Part merges
What are part merges in ClickHouse?
ClickHouse is fast not just for queries but also for inserts, thanks to its storage layer, which operates similarly to LSM trees:
① Inserts (into tables from the MergeTree engine family) create sorted, immutable data parts.
② All data processing is offloaded to background part merges.
This makes data writes lightweight and highly efficient.
To control the number of parts per table and implement ② above, ClickHouse continuously merges (per partition) smaller parts into larger ones in the background until they reach a compressed size of approximately ~150 GB.
The following diagram sketches this background merge process:

The merge level of a part is incremented by one with each additional merge. A level of 0 means the part is new and hasn't been merged yet. Parts that were merged into larger parts are marked as inactive and finally deleted after a configurable time (8 minutes by default). Over time, this creates a tree of merged parts. Hence the name merge tree table.
Monitoring merges
In the what are table parts example, we showed that ClickHouse tracks all table parts in the parts system table. We used the following query to retrieve the merge level and the number of stored rows per active part of the example table:
The previously documented query result shows that the example table had four active parts, each created from a single merge of the initially inserted parts:
Running the query now shows that the four parts have since merged into a single final part (as long as there are no further inserts into the table):
In ClickHouse 24.10, a new merges dashboard was added to the built-in monitoring dashboards. Available in both OSS and Cloud via the /merges HTTP handler, we can use it to visualize all part merges for our example table:
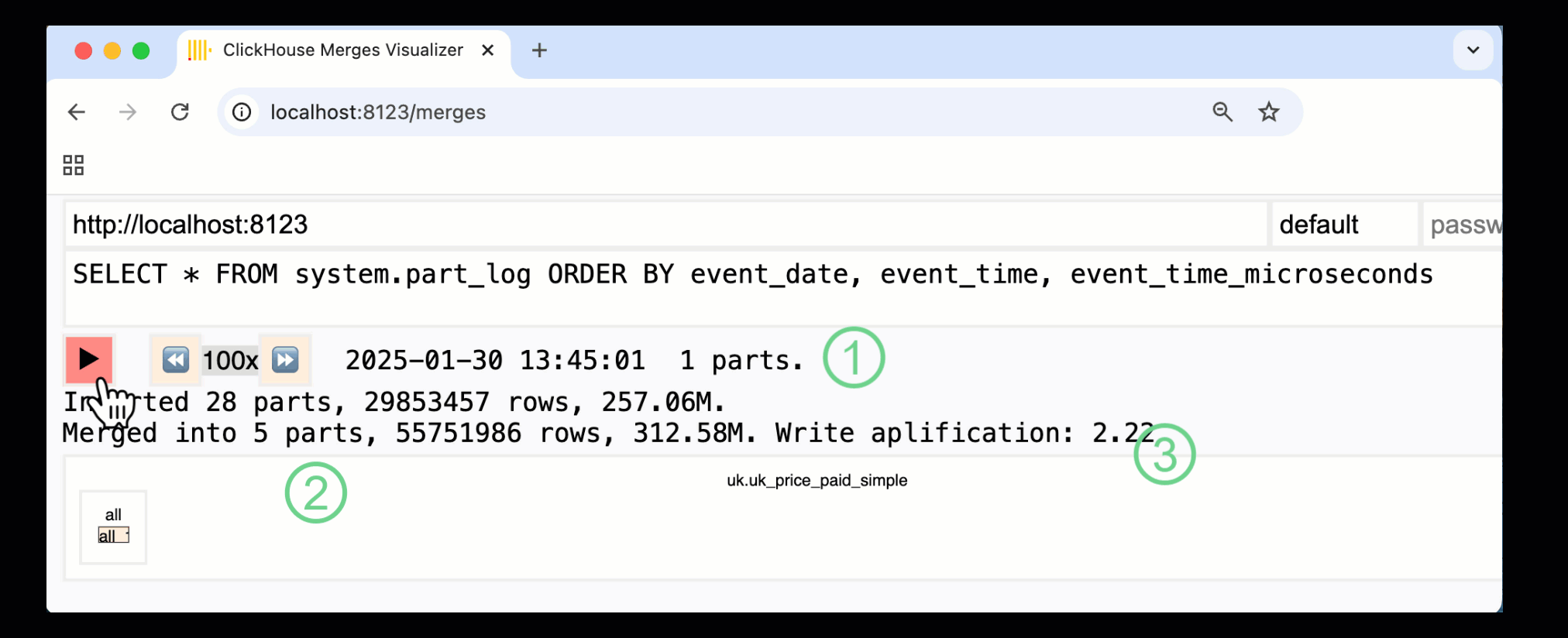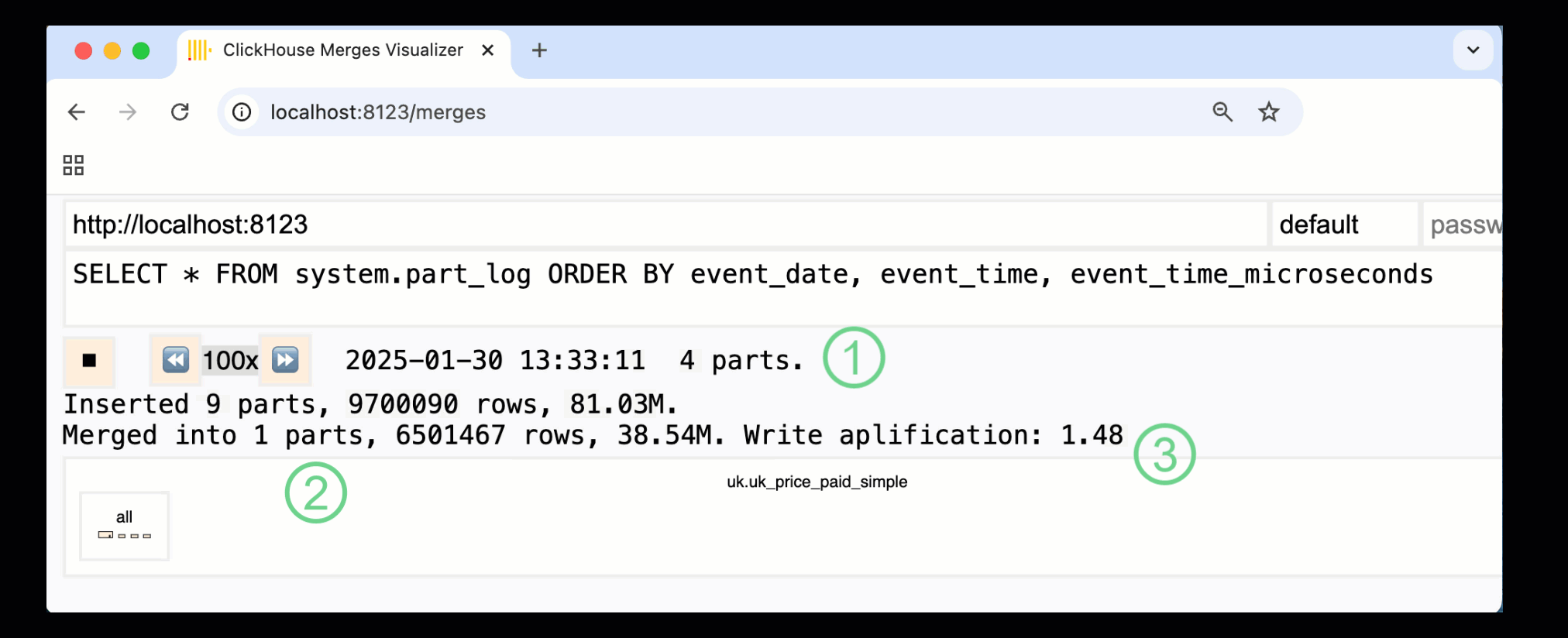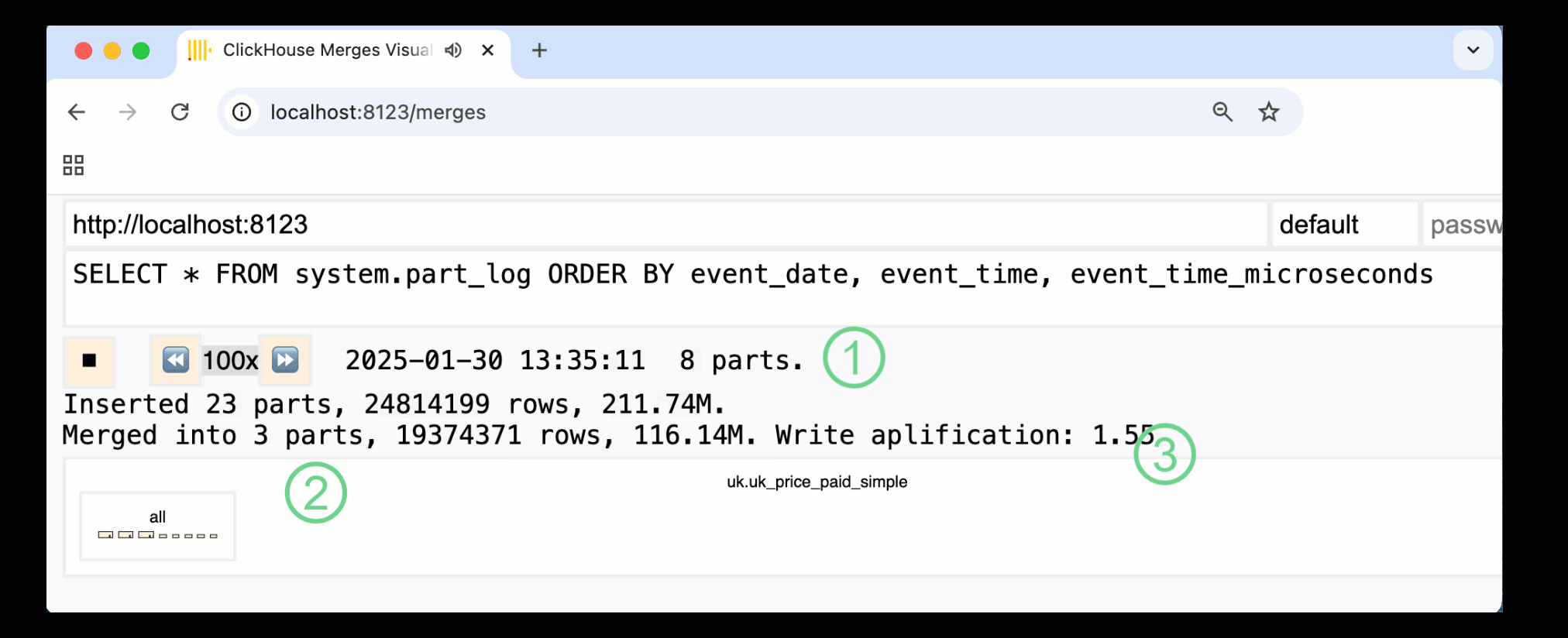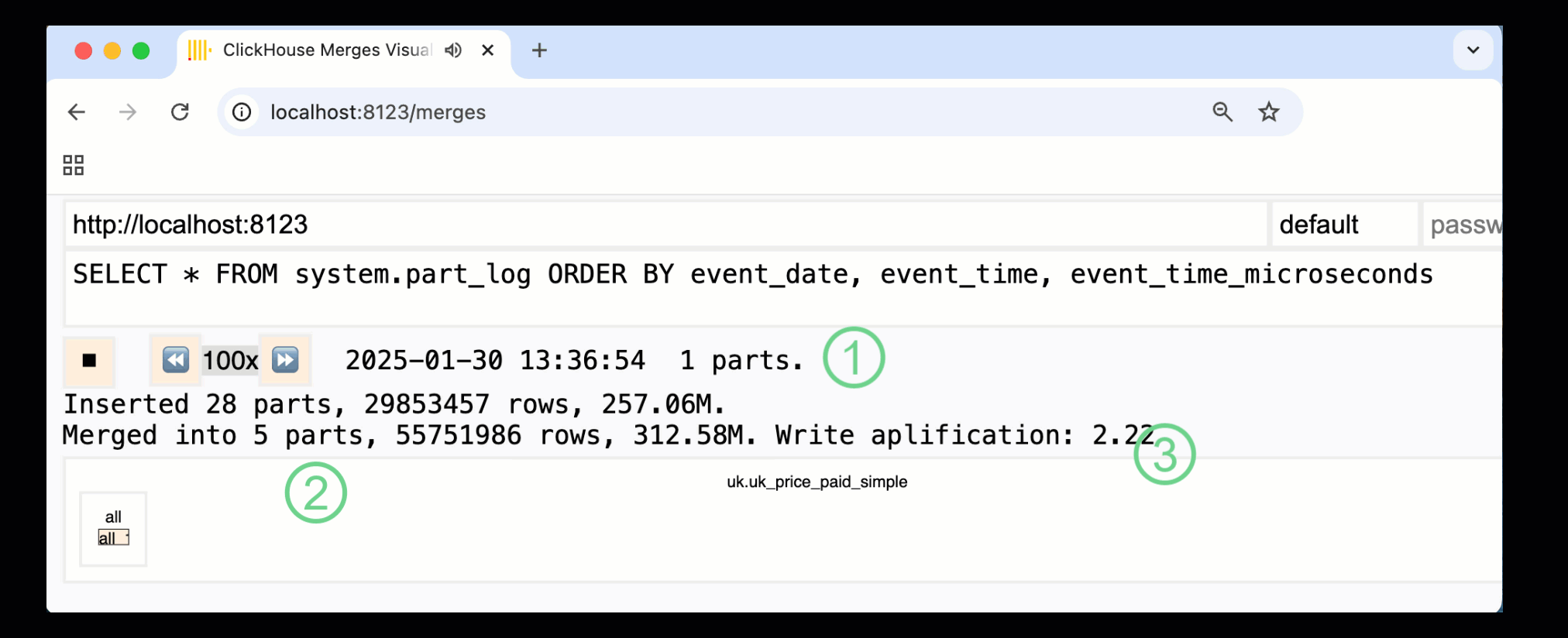
The recorded dashboard above captures the entire process, from the initial data inserts to the final merge into a single part:
① Number of active parts.
② Part merges, visually represented with boxes (size reflects part size).
Concurrent merges
A single ClickHouse server uses several background merge threads to execute concurrent part merges:

Each merge thread executes a loop:
① Decide which parts to merge next, and load these parts into memory.
② Merge the parts in memory into a larger part.
③ Write the merged part to disk.
Go to ①
Note that increasing the number of CPU cores and the size of RAM allows to increase the background merge throughput.
Memory optimized merges
ClickHouse doesn't necessarily load all parts to be merged into memory at once, as sketched in the previous example. Based on several factors, and to reduce memory consumption (sacrificing merge speed), so-called vertical merging loads and merges parts by chunks of blocks instead of in one go.
Merge mechanics
The diagram below illustrates how a single background merge thread in ClickHouse merges parts (by default, without vertical merging):

The part merging is performed in several steps:
① Decompression & Loading: The compressed binary column files from the parts to be merged are decompressed and loaded into memory.
② Merging: The data is merged into larger column files.
③ Indexing: A new sparse primary index is generated for the merged column files.
④ Compression & Storage: The new column files and index are compressed and saved in a new directory representing the merged data part.
Additional metadata in data parts, such as secondary data skipping indexes, column statistics, checksums, and min-max indexes, is also recreated based on the merged column files. We omitted these details for simplicity.
The mechanics of step ② depend on the specific MergeTree engine used, as different engines handle merging differently. For example, rows may be aggregated or replaced if outdated. As mentioned earlier, this approach offloads all data processing to background merges, enabling super-fast inserts by keeping write operations lightweight and efficient.
Next, we will briefly outline the merge mechanics of specific engines in the MergeTree family.
Standard merges
The diagram below illustrates how parts in a standard MergeTree table are merged:

The DDL statement in the diagram above creates a MergeTree table with a sorting key (town, street), meaning data on disk is sorted by these columns, and a sparse primary index is generated accordingly.
The ① decompressed, pre-sorted table columns are ② merged while preserving the table's global sorting order defined by the table's sorting key, ③ a new sparse primary index is generated, and ④ the merged column files and index are compressed and stored as a new data part on disk.
Replacing merges
Part merges in a ReplacingMergeTree table work similarly to standard merges, but only the most recent version of each row is retained, with older versions being discarded:

The DDL statement in the diagram above creates a ReplacingMergeTree table with a sorting key (town, street, id), meaning data on disk is sorted by these columns, with a sparse primary index generated accordingly.
The ② merging works similarly to a standard MergeTree table, combining decompressed, pre-sorted columns while preserving the global sorting order.
However, the ReplacingMergeTree removes duplicate rows with the same sorting key, keeping only the most recent row based on the creation timestamp of its containing part.
Summing merges
Numeric data is automatically summarized during merges of parts from a SummingMergeTree table:

The DDL statement in the diagram above defines a SummingMergeTree table with town as the sorting key, meaning that data on disk is sorted by this column and a sparse primary index is created accordingly.
In the ② merging step, ClickHouse replaces all rows with the same sorting key with a single row, summing the values of numeric columns.
Aggregating merges
The SummingMergeTree table example from above is a specialized variant of the AggregatingMergeTree table, allowing automatic incremental data transformation by applying any of 90+ aggregation functions during part merges:

The DDL statement in the diagram above creates an AggregatingMergeTree table with town as the sorting key, ensuring data is ordered by this column on disk and a corresponding sparse primary index is generated.
During ② merging, ClickHouse replaces all rows with the same sorting key with a single row storing partial aggregation states (e.g. a sum and a count for avg()). These states ensure accurate results through incremental background merges.
