高速分析のための SQL Server から ClickHouse へデータをストリーミングする:ステップバイステップガイド
この記事では、SQL Server から ClickHouse へデータをストリーミングする方法を、チュートリアル形式で詳しく解説します。ClickHouse は、社内向けまたはカスタマー向けダッシュボード向けレポーティングで超高速な分析が必要な場合に理想的です。両方のデータベースのセットアップ方法、接続方法、そして最終的に Streamkap を使ってデータをストリーミングする手順まで、ステップごとに見ていきます。日々の業務は SQL Server で処理しつつ、分析には ClickHouse のスピードと高度な分析機能を活用したい場合、本記事が最適なガイドとなります。
なぜ SQL Server から ClickHouse へデータをストリーミングするのか?
ここにたどり着いたということは、すでにその課題を感じているはずです。SQL Server はトランザクション用途としては非常に堅牢ですが、重いリアルタイム分析クエリを実行するようには設計されていません。
そこで力を発揮するのが ClickHouse です。ClickHouse は巨大なデータセットに対しても超高速な集計やレポーティングを行う分析向けデータベースとして設計されています。そのため、トランザクションデータを ClickHouse にプッシュするストリーミング CDC パイプラインを構成すれば、超高速なレポートを実行できるようになり、運用、プロダクトチーム、カスタマーダッシュボードなどに最適です。
代表的なユースケースは次のとおりです:
- 本番アプリケーションを遅くしない内部向けレポーティング
- 高速かつ常に最新の状態を求められるカスタマー向けダッシュボード
- 分析用にユーザーアクティビティログを常に最新に保つイベントストリーミング
開始にあたって必要なもの
本題に入る前に、あらかじめ次のものを用意しておいてください。
前提条件
-
稼働中の SQL Server インスタンス
-
このチュートリアルでは AWS RDS for SQL Server を使用しますが、最新の SQL Server インスタンスであればどれでも使用できます。AWS SQL Server をゼロからセットアップ
-
ClickHouse インスタンス
-
セルフホスト環境でもクラウド環境でもかまいません。ClickHouse をゼロからセットアップ
-
Streamkap
-
このツールがデータストリーミングパイプラインの中核となります。
接続情報
次の情報を用意しておいてください。
- SQL Server のサーバーアドレス、ポート、ユーザー名、パスワード。Streamkap が SQL Server データベースへアクセスできるよう、専用のユーザーとロールを作成することを推奨します。設定方法についてはドキュメントを参照してください。
- ClickHouse のサーバーアドレス、ポート、ユーザー名、パスワード。ClickHouse の IP アクセスリストによって、どのサービスが ClickHouse データベースに接続できるかが決まります。こちらの手順に従ってください。
- ストリーミングするテーブル (まずは 1 つから始めてください)
SQL Server をデータソースとしてセットアップする
それでは始めましょう。
ステップ 1: Streamkap で SQL Server ソースを作成する
まずはソースの接続を設定します。これにより、Streamkap がどこから変更データを取得すればよいかを把握できるようになります。
手順は次のとおりです:
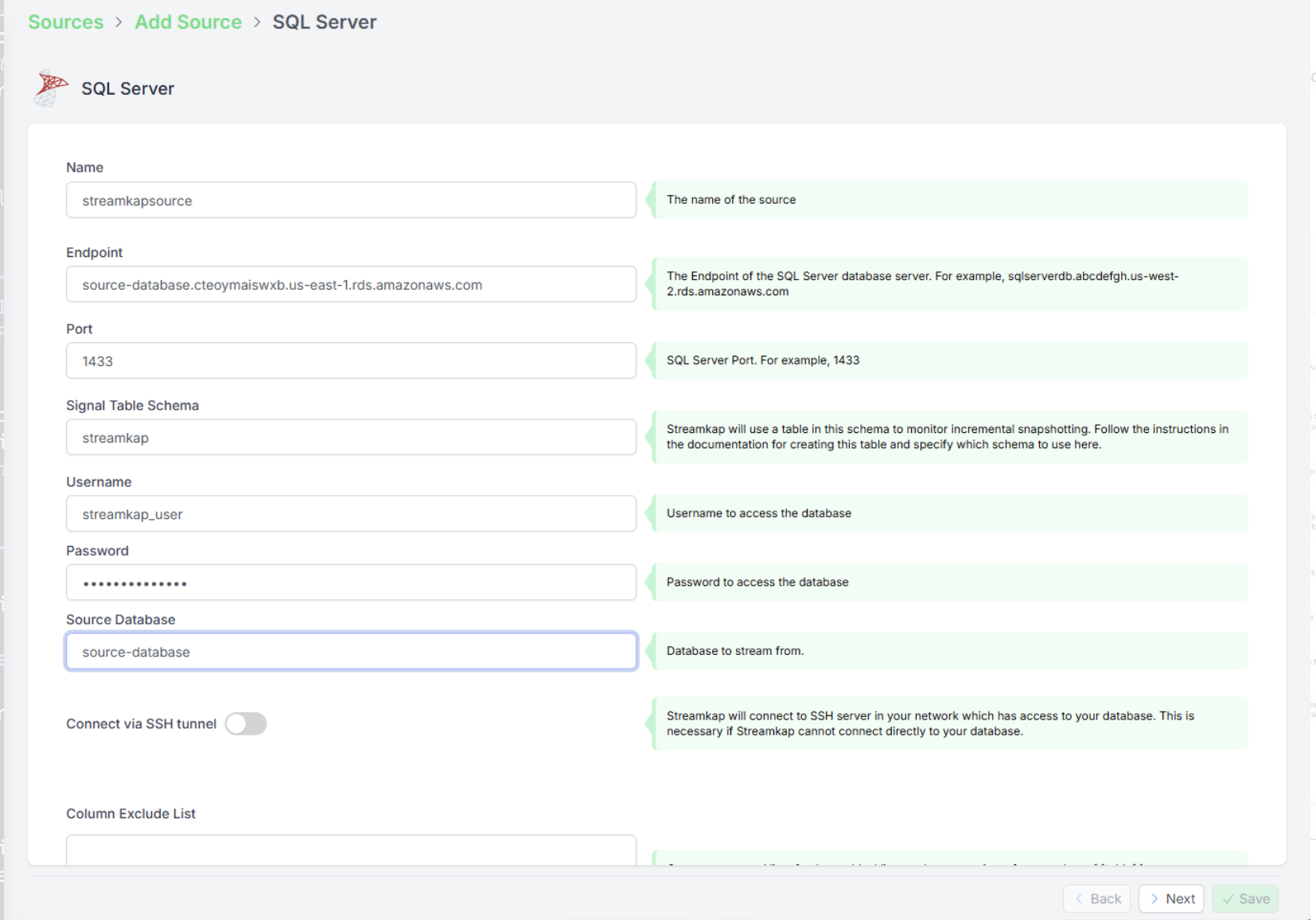
- Streamkap を開き、[Sources] セクションに移動します。
- 新しいソースを作成します。
- わかりやすい名前を付けます(例: sqlserver-demo-source)。
- SQL Server の接続情報を入力します:
- ホスト(例: your-db-instance.rds.amazonaws.com)
- ポート(SQL Server のデフォルトは 3306)
- ユーザー名とパスワード
- データベース名
裏側で何が起きているか
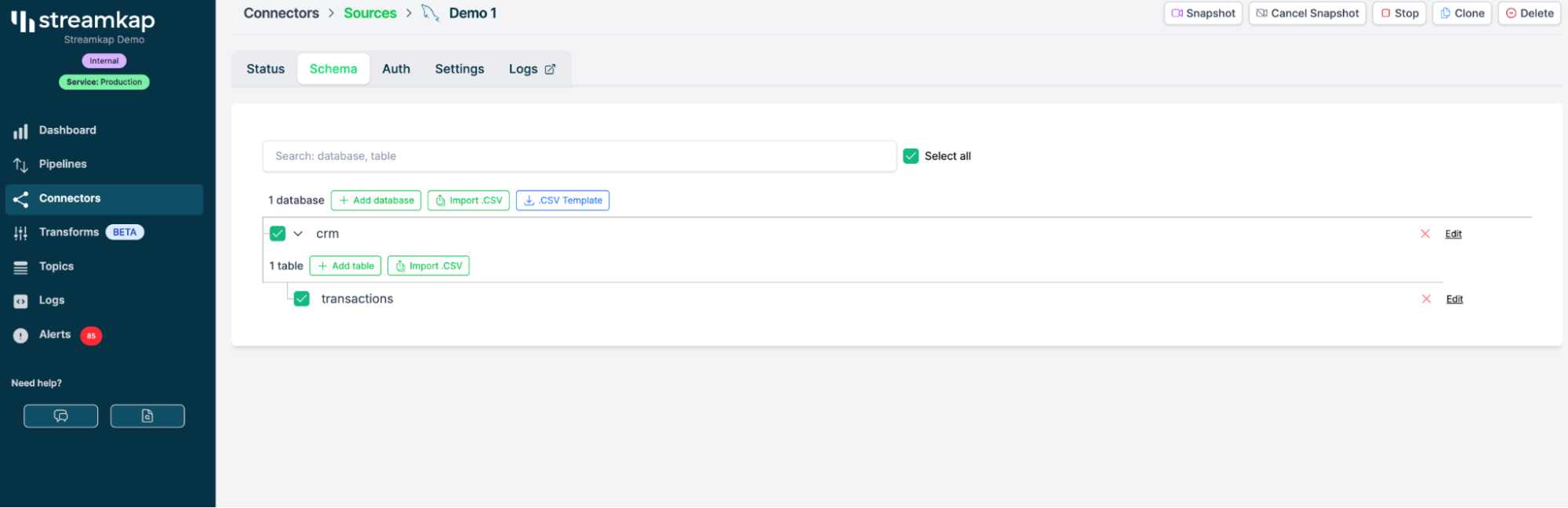
これをセットアップすると、Streamkap が SQL Server に接続し、テーブルを自動検出します。このデモでは、すでにデータがストリーミングされている events や transactions などのテーブルを選択します。
ClickHouse 宛先の作成
これらすべてのデータの送信先となる ClickHouse 宛先を設定しましょう。
ステップ 2: Streamkap に ClickHouse 宛先を追加する
ソースと同様に、ClickHouse の接続情報を使用して宛先を作成します。
手順:
- Streamkap の Destinations セクションに移動します。
- 新しい宛先を追加し、宛先タイプとして ClickHouse を選択します。
- ClickHouse の情報を入力します:
- ホスト
- ポート(デフォルトは 9000)
- Username と Password
- データベース名
例のスクリーンショット: Streamkap ダッシュボードで新しい ClickHouse 宛先を追加している画面。
アップサートモードとは何か
ここは重要なステップです。ClickHouse の「アップサート」モードを使用します。これは内部的には ClickHouse の ReplacingMergeTree エンジンを利用して動作します。これにより、受信したレコードを効率的にマージし、ClickHouse が「パーツマージ」と呼ぶ仕組みを使って、取り込み後の更新を処理できます。
- これにより、SQL Server 側でデータが変更された場合でも、宛先テーブルが重複データで埋め尽くされるのを防ぐことができます。
スキーマ変更への対応
ClickHouse と SQL Server では、カラム構成が同じとは限りません。特に、本番稼働中のアプリで開発者が随時カラムを追加しているような場合はなおさらです。
- 良い知らせとして、Streamkap は基本的なスキーマ変更をサポートしています。つまり、SQL Server 側で新しいカラムを追加すると、ClickHouse 側にも自動的に反映されます。
宛先の設定で「schema evolution」を選択するだけです。必要に応じて、後からいつでも調整できます。
ストリーミングパイプラインの構築
ソースと宛先の設定が完了したら、いよいよデータのストリーミングを始めましょう。
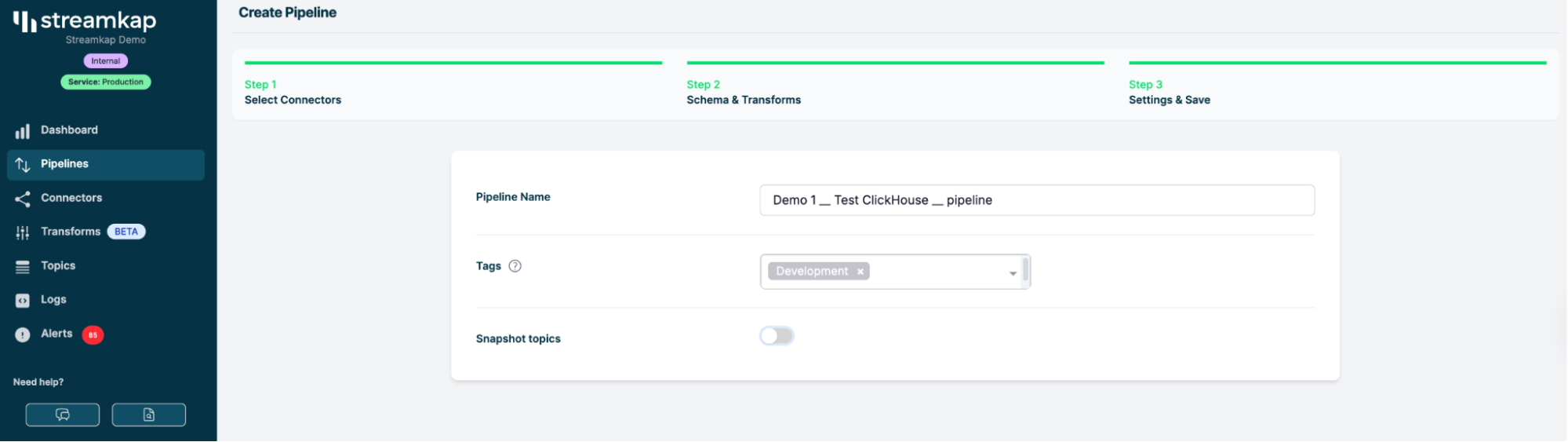
ステップ3: Streamkap でパイプラインをセットアップする
パイプラインのセットアップ
-
Streamkap の Pipelines タブを開きます。
-
新しいパイプラインを作成します。
-
SQL Server のソース(sqlserver-demo-source)を選択します。
-
ClickHouse の宛先(clickhouse-tutorial-destination)を選択します。
-
ストリーミングしたいテーブルを選択します—ここでは events とします。
-
Change Data Capture(CDC)の設定を行います。
- 今回の実行では、新規データのみをストリーミングします(最初はバックフィルを行わず、CDC イベントに集中してかまいません)。
パイプライン設定のスクリーンショット—ソース、宛先、テーブルを選択している様子。
バックフィルすべきかどうか
「過去データもバックフィルすべきか?」と疑問に思うかもしれません。
多くの分析ユースケースでは、「今この時点からの変更データのストリーミング」だけを開始すれば十分なことが多いですが、必要になったときにあとから過去データを読み込むこともできます。
特別な要件がない限り、ひとまず「バックフィルしない」を選択してください。
ストリーミングの実行: 期待できること
これでパイプラインのセットアップが完了し、稼働を開始しました。
ステップ 4: データストリームを監視する
処理の流れは次のとおりです。
- 新しいデータが SQL Server 上のソーステーブルに書き込まれると、Streamkap パイプラインがその変更をキャプチャし、ClickHouse に送信します。
- ClickHouse は(ReplacingMergeTree とパーツのマージ処理のおかげで)これらの行を取り込み、更新をマージします。
- スキーマも追従します — SQL Server にカラムを追加すると、それらは ClickHouse にも反映されます。
ClickHouse と SQL Server の行数がリアルタイムで増加していく様子を示すライブダッシュボードまたはログ。
SQL Server にデータが入るにつれて、ClickHouse の行数が増加していくのを目で確認できます。
高負荷時にはある程度の遅延が発生することがありますが、ほとんどのケースではほぼリアルタイムにデータがストリーミングされます。
舞台裏:Streamkap は実際に何をしているのか?
少しだけ内部の仕組みをご紹介します。
- Streamkap は SQL Server のバイナリログ(レプリケーションでも使われるログ)を監視します。
- テーブルに行が挿入・更新・削除されるとすぐに、Streamkap がそのイベントを検知します。
- そのイベントを ClickHouse が理解できる形式に変換し、すぐに送信して、分析用データベースに即座に変更を反映します。
これは単なる ETL ではなく、リアルタイムストリーミングによる完全な変更データキャプチャ(CDC)です。
高度な設定
Upsert モード vs Insert モード
すべての行を単純に挿入するだけのモード(Insert モード)と、更新や削除もきちんと反映させるモード(Upsert モード)には、どのような違いがあるのでしょうか?
- Insert モード: 新しい行はすべて追加されます。たとえ更新であっても新しい行として挿入されるため、重複が発生します。
- Upsert モード: 既存の行に対する更新は、すでに存在するデータを上書きします。分析データを常に新鮮かつクリーンに保つのに、はるかに有効です。
スキーマ変更への対応
アプリケーションが変われば、スキーマも変わります。このパイプラインでは次のように動作します。
- 運用テーブルに新しいカラムを追加した場合:
Streamkap がそれを検出し、ClickHouse 側にもカラムを追加します。 - カラムを削除した場合:
設定によってはマイグレーションが必要になることもありますが、カラムの追加であれば多くの場合スムーズに反映されます。
実運用での監視:パイプラインの状態を把握する
パイプラインの健全性の確認
Streamkap には、次のことを行えるダッシュボードがあります。
- パイプラインの遅延(データはどれくらい新鮮か?)を確認する
- 行数とスループットを監視する
- 異常があればアラートを受け取る
ダッシュボード例: レイテンシーグラフ、行数、ヘルス指標。
監視すべき主なメトリクス
- Lag(遅延): ClickHouse が SQL Server に対してどの程度遅れているか
- Throughput(スループット): 1 秒あたりの行数
- Error Rate(エラー率): ほぼゼロであるべき
本番稼働: ClickHouse へのクエリ実行
データが ClickHouse に取り込まれたら、さまざまな高速分析ツールを使ってクエリを実行できます。基本的な例を次に示します。
ClickHouse を Grafana、Superset、Redash などのダッシュボードツールと組み合わせて活用し、本格的なレポーティングを実現しましょう。
次のステップと詳細な解説
このウォークスルーは、できることのごく一部を紹介したに過ぎません。基本を押さえたら、次のような内容を検討・実施できます。
- フィルタ済みストリームの設定(特定のテーブル/カラムだけを同期)
- 複数のソースから 1 つの分析用 DB へのストリーミング
- コールドストレージとしての S3/データレイクとの併用
- テーブル変更時のスキーママイグレーションの自動化
- SSL やファイアウォールルールによるパイプラインの保護
より詳細なガイドについては、Streamkap ブログを参照してください。
FAQ とトラブルシューティング
Q: これはクラウドデータベースでも動作しますか?
A: はい、動作します!この例では AWS RDS を使用しました。適切なポートを開放していることを確認してください。
Q: パフォーマンスはどうですか?
A: ClickHouse は高速です。ボトルネックになるのは、通常ネットワークかソース DB の binlog の速度ですが、ほとんどの場合、遅延は 1 秒未満です。
Q: 削除も扱えますか?
A: もちろん可能です。upsert モードでは、削除もフラグ付けされ、ClickHouse 側で処理されます。
まとめ
以上で、Streamkap を使って SQL Server のデータを ClickHouse にストリーミングする方法の全体像を説明しました。高速かつ柔軟で、本番データベースに負荷をかけずに最新の分析を必要とするチームに最適です。
試してみたくなりましたか?
Sign up ページにアクセスして、次のようなトピックの解説を希望する場合はお知らせください:
- Upsert と Insert の違いと、それぞれの詳細
- エンドツーエンドレイテンシー: 最終的な分析結果をどれだけ速く得られるか
- パフォーマンスチューニングとスループット
- このスタック上に構築した実運用ダッシュボードの実例
お読みいただきありがとうございました。快適なストリーミングをお楽しみください。
