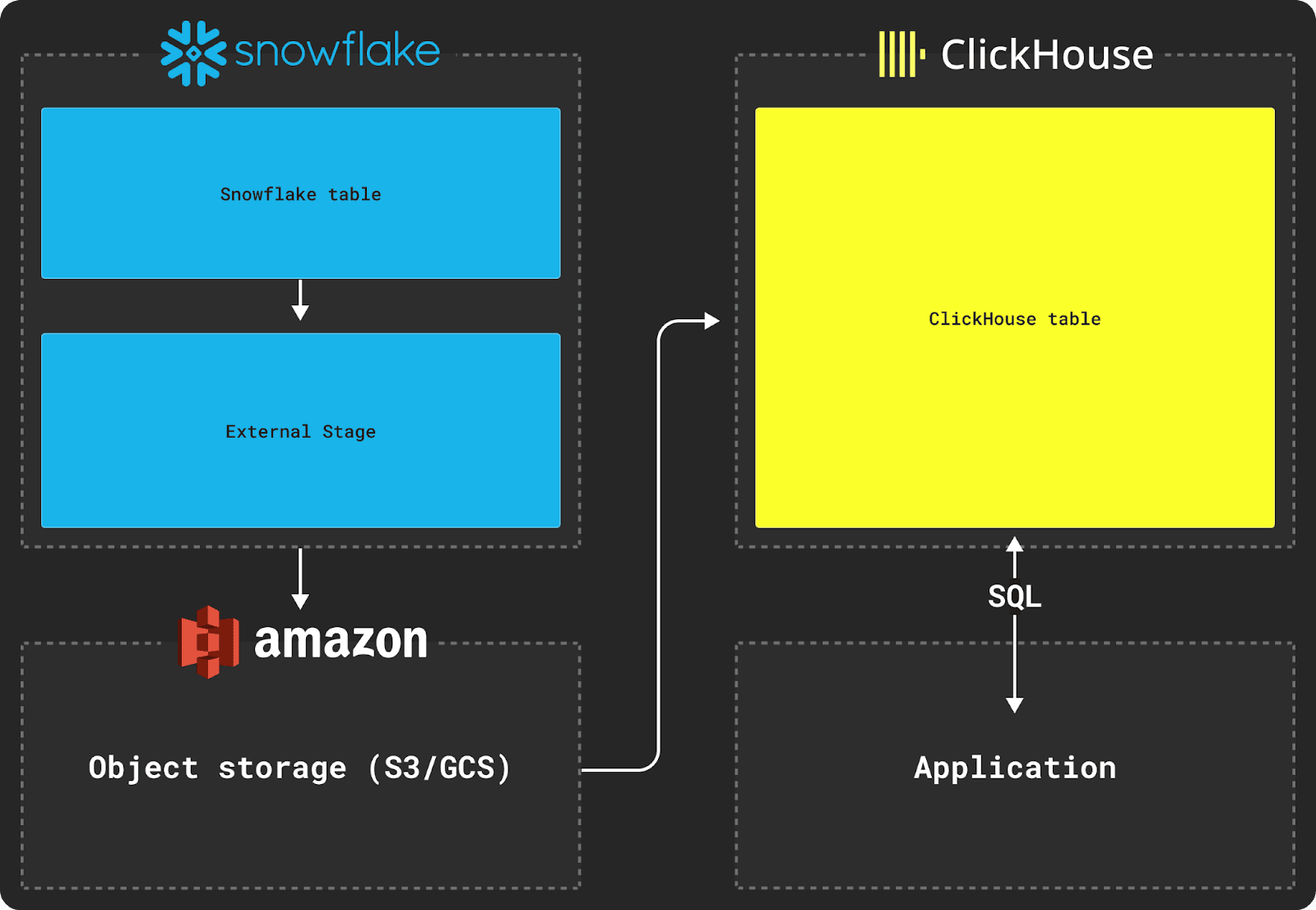
Snowflake からデータをエクスポートするには、上図のように外部ステージを使用する必要があります。
次のスキーマを持つ Snowflake テーブルをエクスポートしたいとします:
このテーブルのデータを ClickHouse データベースに移動するには、まずこのデータを外部ステージにコピーする必要があります。データのコピー時には、中間フォーマットとして Parquet を使用することを推奨します。Parquet は型情報を共有でき、精度を保持し、圧縮率が高く、分析で一般的なネストした構造をネイティブにサポートするためです。
以下の例では、Snowflake で Parquet と必要なファイルオプションを表す名前付きファイルフォーマットを作成します。次に、コピーされたデータセットを格納するバケットを指定します。最後に、そのバケットにデータセットをコピーします。
約 5TB のデータセットに対して最大ファイルサイズを 150MB に設定し、同じ AWS us-east-1 リージョンにある 2X-Large の Snowflake ウェアハウスを使用した場合、S3 バケットへのデータコピーにはおよそ 30 分かかります。
ClickHouse へのインポート
データが中間オブジェクトストレージにステージングされたら、以下のように s3 テーブル関数 などの ClickHouse の関数を使用して、テーブルにデータを挿入できます。
この例では AWS S3 向けの s3 テーブル関数 を使用していますが、Google Cloud Storage には gcs テーブル関数、Azure Blob Storage には azureBlobStorage テーブル関数 を使用できます。
対象となるテーブルのスキーマを次のように想定します:
次に、INSERT INTO SELECT コマンドを使用して、S3 上のデータを ClickHouse のテーブルに挿入します。
元の Snowflake テーブルスキーマ内の VARIANT 列と OBJECT 列は、デフォルトでは JSON 文字列として出力されます。そのため、ClickHouse に挿入する際には、これらをキャストする必要があります。
some_file のようなネストした構造は、Snowflake によるコピー処理の際に JSON 文字列へと変換されます。このデータをインポートするには、上記の JSONExtract 関数 を使用して、ClickHouse への挿入時にこれらの構造を Tuple 型に変換する必要があります。
