バックアップコマンドを使用したセルフマネージド ClickHouse から ClickHouse Cloud への移行 セルフマネージドな ClickHouse (OSS) から ClickHouse Cloud へデータを移行するには、主に 2 つの方法があります:
データを直接取得/送信する remoteSecure()
BACKUP / RESTORE コマンドとクラウドオブジェクトストレージを使用する方法
この移行ガイドでは、BACKUP / RESTORE アプローチに焦点を当て、オープンソース版 ClickHouse のデータベースまたはサービス全体を S3 バケット経由で Cloud に移行する具体的な例を示します。
前提条件
このガイドの手順を追いやすく再現可能にするため、2 つの分片と 2 つのレプリカを持つ ClickHouse クラスター用の Docker Compose レシピの 1 つを使用します。
OSS の準備
まず、examples リポジトリにある Docker Compose 設定を使って ClickHouse クラスターを起動します。
すでに ClickHouse クラスターが稼働している場合は、ここでのクラスター起動手順は省略して構いません。
examples リポジトリ をローカル環境にクローンしますターミナルで examples/docker-compose-recipes/recipes/cluster_2S_2R に cd します
Docker が起動していることを確認したら、ClickHouse クラスターを起動します:
次のように表示されるはずです:
[+] Running 7/7
✔ Container clickhouse-keeper-01 Created 0.1s
✔ Container clickhouse-keeper-02 Created 0.1s
✔ Container clickhouse-keeper-03 Created 0.1s
✔ Container clickhouse-01 Created 0.1s
✔ Container clickhouse-02 Created 0.1s
✔ Container clickhouse-04 Created 0.1s
✔ Container clickhouse-03 Created 0.1s
フォルダのルートディレクトリで新しいターミナルウィンドウを開き、そこから次のコマンドを実行してクラスターの最初のノードに接続します。
docker exec -it clickhouse-01 clickhouse-client
MergeTree テーブルから ReplicatedMergeTree テーブルへ
ClickHouse Cloud では SharedMergeTreeReplicatedMergeTree を使用しているテーブルを自動的に SharedMergeTree テーブルへ変換します。
クラスターを実行している場合、すでにテーブルで ReplicatedMergeTree エンジンを使用している可能性が高いです。
そうでない場合は、バックアップを取得する前に、すべての MergeTree テーブルを ReplicatedMergeTree に変換する必要があります。
MergeTree テーブルを ReplicatedMergeTree に変換する方法を示すために、まずは MergeTree テーブルから始め、その後で ReplicatedMergeTree に変換します。
サンプルテーブルを作成してデータをロードするために、New York taxi data guide の最初の 2 ステップに従います。
便宜上、そのステップを以下に掲載しています。
次のコマンドを実行して、新しいデータベースを作成し、S3 バケットから新しいテーブルにデータを挿入します。
CREATE DATABASE nyc_taxi;
CREATE TABLE nyc_taxi.trips_small_adapted (
trip_id UInt32,
pickup_datetime DateTime,
dropoff_datetime DateTime,
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count UInt8,
trip_distance Float32,
fare_amount Float32,
extra Float32,
tip_amount Float32,
tolls_amount Float32,
total_amount Float32,
payment_type Enum('CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4, 'UNK' = 5),
pickup_ntaname LowCardinality(String),
dropoff_ntaname LowCardinality(String)
)
ENGINE = MergeTree
PRIMARY KEY (pickup_datetime, dropoff_datetime);
INSERT INTO nyc_taxi.trips_small_adapted
SELECT
trip_id,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
fare_amount,
extra,
tip_amount,
tolls_amount,
total_amount,
payment_type,
pickup_ntaname,
dropoff_ntaname
FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..2}.gz',
'TabSeparatedWithNames'
);
次のコマンドを実行してテーブルを DETACH します。
DETACH TABLE nyc_taxi.trips_small_adapted;
次に、レプリカとしてアタッチします:
ATTACH TABLE nyc_taxi.trips_small_adapted AS REPLICATED;
最後に、レプリカのメタデータを復元します:
SYSTEM RESTORE REPLICA nyc_taxi.trips_small_adapted;
ReplicatedMergeTree に変換されていることを確認してください:
SELECT engine
FROM system.tables
WHERE name = 'trips_small_adapted' AND database = 'nyc_taxi';
┌─engine──────────────┐
│ ReplicatedMergeTree │
└─────────────────────┘
これで、後で S3 バケットからバックアップをリストアできるよう、Cloud サービスのセットアップに進む準備が整いました。
ReplicatedMergeTree を使用した分散テーブル
セットアップで複数の分片にまたがる分散テーブルを使用している場合は、各ノードにローカルの ReplicatedMergeTree テーブルと、クエリのエントリポイントとなる Distributed テーブルが必要です。
以下のコマンドを実行して、すべてのクラスター ノードにローカルのレプリケートテーブルを作成します:
CREATE DATABASE IF NOT EXISTS nyc_taxi ON CLUSTER 'cluster_2S_2R';
CREATE TABLE nyc_taxi.trips_small_dist_local ON CLUSTER 'cluster_2S_2R'
(
trip_id UInt32,
pickup_datetime DateTime,
dropoff_datetime DateTime,
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count UInt8,
trip_distance Float32,
fare_amount Float32,
extra Float32,
tip_amount Float32,
tolls_amount Float32,
total_amount Float32,
payment_type Enum('CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4, 'UNK' = 5),
pickup_ntaname LowCardinality(String),
dropoff_ntaname LowCardinality(String)
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')
PRIMARY KEY (pickup_datetime, dropoff_datetime);
次に、その上に Distributed テーブルを作成します:
CREATE TABLE nyc_taxi.trips_small_dist ON CLUSTER 'cluster_2S_2R'
(
trip_id UInt32,
pickup_datetime DateTime,
dropoff_datetime DateTime,
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count UInt8,
trip_distance Float32,
fare_amount Float32,
extra Float32,
tip_amount Float32,
tolls_amount Float32,
total_amount Float32,
payment_type Enum('CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4, 'UNK' = 5),
pickup_ntaname LowCardinality(String),
dropoff_ntaname LowCardinality(String)
)
ENGINE = Distributed('cluster_2S_2R', 'nyc_taxi', 'trips_small_dist_local', rand());
分散テーブル経由でデータを挿入します:
INSERT INTO nyc_taxi.trips_small_dist
SELECT
trip_id,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
fare_amount,
extra,
tip_amount,
tolls_amount,
total_amount,
payment_type,
pickup_ntaname,
dropoff_ntaname
FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..2}.gz',
'TabSeparatedWithNames'
);
Cloud の準備
データは新しい Cloud サービスにリストアされます。
以下の手順に従って、新しい Cloud サービスを作成します。
サービスを設定して作成する
希望するリージョンと構成を選択し、Create service をクリックします。
アクセスロールを作成する
アクセスロールを作成する SQL コンソールを開きます。
S3 アクセスを設定する S3 からバックアップをリストアするには、ClickHouse Cloud と S3 バケット間の安全なアクセスを設定する必要があります。
"Accessing S3 data securely" の手順に従い、アクセスロールを作成してロール ARN を取得します。
"How to create an S3 bucket and IAM role" で作成した S3 バケットポリシーに、前の手順で取得したロール ARN を追加して更新します。
更新後の S3 バケットのポリシーは次のようになります。
{
"Version": "2012-10-17",
"Id": "Policy123456",
"Statement": [
{
"Sid": "abc123",
"Effect": "Allow",
"Principal": {
"AWS": [
#highlight-start
"arn:aws:iam::123456789123:role/ClickHouseAccess-001",
"arn:aws:iam::123456789123:user/docs-s3-user"
#highlight-end
]
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::ch-docs-s3-bucket",
"arn:aws:s3:::ch-docs-s3-bucket/*"
]
}
]
}
このポリシーには 2 つの ARN が含まれます:
IAM user (docs-s3-user):セルフマネージド ClickHouse クラスターが S3 にバックアップできるようにするものClickHouse Cloud role (ClickHouseAccess-001):Cloud サービスが S3 からリストアできるようにするもの バックアップの取得 (セルフマネージド環境のデプロイメント)
各分片はそれぞれ個別にバックアップする必要があります。各分片上のノードに接続し、
分片ごとに一意の宛先パスを指定してバックアップコマンドを実行します。
BUCKET_URL、KEY_ID、SECRET_KEY をご自身の AWS の認証情報に置き換えてください。
ガイド "S3 バケットと IAM ロールを作成する方法" では、まだお持ちでない場合にそれらを取得する方法を説明しています。
分片 1:
BACKUP DATABASE nyc_taxi
TO S3(
'BUCKET_URL/backup_s1.zip',
'KEY_ID',
'SECRET_KEY'
)
分片 2:
BACKUP DATABASE nyc_taxi
TO S3(
'BUCKET_URL/backup_s2.zip',
'KEY_ID',
'SECRET_KEY'
)
すべてが正しく設定されていれば、バックアップに割り当てられた一意の ID とバックアップのステータスを含む、以下に示すものと同様のレスポンスが表示されます。
Query id: efcaf053-75ed-4924-aeb1-525547ea8d45
┌─id───────────────────────────────────┬─status─────────┐
│ e73b99ab-f2a9-443a-80b4-533efe2d40b3 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
単一ノードのデプロイメント
分散テーブルを使用していない場合は、1 つのコマンドでデータベース全体をバックアップできます。
BACKUP DATABASE nyc_taxi
TO S3(
'BUCKET_URL',
'KEY_ID',
'SECRET_KEY'
)
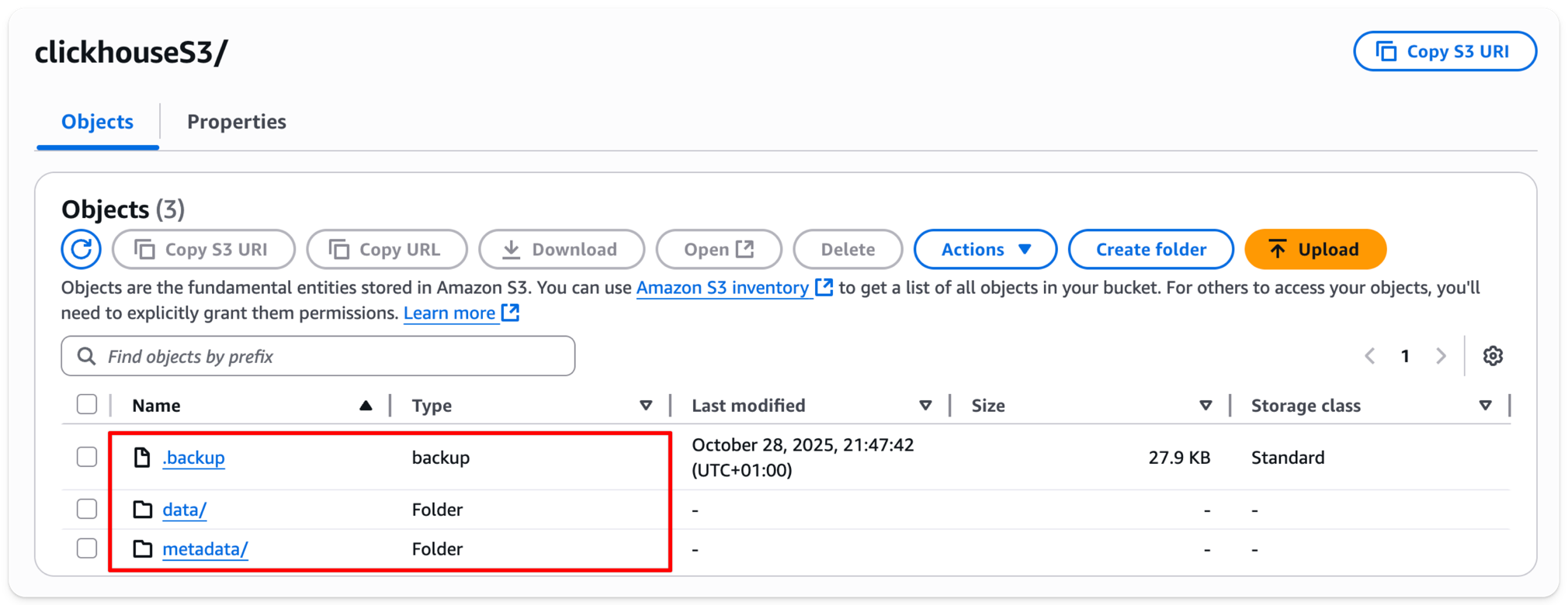
以前は空だった S3 バケットを確認すると、いくつかのフォルダーが表示されていることが確認できます。
完全なマイグレーションを実行している場合は、次のコマンドを実行してサーバー全体をバックアップできます。
BACKUP
TABLE system.users,
TABLE system.roles,
TABLE system.settings_profiles,
TABLE system.row_policies,
TABLE system.quotas,
TABLE system.functions,
ALL EXCEPT DATABASES INFORMATION_SCHEMA, information_schema, system
TO S3(
'BUCKET_ID',
'KEY_ID',
'SECRET_ID'
)
SETTINGS
compression_method='lzma',
compression_level=3;
上記のコマンドは次の内容をバックアップします:
すべてのユーザーデータベースとテーブル
ユーザーアカウントとパスワード
ロールと権限
設定プロファイル
行ポリシー
クォータ
ユーザー定義関数
別の Cloud Service Provider (CSP) を使用している場合は、TO S3() (AWS および GCP の両方に対応) や TO AzureBlobStorage() 構文を使用できます。
非常に大きなデータベースの場合は、ASYNC を使用してバックアップをバックグラウンドで非同期に実行することを検討してください:
BACKUP DATABASE my_database
TO S3('https://your-bucket.s3.amazonaws.com/backup.zip', 'key', 'secret')
ASYNC;
-- Returns immediately with backup ID
-- Example result:
-- ┌─id──────────────────────────────────┬─status────────────┐
-- │ abc123-def456-789 │ CREATING_BACKUP │
-- └─────────────────────────────────────┴───────────────────┘
その後、このバックアップ ID を使用してバックアップの進行状況を監視できます。
SELECT *
FROM system.backups
WHERE id = 'abc123-def456-789'
増分バックアップを作成することも可能です。
バックアップ全般の詳細については、backup and restore ドキュメントを参照してください。
ClickHouse Cloud への復元
各分片のバックアップを 1 つずつ Cloud サービス に復元します。ROLE_ARN は
"Accessing S3 data securely" で取得した値に設定してください。
2 回目以降の復元では SETTINGS allow_non_empty_tables=true を使用して、
競合による失敗を避け、分片のデータをすでに復元済みのテーブルに追記します。
分片 1:
RESTORE DATABASE nyc_taxi
FROM S3(
'BUCKET_URL/backup_s1.zip',
extra_credentials(role_arn = 'ROLE_ARN')
)
分片 2:
RESTORE DATABASE nyc_taxi
FROM S3(
'BUCKET_URL/backup_s2.zip',
extra_credentials(role_arn = 'ROLE_ARN')
)
SETTINGS allow_non_empty_tables=true;
非分散デプロイメント
分散テーブルを使用していない場合は、1つのコマンドでデータベースを復元します。
RESTORE DATABASE nyc_taxi
FROM S3(
'BUCKET_URL',
extra_credentials(role_arn = 'ROLE_ARN')
)
同様の方法で、サービス全体を復元できます。
RESTORE
TABLE system.users,
TABLE system.roles,
TABLE system.settings_profiles,
TABLE system.row_policies,
TABLE system.quotas,
ALL EXCEPT DATABASES INFORMATION_SCHEMA, information_schema, system
FROM S3(
'BUCKET_URL',
extra_credentials(role_arn = 'ROLE_ARN')
)
復元が完了したら、データがCloudで利用可能になっていることを確認できます。
-- ClickHouse Cloud restores everything in your local table
SELECT count() from nyc_taxi.trips_small_dist_local;
3000317
ClickHouse Cloud は内部で SharedMergeTree を使用しているため、従来の分散テーブルは不要です。これを削除し、クエリで元のテーブル名をそのまま使えるようにするビューに置き換えることができます。
DROP TABLE drop table nyc_taxi.trips_small_dist;
CREATE VIEW nyc_taxi.trips_small_dist AS SELECT * FROM nyc_taxi.trips_small_dist_local;
SELECT count() from nyc_taxi.trips_small_dist;
3000317
分散されていない ReplicatedMergeTree テーブルは、SharedMergeTree として復元されます:
SELECT count() FROM nyc_taxi.trips_small_adapted;
3000317