PeerDB を使用して Managed Postgres に移行する
このガイドでは、PeerDB を使用して PostgreSQL データベースを ClickHouse Managed Postgres に移行する手順を、ステップごとに説明します。
Beta前提条件
- 移行元となる PostgreSQL データベースへのアクセス権限。
- データを移行先とする ClickHouse Managed Postgres インスタンス。
- PeerDB がインストールされているマシン。インストール手順については PeerDB GitHub リポジトリ を参照してください。リポジトリをクローンして
docker-compose upを実行するだけです。このガイドでは PeerDB UI を使用します。PeerDB が起動すると、http://localhost:3000でアクセス可能になります。
移行前の考慮事項
移行を開始する前に、以下の点を確認してください。
- データベースオブジェクト: PeerDB はソーススキーマに基づき、ターゲットデータベースにテーブルを自動作成します。ただし、索引、制約、トリガーなど一部のデータベースオブジェクトは自動的には移行されません。移行後に、これらのオブジェクトをターゲットデータベース上で手動で再作成する必要があります。
- DDL の変更: 継続的レプリケーションを有効にした場合、PeerDB は DML 操作(INSERT、UPDATE、DELETE)についてソースとターゲットのデータベースを同期し、ADD COLUMN 操作を伝播します。ただし、その他の DDL 変更(DROP COLUMN、ALTER COLUMN など)は自動的には伝播されません。スキーマ変更のサポートについての詳細はこちらを参照してください。
- ネットワーク接続性: PeerDB を実行しているマシンから、ソースおよびターゲットの両方のデータベースへアクセス可能であることを確認してください。接続を許可するために、ファイアウォールルールやセキュリティグループの設定を変更する必要がある場合があります。
ピアを作成する
まず、ソースデータベースとターゲットデータベースそれぞれについてピアを作成する必要があります。ピアはデータベースへの接続を表します。PeerDB の UI で、サイドバーの「Peers」をクリックして「Peers」セクションを開きます。新しいピアを作成するには、+ New peer ボタンをクリックします。
ソース側ピアの作成
ホスト、ポート、データベース名、ユーザー名、パスワードなどの接続情報を入力して、ソース PostgreSQL データベース用のピアを作成します。すべて入力したら、Create peer ボタンをクリックしてピアを保存します。
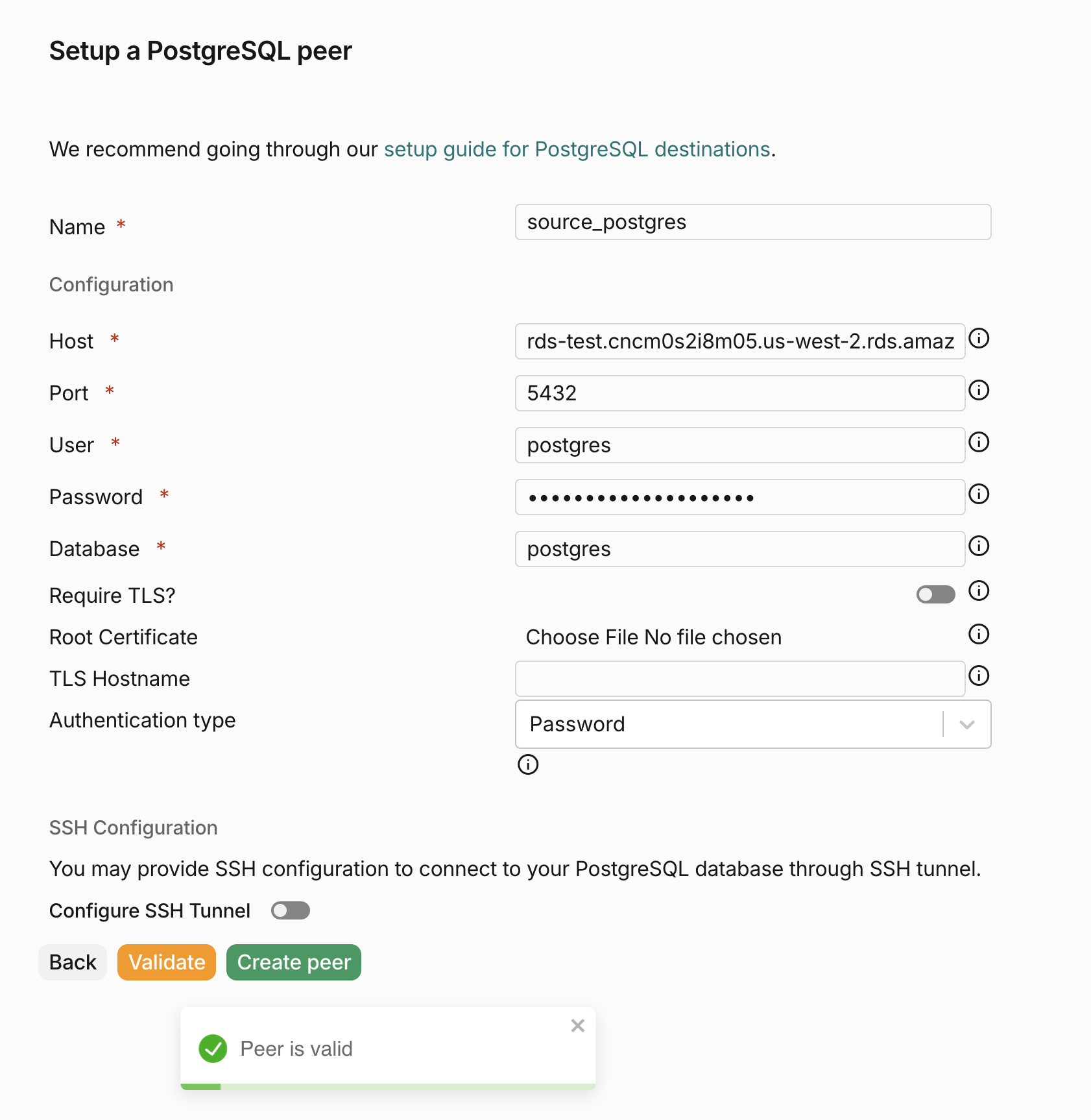
ターゲットピアの作成
同様に、必要な接続情報を入力して、ClickHouse Managed Postgres インスタンス用のピアを作成します。インスタンスの接続情報は、ClickHouse Cloud コンソールから取得できます。情報を入力したら、Create peer ボタンをクリックしてターゲットピアを作成します。
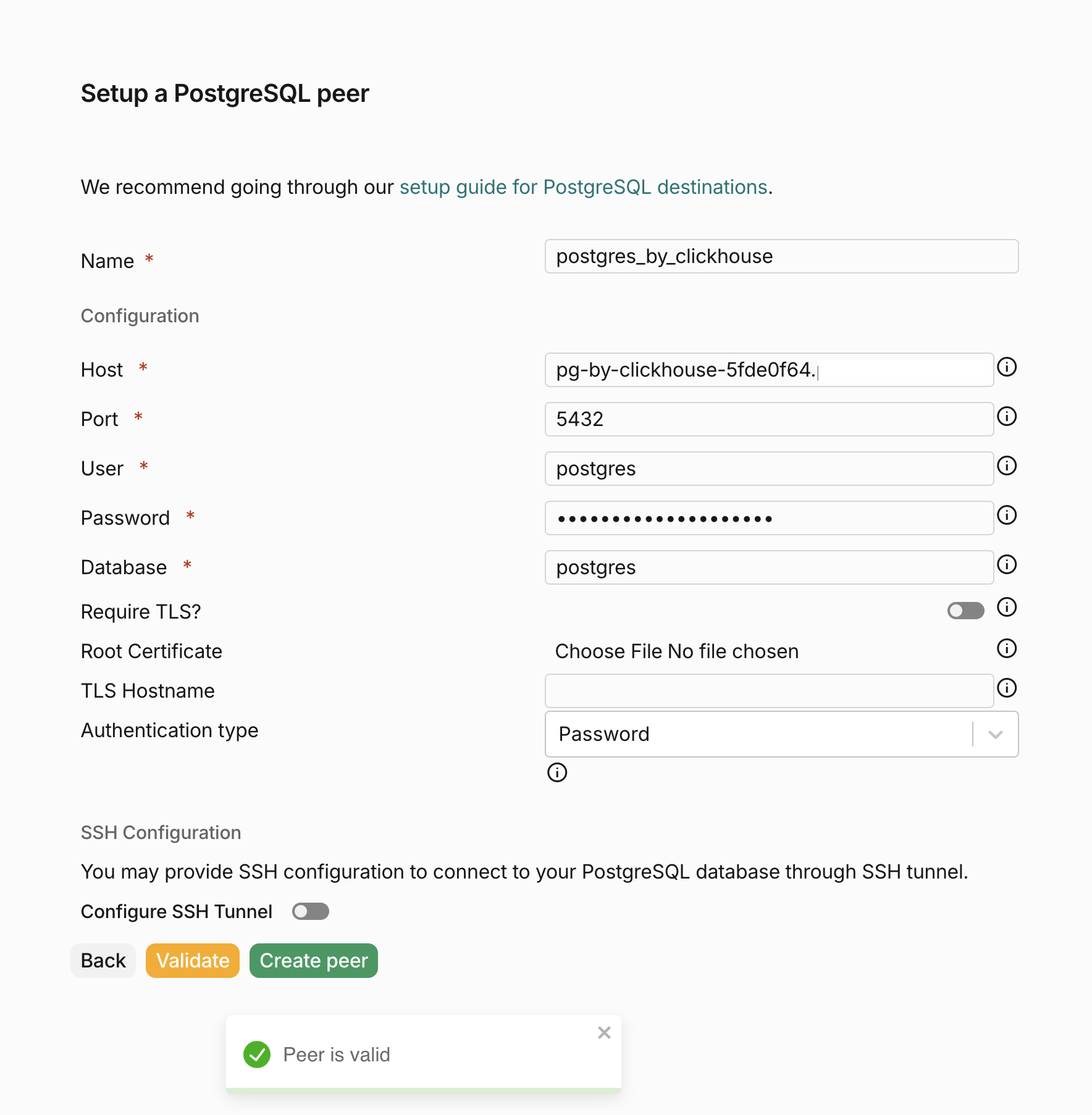
これで、「Peers」セクションにソースピアとターゲットピアの両方が表示されているはずです。
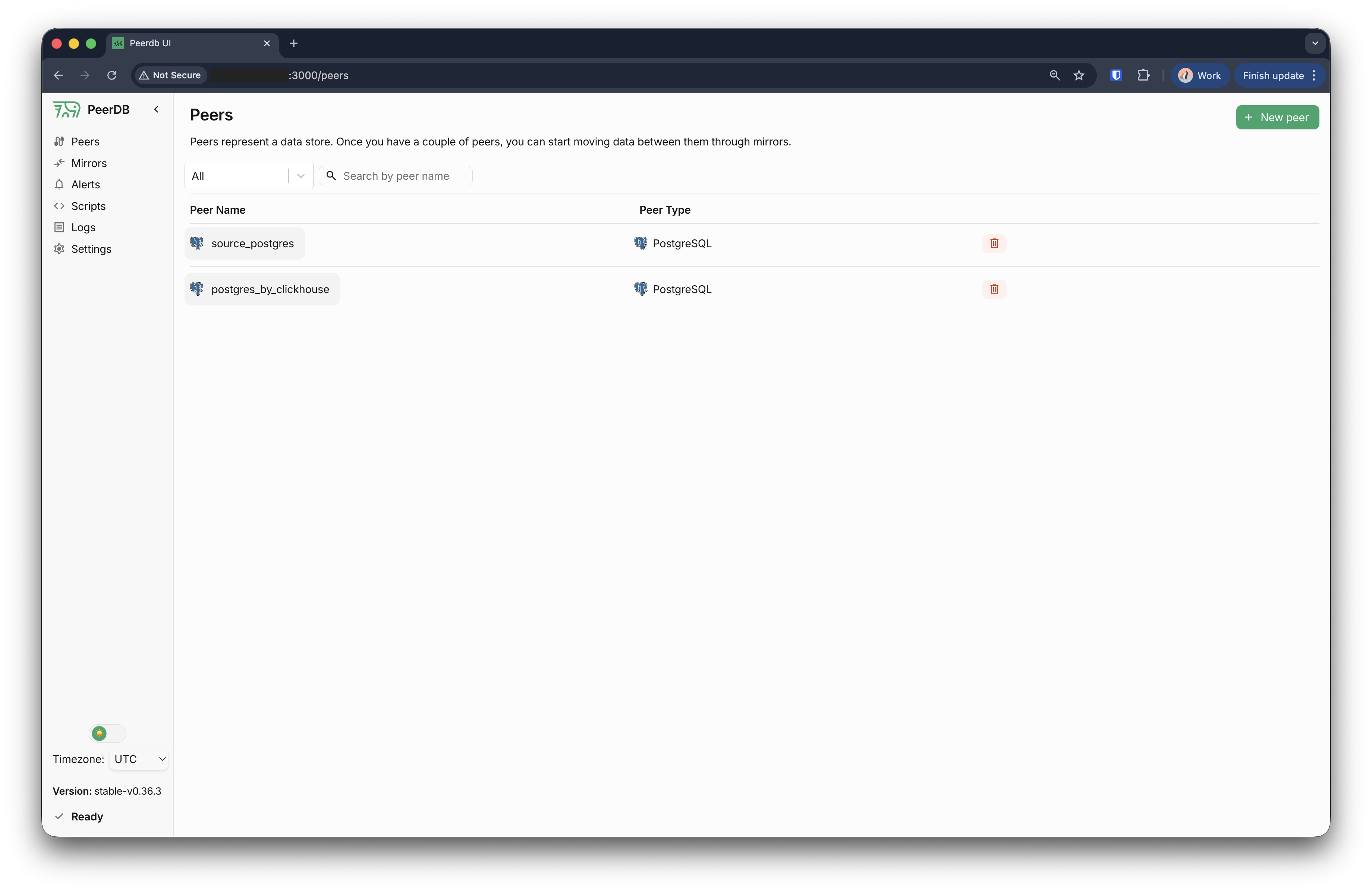
ソーススキーマダンプの取得
ターゲットデータベースでソースデータベースと同一のスキーマ構成を再現するために、ソースデータベースのスキーマダンプを取得する必要があります。ソースの PostgreSQL データベースについてスキーマのみのダンプを作成するには、pg_dump を使用できます。
pg_dump のインストール
Ubuntu:
パッケージリストを更新します。
PostgreSQL クライアントをインストールします。
macOS:
方法 1: Homebrew を使用する (推奨)
Homebrew がインストールされていない場合はインストールします。
PostgreSQL をインストールします。
インストールを確認します。
スキーマダンプから UNIQUE 制約と索引を削除する
これをターゲットデータベースに適用する前に、ダンプファイルから UNIQUE 制約と索引を事前に削除しておく必要があります。そうしないと、これらの制約によって PeerDB によるターゲットテーブルへのインジェストがブロックされてしまいます。これらは次のコマンドで削除できます。
スキーマダンプをターゲットデータベースに適用する
スキーマダンプファイルをクリーンアップしたら、psql で接続し、スキーマダンプファイルを実行してターゲットの ClickHouse Managed Postgres データベースに適用します。
ここではターゲット側で、外部キー制約によって PeerDB へのインジェストがブロックされないようにします。そのために、上記のターゲットピアで使用したターゲットロールを変更し、session_replication_role を replica に設定します:
ミラーを作成する
次に、ソースとターゲットのピア間でのデータ移行プロセスを定義するミラーを作成します。PeerDB の UI でサイドバーの「Mirrors」をクリックして、「Mirrors」セクションに移動します。新しいミラーを作成するには、+ New mirror ボタンをクリックします。
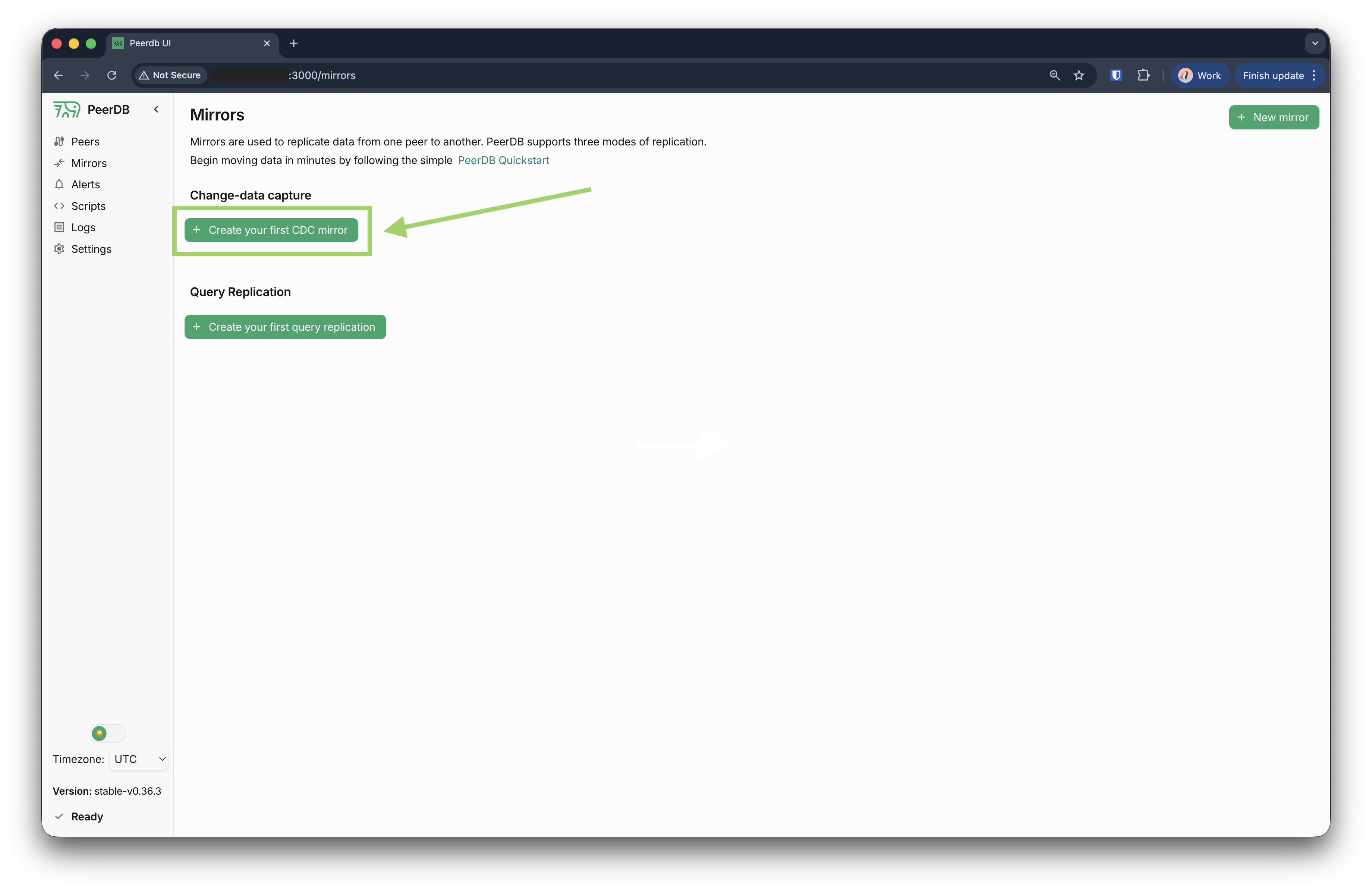
- 移行内容がわかる名前をミラーに付けます。
- ドロップダウンメニューから、先ほど作成したソースとターゲットのピアを選択します。
- 次の点を確認します:
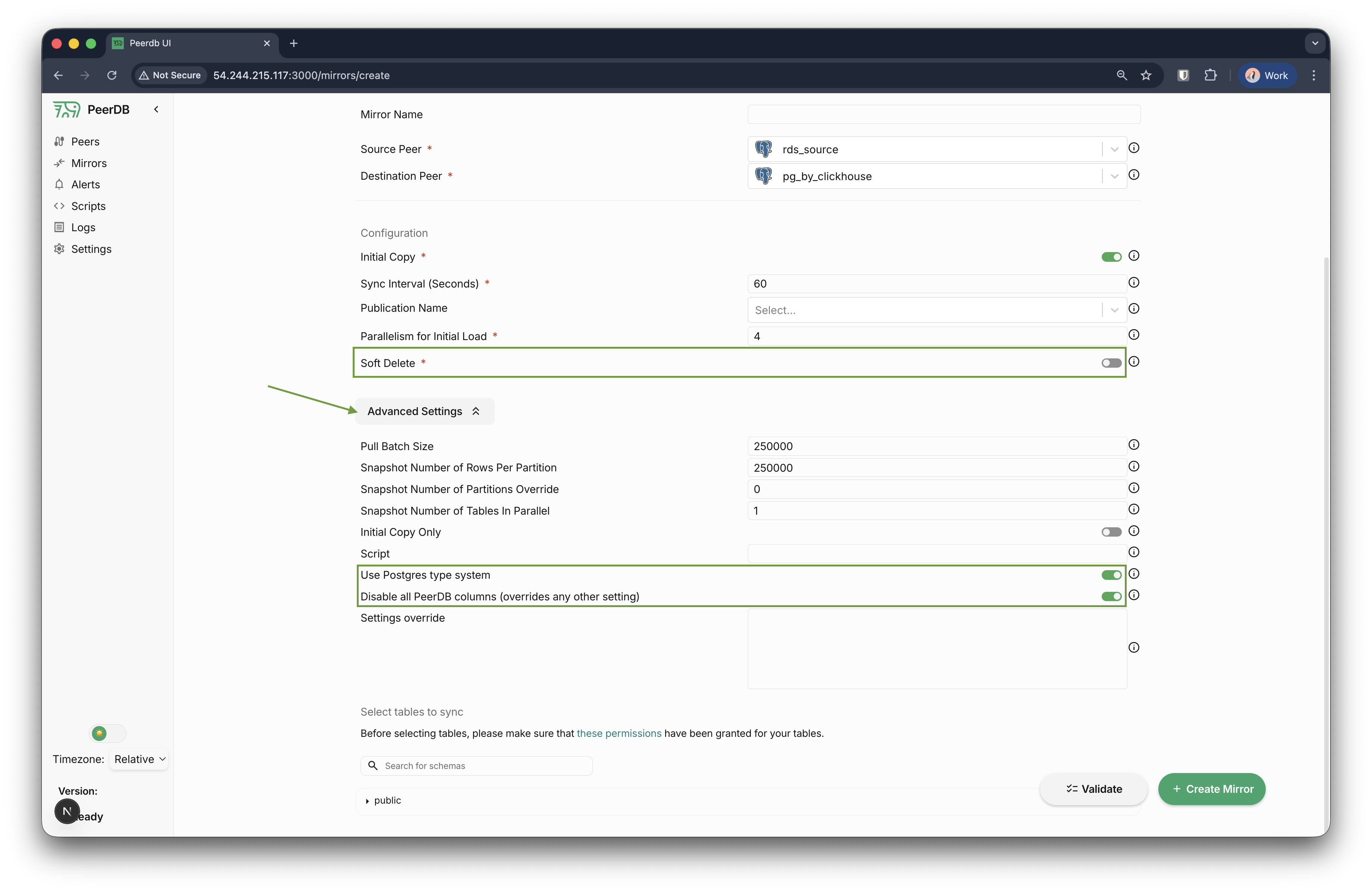
- Soft delete が OFF になっていること。
Advanced settingsを展開します。Postgres type system is enabled が有効になっており、PeerDB columns are disabled が無効になっていることを確認します。
- 移行したいテーブルを選択します。特定のテーブルだけを選択することも、ソースデータベース内のすべてのテーブルを選択することもできます。
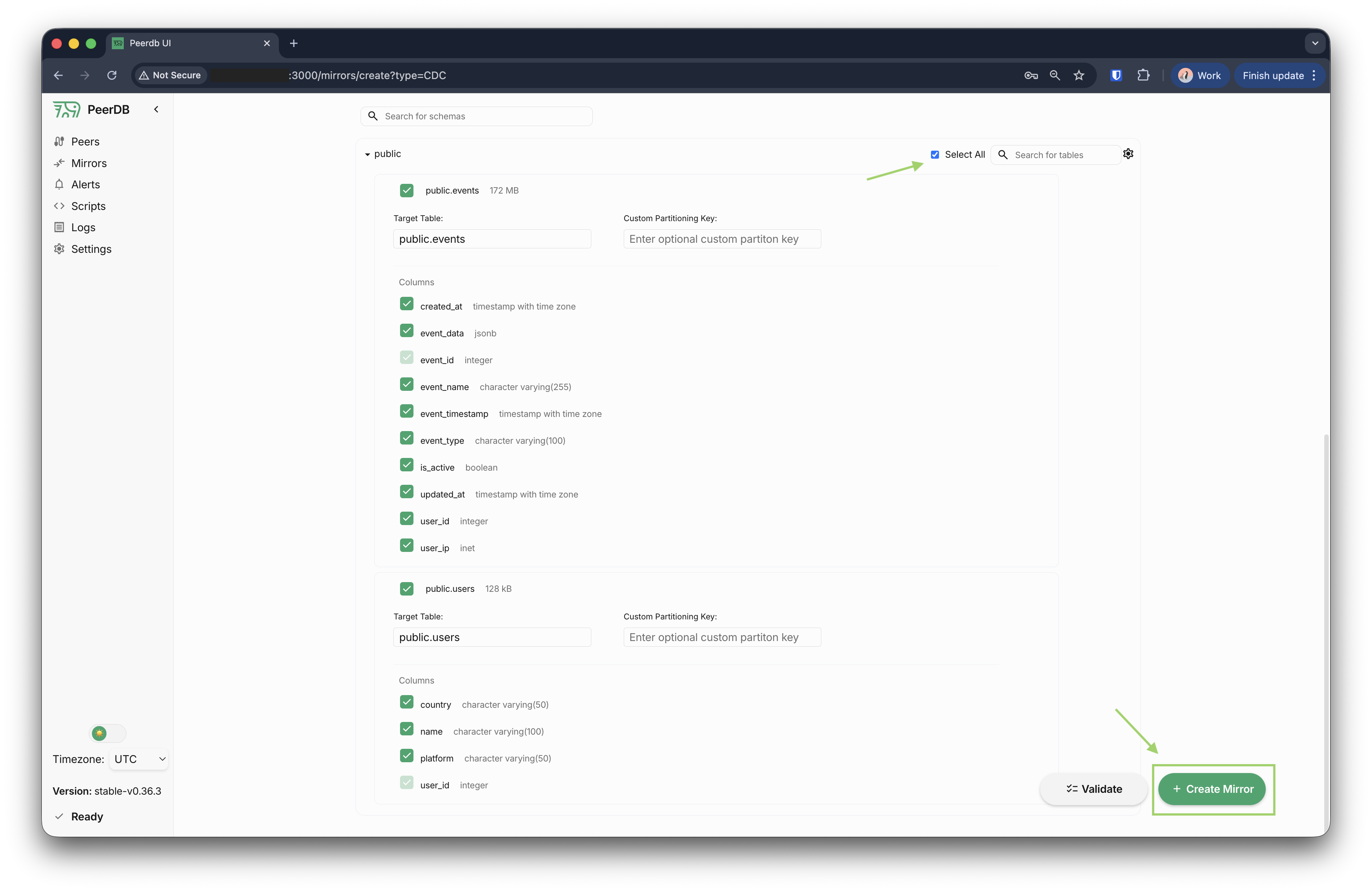
前のステップでスキーマをそのまま移行しているため、ターゲットデータベース内で、宛先テーブル名がソーステーブル名と同一であることを確認してください。
- ミラー設定の構成が完了したら、
Create mirrorボタンをクリックします。
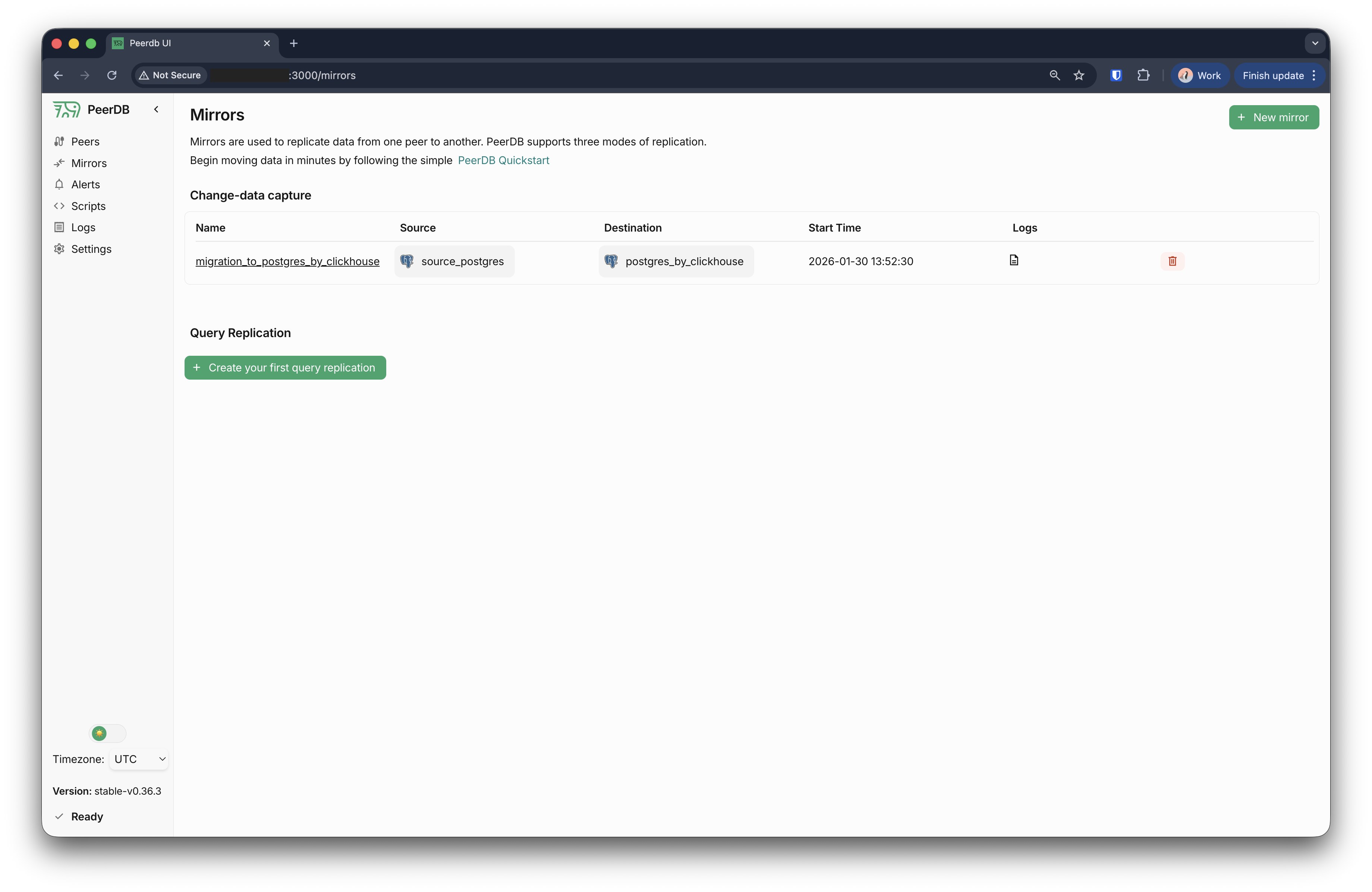
「Mirrors」セクションに、作成したばかりのミラーが表示されるはずです。
初回ロードの完了を待つ
ミラーを作成すると、PeerDB はソースからターゲットデータベースへの初回データロードを開始します。ミラーをクリックし、Initial load タブを開くと、初回データ移行の進行状況を確認できます。
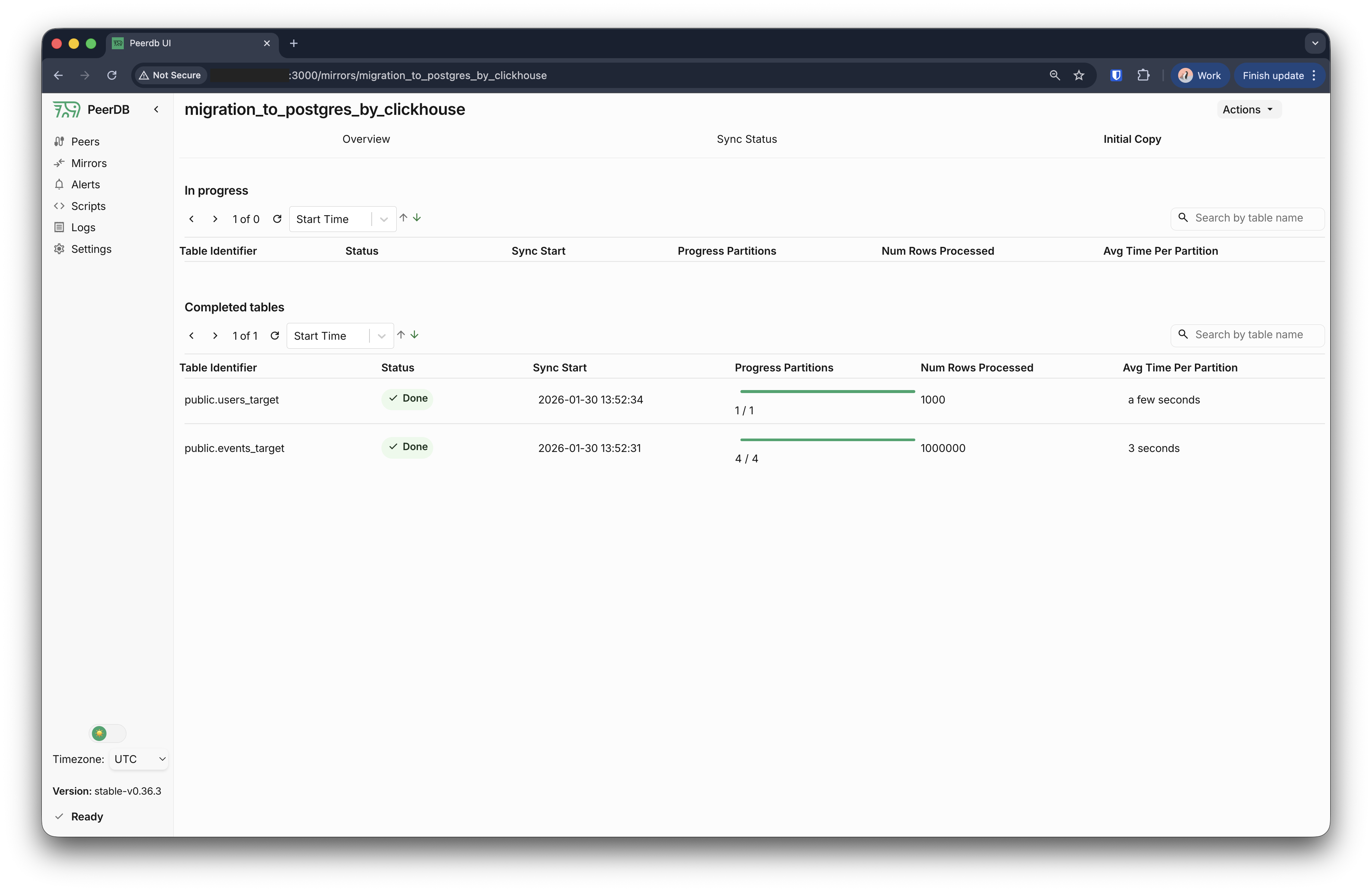
初回ロードが完了すると、移行が完了したことを示すステータスが表示されます。
初期ロードとレプリケーションの監視
ソースの peer をクリックすると、PeerDB が実行中のコマンド一覧を確認できます。例えば、次のようなものがあります。
- まず、各テーブル内の行数を見積もるために COUNT クエリを実行します。
- 次に、NTILE を使用したパーティション分割クエリを実行し、大きなテーブルをより小さな chunk に分割して、データ転送を効率化します。
- その後、FETCH コマンドを実行してソースデータベースからデータを取得し、PeerDB がそれらをターゲットデータベースに同期します。
移行後のタスク
これらの手順は、具体的なユースケースやアプリケーションの要件に応じて異なる場合があります。重要なのは、新しいシステムへ完全に切り替える前に、データの一貫性を確保し、ダウンタイムを最小限に抑え、移行後のデータの整合性を検証することです。
移行が完了したら:
- カットオーバー前の検証チェックを実施する
トラフィックを切り替える前に、ソースとターゲットの主要なテーブルを比較します:
- ソースシステムへの書き込みを停止する
まず、アプリケーションからの書き込みを一時停止します。追加の安全策として、カットオーバー中はソースデータベースを読み取り専用に設定します。
ロールバックが必要な場合は、書き込みを再び有効にできます。
- レプリケーションが完全に追いついていることを確認する
1 つ以上の書き込み量の多いテーブルで、最新の行がソースとターゲットで一致していることを確認します:
- 制約、索引、トリガーを再作成して有効にする
インジェストのために制約や索引を削除した、または適用を後回しにしていた場合は、ここで再適用します。また、以前に replica に設定していた場合は、ターゲット側のレプリケーションロールもリセットします。
- 移行先テーブルのシーケンスをリセットする
データのロード後、テーブル内の現在の値に合わせてシーケンスを調整します:
- アプリケーショントラフィックを切り替える
検証が完了し、シーケンスと制約が整ったら:
- 読み取りトラフィックの向き先を ClickHouse Managed Postgres に切り替えます。
- 書き込みトラフィックの向き先を ClickHouse Managed Postgres に切り替えます。
- アプリケーションエラー、制約違反、データベースの健全性を監視します。
- リソースをクリーンアップする
移行に問題がないことを確認し、アプリケーションが ClickHouse Managed Postgres を使用するように切り替えたら、PeerDB のミラーとピアを削除できます。
継続的レプリケーションを有効にした場合、PeerDB はソース PostgreSQL データベース上に レプリケーションスロット を作成します。不要なリソース消費を避けるため、移行完了後にソースデータベースからレプリケーションスロットを手動で削除してください。
参考資料
次のステップ
おめでとうございます!pg_dump と pg_restore を使用して、PostgreSQL データベースを ClickHouse Managed Postgres に正常に移行できました。これで Managed Postgres の各種機能や ClickHouse との連携を試す準備が整いました。スムーズに始められるよう、10 分で完了するクイックスタートを用意しています:
