Amazon Redshift から ClickHouse への移行ガイド
はじめに
Amazon Redshift は、Amazon Web Services が提供するクラウド型データウェアハウスソリューションとして広く利用されています。本ガイドでは、Redshift インスタンスから ClickHouse へデータを移行する複数のアプローチを紹介します。ここでは次の 3 つのオプションを取り上げます。
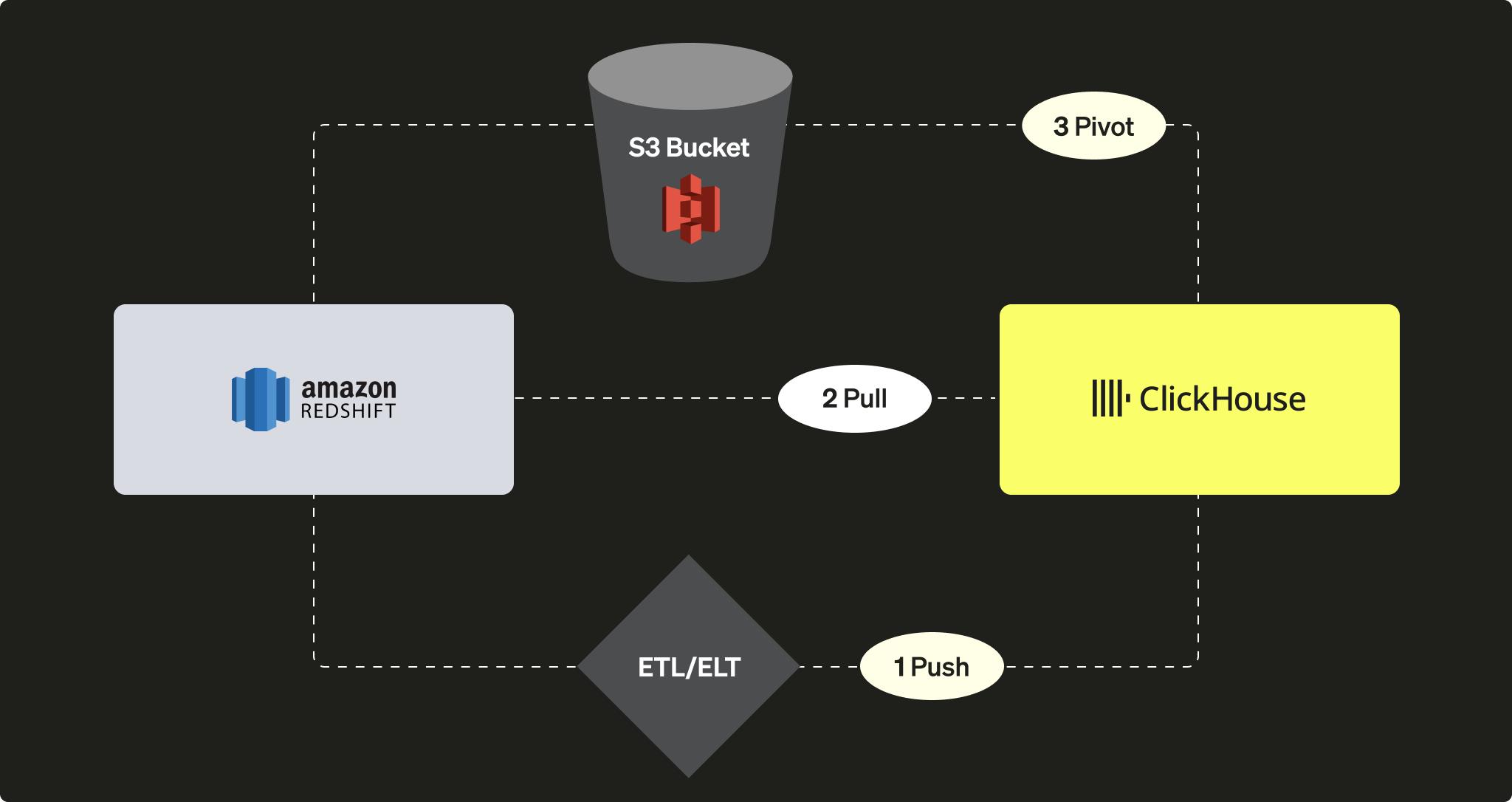
ClickHouse インスタンス側の観点からは、次のいずれかを選択できます。
-
サードパーティの ETL/ELT ツールまたはサービスを使用して、ClickHouse へデータを PUSH する
-
ClickHouse JDBC Bridge を利用して、Redshift からデータを PULL する
-
S3 オブジェクトストレージを利用し、「アンロードしてからロードする(unload-then-load)」というロジックで PIVOT する
このチュートリアルでは、データソースとして Redshift を使用しています。ただし、ここで紹介する移行アプローチは Redshift に限定されるものではなく、互換性のある任意のデータソースに対しても、同様の手順を応用できます。
Redshift から ClickHouse へデータをプッシュする
プッシュシナリオでは、サードパーティのツールやサービス(カスタムコード、または ETL/ELT)を利用して、ClickHouse インスタンスにデータを送信します。たとえば、Airbyte のようなソフトウェアを使用して、Redshift インスタンス(ソース)から ClickHouse(宛先)へデータを移動できます(Airbyte との連携ガイドも参照してください)。

利点
- 既存の ETL/ELT ソフトウェアのコネクタカタログを活用できる。
- データの同期を維持するための機能(追記/上書き/増分ロジック)が組み込まれている。
- データ変換シナリオを実現できる(例として、dbt 連携ガイド を参照)。
欠点
- ETL/ELT 基盤を構築し、運用・保守する必要があります。
- アーキテクチャにサードパーティコンポーネントが追加され、スケーラビリティのボトルネックとなる可能性があります。
Redshift から ClickHouse へのプル型データ取得
プル型シナリオでは、ClickHouse インスタンスから Redshift クラスターに直接接続するために ClickHouse JDBC Bridge を利用し、INSERT INTO ... SELECT クエリを実行します。

利点
- すべての JDBC 互換ツールで汎用的に利用できる
- ClickHouse 内から複数の外部データソースに対してクエリを実行できる、洗練されたソリューション
デメリット
- スケーラビリティのボトルネックとなり得る ClickHouse JDBC Bridge インスタンスが必要になります
Redshift は PostgreSQL ベースですが、ClickHouse の PostgreSQL テーブル関数やテーブルエンジンは利用できません。これは、ClickHouse では PostgreSQL バージョン 9 以上が必要である一方、Redshift の API はそれ以前のバージョン (8.x) に基づいているためです。
チュートリアル
このオプションを使用するには、ClickHouse JDBC Bridge をセットアップする必要があります。ClickHouse JDBC Bridge は、JDBC 接続を処理し、ClickHouse インスタンスとデータソース間のプロキシとして動作するスタンドアロンの Java アプリケーションです。このチュートリアルでは、あらかじめデータが投入されている Redshift インスタンスと、その サンプルデータベース を使用します。
ClickHouse JDBC Bridge をデプロイする
ClickHouse JDBC Bridge をデプロイします。詳細については、外部データソース向け JDBC に関するユーザーガイドを参照してください。
ClickHouse Cloud を使用している場合は、ClickHouse JDBC Bridge を別の環境で実行し、remoteSecure 関数を使用して ClickHouse Cloud に接続する必要があります。
Redshift データソースを設定する
ClickHouse JDBC Bridge 用に Redshift データソースを設定します。たとえば、/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json のようにします。
ClickHouse から Redshift インスタンスにクエリを実行する
ClickHouse JDBC Bridge がデプロイされ稼働したら、ClickHouse から Redshift インスタンスに対してクエリを実行できるようになります。
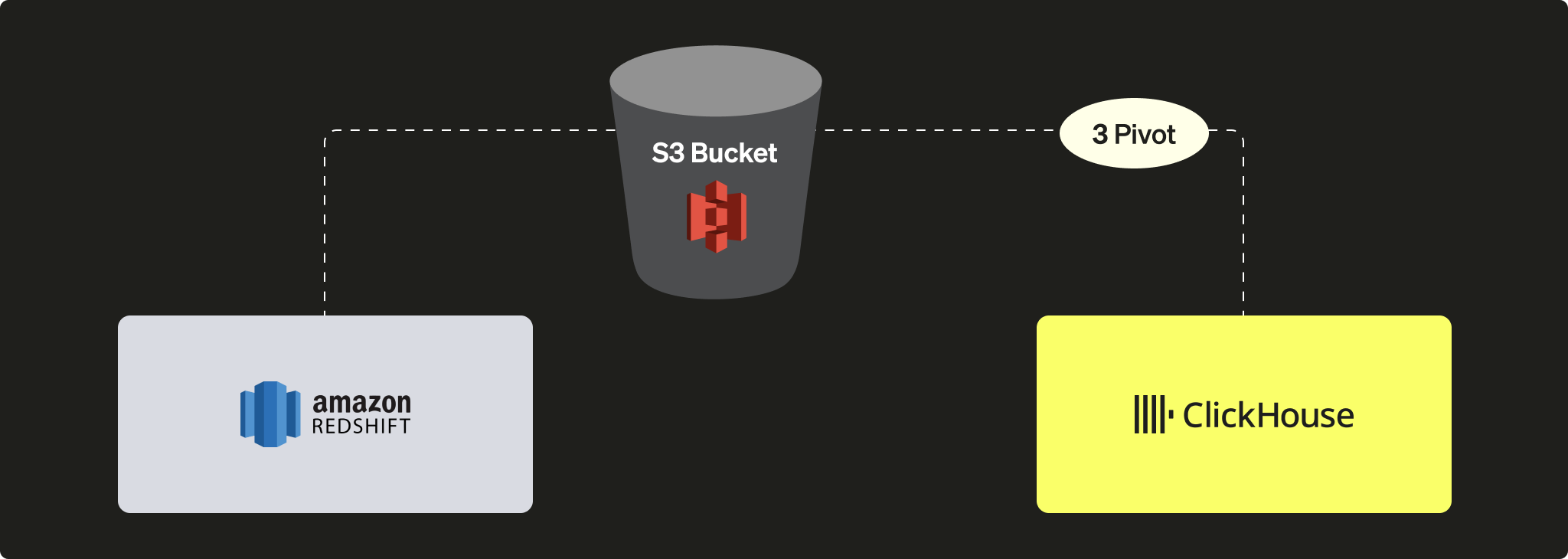
S3 を使用して Redshift から ClickHouse へデータをピボットする
このシナリオでは、ピボット用の中間フォーマットでデータを S3 にエクスポートし、次の段階で S3 から ClickHouse にデータをロードします。
利点
- Redshift と ClickHouse はどちらも強力な S3 連携機能を備えています。
- Redshift の
UNLOADコマンドや ClickHouse の S3 テーブル関数/テーブルエンジンなど、既存の機能を活用できます。 - ClickHouse による S3 から/への並列読み取りと高スループットにより、シームレスにスケールします。
- Apache Parquet のような高機能な圧縮フォーマットを活用できます。
デメリット
- プロセスが2段階になる(Redshiftからアンロードし、その後ClickHouseへロードする必要がある)。
チュートリアル
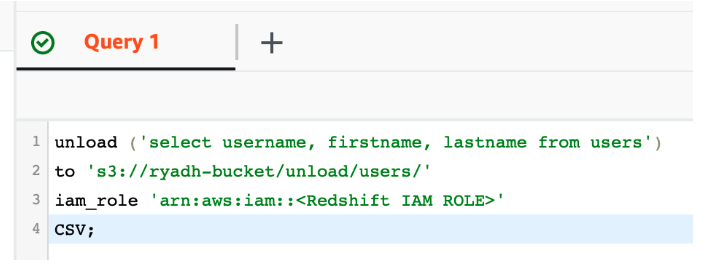

ClickHouse にテーブルを作成する
ClickHouse でテーブルを作成します:
または、ClickHouse に CREATE TABLE ... EMPTY AS SELECT を使用してテーブル構造を推論させることもできます。
これは、Parquet のようにデータ型に関する情報を含む形式でデータが保存されている場合に特に有効です。
S3 ファイルを ClickHouse にロードする
INSERT INTO ... SELECT ステートメントを使用して、S3 ファイルを ClickHouse にロードします。
この例では、データ形式として CSV を使用しています。ただし、本番ワークロードにおける大規模なマイグレーションでは、圧縮機能があり、ストレージコストの削減と転送時間の短縮の両方が見込めるため、Apache Parquet を最適な選択肢として推奨します(デフォルトでは、各 row group(行グループ)は SNAPPY で圧縮されます)。ClickHouse はまた、Parquet のカラム指向構造を活用してデータのインジェストを高速化します。
